44-PageHelper 注意点
1. 插件#
org.apache.ibatis.session.Configuration (MyBatis 的这四大组件创建过程中,都有插件进行介入):
插件可以利用动态代理机制一层层的包装目标对象,而实现目标对象执行目标方法之前进行拦截效果。MyBatis 允许在已映射语句执行过程中的某一点进行拦截调用。
public class Configuration {
// 创建的时候不是直接返回的,要经过插件的层层包装
public Xxx newXxx(...) {
Xxx xxx = new Xxx(...);
xxx = (Xxx) interceptorChain.pluginAll(xxx);
}
}
·················································
public class InterceptorChain {
public Object pluginAll(Object target) {
for (Interceptor interceptor : interceptors) {
// [插件机制] 用插件为 target(四大对象) 创建代理对象
target = interceptor.plugin(target);
}
return target;
}
}
默认情况下,MyBatis 允许插件来拦截的方法调用包括:
[Executor] update, query, flushStatements, commit, rollback, getTransaction, close, isClosed
[ParameterHandler] getParameterObject, setParameters
[ResultSetHandler] handleResultSets, handleOutputParameters
[StatementHandler] prepare, parameterize, batch, update, query
自定义插件:
/** (1) 需要实现 Interceptor 接口 */
public interface Interceptor {
// 拦截目标对象的目标方法的执行
Object intercept(Invocation invocation) throws Throwable;
// 包装目标对象。包装:为目标对象创建代理对象
Object plugin(Object target);
// 将插件注册时的 <property> 属性设置进来
void setProperties(Properties properties);
}
/** (2) 插件签名 */
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Intercepts {
Signature[] value();
}
