[Re] 数组&函数&编译预处理
数组#
数组概述#
在程序设计中,为了方便处理数据把具有相同类型的若干变量按有序形式组织起来——称为数组。
数组就是在内存中连续的相同类型的变量空间。同一个数组所有的成员都是相同的数据类型,同时所有的成员在内存中的地址是连续的。
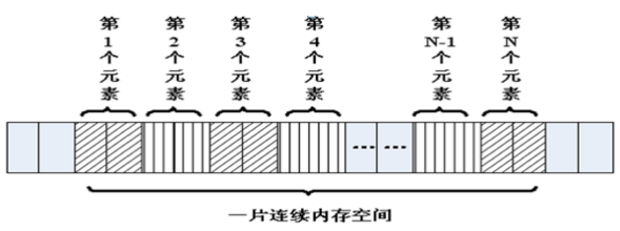
数组属于构造数据类型:
- 一个数组可以分解为多个数组元素:这些数组元素可以是基本数据类型或构造类型。
int a[10]; struct Stu boy[10]; - 按数组元素类型的不同,数组可分为:数值数组、字符数组、指针数组、结构数组等类别。
int a[10]; char s[10]; char* p[10];
通常情况下,数组元素下标的个数也称为维数,根据维数的不同,可将数组分为一维数组、二维数组、三维数组、四维数组等。通常情况下,我们将二维及以上的数组称为多维数组。
一维定义、初始化#
- 数组名字符合标识符的书写规定(数字、英文字母、下划线)
- 数组名不能与其它变量名相同,同一作用域内是唯一的
- 方括号
[]中常量表达式表示数组元素的个数
#include <stdio.h>
#define SIZE 18
int main() {
// int count;
int a[10]; // 定义了一个 int 类型数组,名字叫 a,有 10 个成员
// a[0] …… a[9],没有 a[10]
// 没有 a 这个变量,a 是数组的名字,但不是变量名,它是常量!
a[0] = 0;
// ……
a[9] = 9;
int b[10] = {1,2,3}; // 没赋值的元素,默认值为 0
int c[SIZE] = {1,2,3}; // 数组长度在编译时必须确定!
// scanf("%d", &count);
// int d[count];
int i = 0;
for (i = 0; i < 10; i++)
a[i] = i; // 给数组元素赋值
// 遍历数组,并输出每个成员的值
for (i = 0; i < 10; i++) {
printf("a[%d]=%d ", i, a[i]);
printf("b[%d]=%d\n", i, b[i]);
}
return 0;
}
在定义数组的同时进行赋值,称为初始化。全局数组若不初始化,编译器将其初始化为 0。局部数组若不初始化,内容为随机值。
// 定义一个数组,同时初始化所有成员变量
int a[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
// 初始化前3个成员,后面所有元素都默认为0
int a[10] = { 1, 2, 3 };
// 所有的成员都为 0
int a[10] = { 0 };
// [] 中若不声明元素个数,则定义时必须初始化
int a[] = { 1, 2, 3, 4, 5 }; // 定义了一个有5个成员的数组
二维定义和使用#
数据类型 数组名[行][列] 行 * 列 = 数组元素个数
#include <stdio.h>
int main06(void) {
int i, j;
//要求:求出四名学生三门功课的总成绩和各个学科的总成绩
int arr[4][3] = {
{88,99,100},
{36,42,59},
{60,60,60},
{88,88,88}
};
// 求出每名学生的总成绩
int sum = 0;
int i, j;
for(i=0; i<4; i++) {
for (j=0; j<3; j++) {
sum += arr[i][j];
}
printf("第 %d 名学生的总成绩为:%d\n", i+1, sum);
sum = 0; //重新初始化
}
sum = 0;
// 求出每个学科的总成绩
// 将行和列颠倒
for(i=0; i<3; i++) {
for(j=0; j<4; j++) {
sum += arr[j][i];
}
printf("第 %d 门学科的总成绩为:%d\n", i+1, sum);
sum = 0;
}
return 0;
}
数组名#
数组名是一个地址的常量,代表数组中首元素的地址。
#include <stdio.h>
int main() {
// 定义一个数组,同时初始化所有成员变量
int a[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
printf("a = %p\n", a);
printf("&a[0] = %p\n", &a[0]);
int n = sizeof(a); //数组占用内存的大小,10 个 int 类型,10 * 4 = 40
int n0 = sizeof(a[0]); //数组第 0 个元素占用内存大小,第 0 个元素为 int
int i = 0;
for (i = 0; i < sizeof(a) / sizeof(a[0]); i++) {
printf("%d ", a[i]);
}
printf("\n");
return 0;
}
字符数组和字符串#
- C 语言中没有字符串这种数据类型,可以通过 char 的数组来替代
- 字符串一定是一个 char 的数组,但 char 的数组未必是字符串
- 数字 0 (和字符
\0等价) 结尾的 char 数组就是一个字符串,但如果 char 数组没有以数字 0 结尾,那么就不是一个字符串,只是普通字符数组,所以字符串是一种特殊的 char 的数组。
#include <stdio.h>
int main1(void) {
// 定义字符数组
// char arr[10] = {'h','e','l','l','o','w','o','r','l','d'};
// 定义字符串(手动添加结束标记)
char arr[11] = {'h','e','l','l','o','w','o','r','l','d','\0'};
printf("%s\n", arr);
return 0;
}
int main2(void) {
// 定义字符串,字符串是用双引号引起来的
// 该方式定义,末尾会自动添加字符串结束标志\0
char arr[11] = "helloworld";
// char arr[] = {"helloworld"}; // {} 可省
// char ch = 'a'; // 字符 a
// char str[2] = "a"; // 字符串 a\0
//字符数组
// char arr[11] = {'h','e','l','l','o','w','o','r','l','d','\0'};
// %s是一个占位符,表示输出一个字符串,遇到 \0 表示输出停止
printf("%s\n", arr);
return 0;
}
int main3(void) {
char arr[100];
scanf("%s", arr); // scanf 在接收数据时遇到空格或者换行表示结束
printf("%s\n", arr);
return 0;
}
int main(void) {
//字符串比较
char arr1[] = "hello world";
char arr2[] = "hello world";
int i = 0;
while (arr1[i] == arr2[i]) {
// 判断是否到字符串结尾,如果到字符串结尾之前的的内容都相同,,则打印相同
if (arr1[i] == '\0') {
printf("两个字符串相同\n");
return 0;
}
i++;
}
printf("两个字符串不相同\n");
return 0;
}
两个案例#
案例1:将一个数组中的元素首尾依次逆转并输出
# include <stdio.h>
# include <malloc.h>
# include <math.h>
# include <time.h>
# include <stdlib.h>
# define length 11
# define dataRange 99
// 将一个数组中的元素首尾依次逆转并输出
int main(void) {
int i, j, temp;
srand((int)time(0));
int* pArr = (int*)(malloc(sizeof(int)*length));
for(i = 0; i < length; i++) {
pArr[i] = rand() % dataRange;
printf("%2d ", pArr[i]);
}
printf("\n");
for(i = 0, j = length-1; i < j; i++, j--) {
temp = pArr[i];
pArr[i] = pArr[j];
pArr[j] = temp;
}
for(i = 0; i < length; i++)
printf("%2d ", pArr[i]);
free(pArr);
return 0;
}
案例二:根据每个候选人的得票情况,依次输出前10为候选人(不能改变原数组顺序)