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Signature {
// 要拦截四大对象的哪一个
Class<?> type();
// 拦截哪个方法
String method();
// 方法的参数列表(有的方法可能会有方法重载)
Class<?>[] args();
}
/** (3) 注册插件 SqlSessionFactoryBean#setPlugins 略... */
2. 示例#
大数据表下的分页查询,应该怎么做?
现提供一个常用的查询优化思路:
- 根据查询条件先查询出所有符合条件的表记录的主键;
- 再根据这些主键去查询具体的数据记录;
但这个过程需要注意的一点是,为了最终能够保留查询的分页信息,必须要用 [1] 返回的 List 对象去承载 [2] 的返回结果,并作为 return 返回到 Controller 层。
先看下如果不这样做,[1] 和 [2] 各自持有一个 List,并将 [2] 的 List 作为 return 返回会怎样:
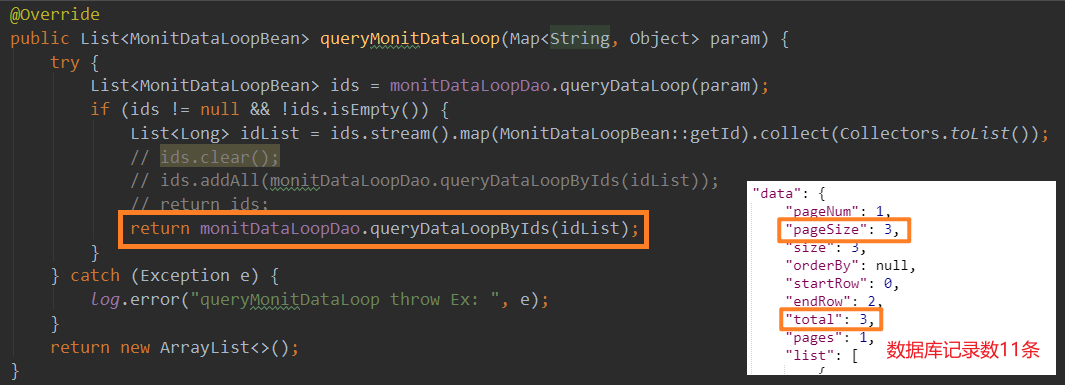
返回的 total 总记录数为当前 retList#size。
正确做法:
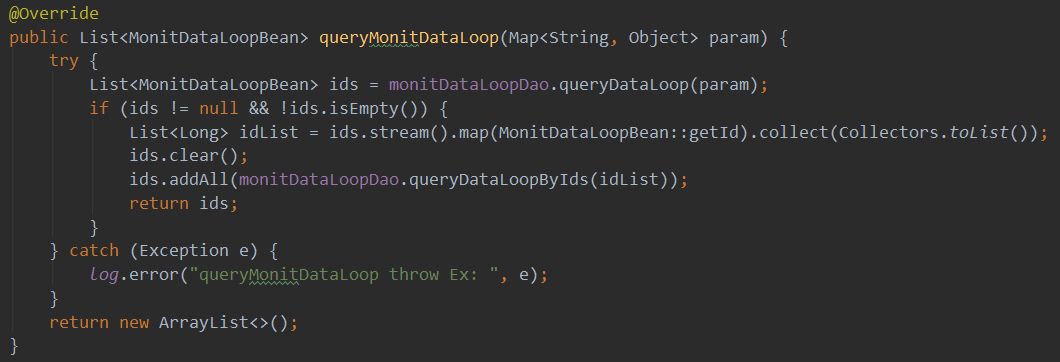
3. 原因#
看下分页查询模板三步分别会做什么事:
[1] PageHelper.startPage(pageNum, pageSize);
[2] List<MonitDataLoopBean> list = monitDataLoopService.queryMonitDataLoop(param);
[3] PageInfo<MonitDataLoopBean> pageInfo = new PageInfo<>(list);
- step1#
private static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();
method: startPage {
Page<E> page = new Page<E>(pageNum, pageSize, count);
// ...
LOCAL_PAGE.set(page);
// ...
}
- step2#
/**
* Mybatis拦截器方法
*
* @param invocation 拦截器入参
* @return 返回执行结果
* @throws Throwable 抛出异常
*/
private Page doProcessPage(Invocation invocation, Page page, Object[] args) throws Throwable {
//保存RowBounds状态
RowBounds rowBounds = (RowBounds) args[2];
//获取原始的MS
MappedStatement ms = (MappedStatement) args[0];
//判断并处理为PageSqlSource
if (!isPageSqlSource(ms)) {
// === Step Into ===> [见下图]
processMappedStatement(ms);
}
// 上面这个方法调用完成后,sqlId 和 MS 的对应关系就由原来的
// <"queryDataLoop", MS{"queryDataLoop"}> 变为 <"queryDataLoop", MS{"queryDataLoop_COUNT"}>
//设置当前的parser,后面每次使用前都会set,ThreadLocal的值不会产生不良影响
((PageSqlSource)ms.getSqlSource()).setParser(parser);
try {
//忽略RowBounds-否则会进行Mybatis自带的内存分页
args[2] = RowBounds.DEFAULT;
//如果只进行排序 或 pageSizeZero的判断
if (isQueryOnly(page)) {
return doQueryOnly(page, invocation);
}
//简单的通过total的值来判断是否进行count查询
if (page.isCount()) {
page.setCountSignal(Boolean.TRUE);
//替换 MS,此时这个 MS 是 "queryDataLoop_COUNT"
args[0] = msCountMap.get(ms.getId());
//查询总数
Object result = invocation.proceed();
//还原 MS
args[0] = ms;
//设置总数
page.setTotal((Integer) ((List) result).get(0));
if (page.getTotal() == 0) {
return page;
}
} else {
page.setTotal(-1l);
}
//pageSize>0的时候执行分页查询,pageSize<=0的时候不执行相当于可能只返回了一个count
if (page.getPageSize() > 0 &&
((rowBounds == RowBounds.DEFAULT && page.getPageNum() > 0)
|| rowBounds != RowBounds.DEFAULT)) {
//将参数中的MappedStatement替换为新的qs
page.setCountSignal(null);
BoundSql boundSql = ms.getBoundSql(args[1]);
args[1] = parser.setPageParameter(ms, args[1], boundSql, page);
page.setCountSignal(Boolean.FALSE);
//执行分页查询
Object result = invocation.proceed();
//得到处理结果
page.addAll((List) result);