# include <stdio.h>
# include <malloc.h>
# include <math.h>
# include <time.h>
# include <stdlib.h>
# define lengthAll 15
# define lengthTop10 10
# define dataRange 100 // 随机数范围
/*
建立一个容量为10的最小堆,遍历数组,当最小堆容量小于10的时候直接push
当容量大于10的时候,数组的数和最小堆的堆顶的数进行比较,如果小于堆顶数
则不可能是最大的10个数之一,如果大于则和堆顶数进行交换,一直遍历完数组
*/
void printArray(int*, int); // 逆序打印
void adjustHeap(int[], int, int); // 最小堆
void findTop10(int[], int[]);
int main(void) {
int i;
srand((int)time(0)); // 使用系统时间生成真正随机数
int* pAll = (int*)(malloc(sizeof(int)*lengthAll));
for(i = 0; i < lengthAll; i++) pAll[i] = rand() % dataRange;
int* pTop10 = (int*)(malloc(sizeof(int)*lengthTop10));
printArray(pAll, lengthAll);
findTop10(pAll, pTop10);
printArray(pTop10, lengthTop10);
free(pAll);
free(pTop10);
return 0;
}
void findTop10(int* pAll, int* pTop10) {
int i, temp;
// 1. 先放10个进去
for(i = 0; i < 10; i++)
pTop10[i] = pAll[i];
// 2. 从最后一个非叶子结点开始, 自底向上, 构建小顶堆
for(i = lengthTop10 >> 1 - 1; i >= 0; i--)
adjustHeap(pTop10, i, lengthTop10);
// 3. 遍历pAll数组中的剩余元素
for(i = 10; i < lengthAll; i++)
if(pAll[i] > pTop10[0]) {
pTop10[0] = pAll[i];
adjustHeap(pTop10, 0, lengthTop10);
}
// --------- 至此, 找到前10名 ------------
// 对前十名排序
for(i = lengthTop10 - 1; i > 0; i--) {
temp = pTop10[i];
pTop10[i] = pTop10[0];
pTop10[0] = temp;
adjustHeap(pTop10, 0, i);
}
}
void adjustHeap(int* arr, int index, int length) {
// 保存当前待调整的局部二叉树的根结点的值
int val = arr[index];
int k;
// 从 上 -> 下 做调整
for(k = index*2+1; k < length; k = k*2+1) {
// 找 较小子结点
if(k+1 < length && arr[k+1] < arr[k]) k++;
if(arr[k] < val) { // 子比父小
arr[index] = arr[k];
index = k;
} else break;
}
arr[index] = val;
}
void printArray(int* p, int len) {
int i = len-1;
for(; i >= 0; i--)
printf("%2d ", p[i]);
printf("\n");
}
函数#
C 程序是由函数组成的,我们写的代码都是由主函数 main() 开始执行的。函数是 C 程序的基本模块,是用于完成特定任务的程序代码单元。
从函数定义的角度看,函数可分为系统函数和用户定义函数两种:
- 系统函数(库函数):这是由编译系统提供的,用户不必自己定义这些函数,可以直接使用它们,如我们常用的打印函数
printf()。 - 用户定义函数:用以解决用户的专门需要。
库函数#
当调用函数时,需要关心 5 要素:
- 头文件:包含指定的头文件
- 函数名字:函数名字必须和头文件声明的名字一样
- 功能:需要知道此函数能干嘛后才调用
- 参数:参数类型要匹配