}
} finally {
((PageSqlSource)ms.getSqlSource()).removeParser();
}
//注意,这返回的就是 step1 创建的 Page 对象
return page;
}
pageHelper:4.16 DEBUG:
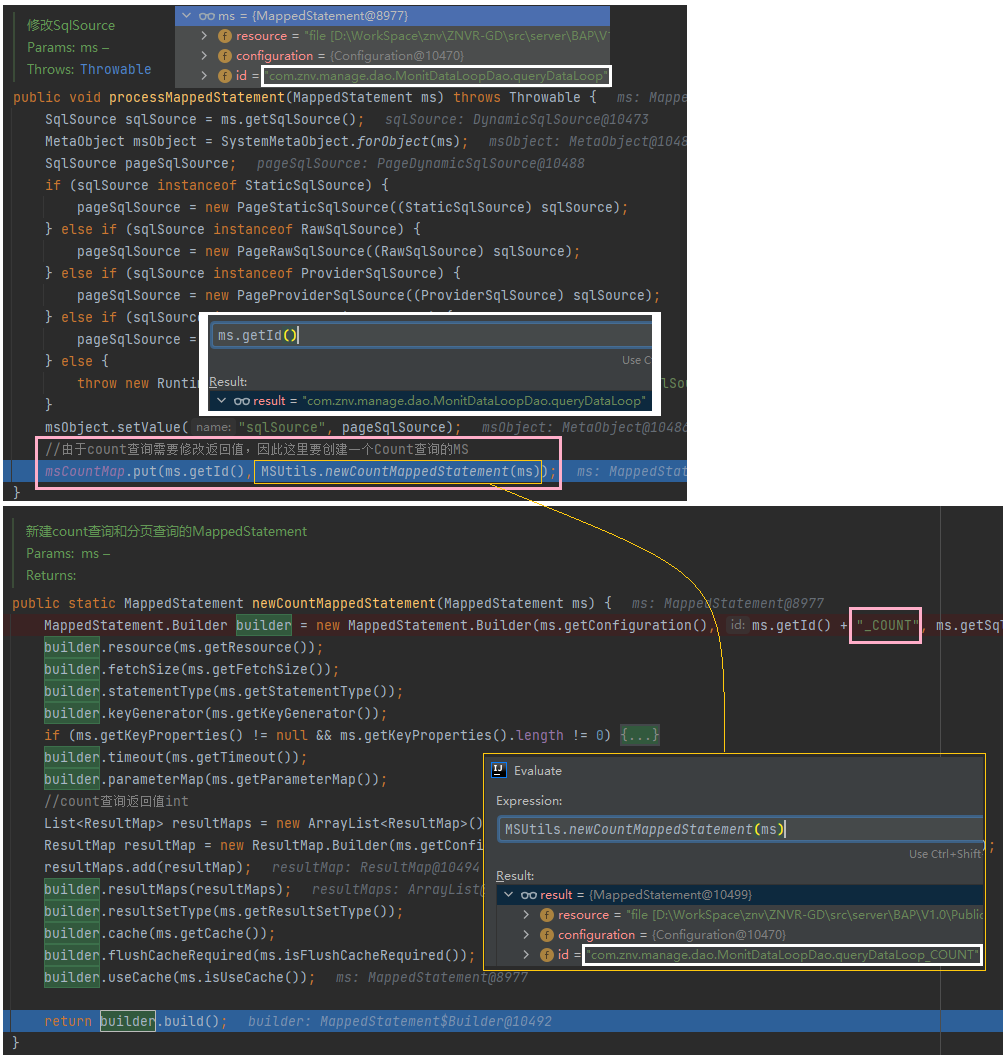
在 count 方法部分,插件动态的生成了一个名为 statementID_COUNT 的 SQL。
如上所示,count 方法中 countMsId 通过业务 statementID 和 countSuffix 后缀拼接生成。而这个 countSuffix 就是 _COUNT。接着看代码我们就不难发现,PageHelper 插件会优先取工程中存在 _COUNT 后缀的 sql,取不到则动态生成。
通过以上逻辑,我们就可以在项目中按它的规则,预先编写 {statementID}_COUNT 的 SQL,实现 count 分页逻辑的替换。这样我们就可以通过重写 count 方法,实现分页 SQL 的优化。
至此,service 方法中的第一个查询就结束了;然后,根据返回的 ids 查询具体的数据记录 List。

- step3#
L134 行也就是「示例」中错误方式得到的 total == size 的原因。
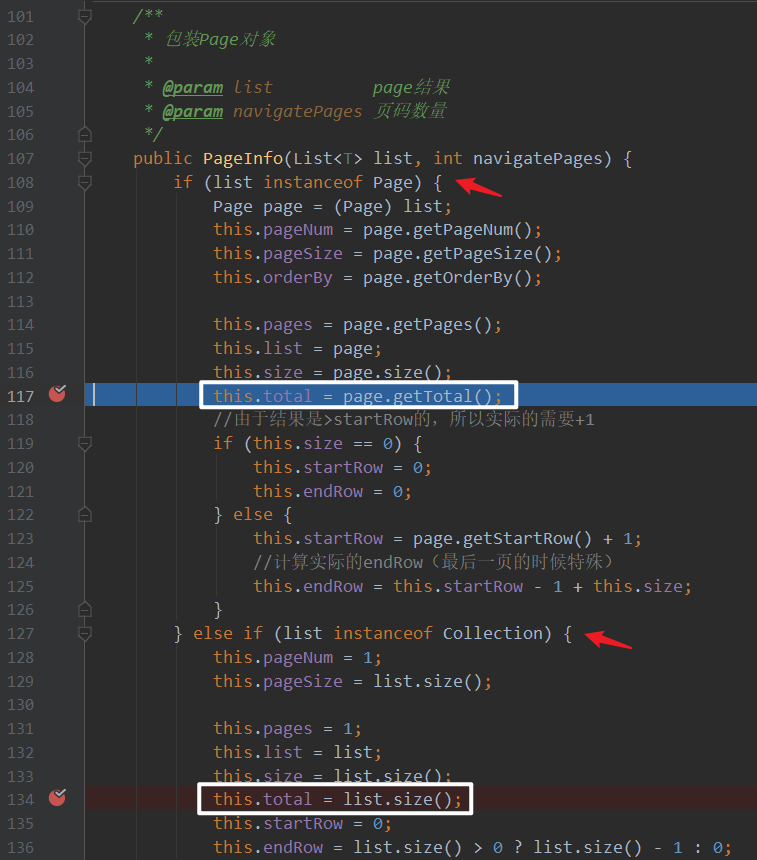
4. 小结#
关于这种分两次查询以加快查询,我的个人见解:
关于第 1 次只查出符合查询条件的记录的主键:
- 目前我所接触到的表的存储引擎均为 InnoDB。而 InnoDB 存储数据的特性:① InnoDB 的数据文件本身就是(主键)索引文件;② InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址;
- 如果 SELECT 的列只是主键列,那么查询就无需再回表了;
- PageHelper 也保存到了本次查询的分页相关信息;虽然返回结果是用
List<Bean>接收的,但根据上面的 debug 也能看出,它实际上是 Page 类型的(class Page<E> extends ArrayList<E>)。
关于第 2 次根据符合查询条件的记录的主键集合再去数据库查对应的详细数据行:
- 根据主键查询,效率高 ~
- 返回的结果就是一个纯纯的
ArrayList<Bean>(PageHelper 分页只会作用于第 1 次查询,对第 2 次及以后的查询无效); - 要求这两个查询方法返回的 List 的泛型类型必须一致,是因为要把 [1] 查询的 dataList 替换为 [2] 的查询结果;
- 即最终返回结果为:「1 查询所得到的分页信息 ∪ 2 查询所得的数据列表」




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
2020-03-14 40-暴力匹配 & KMP算法