- 返回值:根据需要接收返回值
随机数 API:
#include <time.h>
time_t time(time_t *t);
功能:获取当前系统时间
参数:常设置为NULL
返回值:当前系统时间, time_t 相当于long类型,单位为毫秒
·····················································
#include <stdlib.h>
void srand(unsigned int seed);
功能:用来设置rand()产生随机数时的随机种子
参数:如果每次seed相等,rand()产生随机数相等
返回值:无
·····················································
#include <stdlib.h>
int rand(void);
功能:返回一个随机数值
参数:无
返回值:随机数
案例一:产生一个随机数
# include <stdio.h>
// 1. 导入头文件
# include <stdlib.h>
# include <time.h>
int main() {
// 2. time() 获取当前系统时间
// 3. 将当前系统时间作为生成随机数时的随机种子
srand((unsigned int) time(NULL));
// 4. 产生随机数
int randNum = rand() % 100;
printf("随机数:%d", randNum);
return 0;
}
案例2:产生一个随机数组,要求元素各不相同。
# include <stdio.h>
# include <malloc.h>
# include <math.h>
# include <time.h>
# include <stdlib.h>
# define length 20
# define dataRange 30 // 随机数范围
void setData(int*, int);
void printArray(int*, int);
int searchData(int*, int, int);
int main(void) {
int i = 0;
srand((int)time(0));
int* pArr = (int*)(malloc(sizeof(int)*length));
setData(pArr, length);
printArray(pArr, length);
free(pArr);
return 0;
}
void setData(int* p, int len) {
int i, j; // 数组索引
// 使用系统时间生成真正随机数
for(i = 0, j = 0; i < len; i++, j = 0) {
p[i] = rand() % dataRange;
while(j < i) // 要求元素互不相同
if(p[i] == p[j++]) {
i--;
break;
}
}
}
void printArray(int* p, int len) {
int i = 0;
for(; i < len; i++)
printf("%2d ", p[i]);
printf("\n");
}
函数#
函数定义
返回类型 函数名(形式参数列表) {
数据定义部分;
执行语句部分;
}

形参和实参
- 函数的形参列表
- 在定义函数时指定的形参,在未出现函数调用时,它们并不占内存中的存储单元,因此称它们是 "形式参数" 或 "虚拟参数",简称 "形参",表示它们并不是实际存在的数据,所以,形参里的变量不能赋值。
- 在定义函数时指定的形参,必须是
类型 变量名的形式。 - 在定义函数时指定的形参,可有可无,根据函数的需要来设计。如果没有形参,圆括号内容为空,或写一个 void 关键字。
- 形参和实参
- 形参出现在函数定义中,在整个函数体内都可以使用,离开该函数则不能使用。
- 实参出现在主调函数中,进入被调函数后,实参也不能使用。
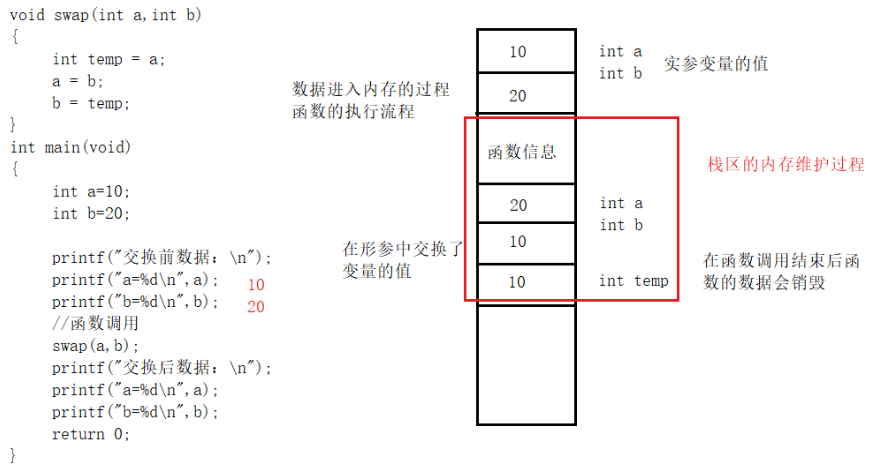
- 实参变量对形参变量的数据传递是“值传递”,即单向传递,只由实参传给形参,而不能由形参传回来给实参。
- 在调用函数时,编译系统临时给形参分配存储单元。调用结束后,形参单元被释放。
- 实参单元与形参单元是不同的单元。调用结束后,形参单元被释放,函数调用结束返回主调函数后则不能再使用该形参变量。实参单元仍保留并维持原值。因此,在执行一个被调用函数时,形参的值如果发生改变,并不会改变主调函数中实参的值。
该函数能否交换这两个数?
函数返回值
函数的返回值是通过函数中的 return 语句获得的,return 后面的值也可以是一个表达式。
- 尽量保证 return 语句中表达式的值和函数返回类型是同一类型。
- 如果函数返回的类型和 return 语句中表达式的值不一致,则以函数返回类型为准,即函数返回类型决定返回值的类型。对数值型数据,可以自动进行类型转换。// 注意:如果函数返回的类型和 return 语句中表达式的值不一致,而它又无法自动进行类型转换,程序则会报错!
double max() { int a = 10; // 返回值a为int类型,它会转为double类型再返回 return a; } - return 语句的另一个作用为中断 return 所在的执行函数,类似于 break 中断循环、switch 语句一样。
int max() { return 1; // 执行到,函数已经被中断,所以下面的return 2无法被执行到 return 2; // 没有执行 } - 如果函数带返回值,return 后面必须跟着一个值;如果函数没有返回值,函数名字的前面必须写一个 void 关键字,这时候,我们写代码时也可以通过 return 中断函数:
return;
函数调用
- 无参函数调用:不能加上 "实参",但括号不能省略
- 有参函数调用
- 如果实参表列包含多个实参,则各参数间用逗号隔开
- 实参与形参的个数应相等,类型应匹配(相同或赋值兼容)。实参与形参按顺序对应,一对一地传递数据。
- 实参可以是常量、变量或表达式,无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值,以便把这些值传送给形参。所以,这里的变量是在
()外面定义好、赋好值的变量。
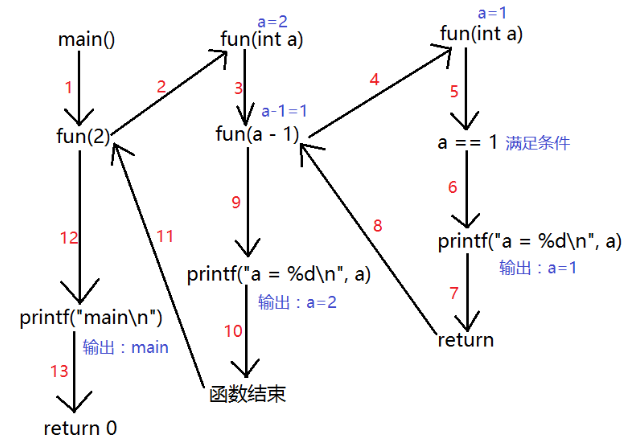
函数递归调用:
void fun(int a){
if (a == 1){
printf("a = %d\n", a);
return; //中断函数很重要
}
fun(a - 1);
printf("a = %d\n", a);
}
int main(void){
fun(2);
printf("main\n");
return 0;
}
3. 局部/全局变量#
- 局部变量也叫 auto 自动变量(auto 可写可不写),一般情况下代码块
{}内部定义的变量都是自动变量,它有如下特点:- 在一个函数内定义,只在函数范围内有效
- 在复合语句中定义,只在复合语句中有效
- 随着函数调用的结束或复合语句的结束局部变量的声明声明周期也结束
- 如果没有赋初值,内容为随机
- 全局变量
- 在函数外定义,可被本文件及其它文件中的函数所共用,若其它文件中的函数调用此变量,须用 extern 声明
- 全局变量的生命周期和程序运行周期一样
- 不同文件的全局变量不可重名
编译预处理#
宏定义和调用#
无参宏定义(宏常量)
如果在程序中大量使用到了 100 这个值,那么为了方便管理,我们可以定义常量:const int num = 100;。
但是如果我们使用 num 作为数组长度来定义一个数组,在 C99 标准的编译器上是不支持的!因为 num 不是一个编译器常量,如果想得到了一个编译器常量,那么可以使用:#define num 100。
在编译预处理时,将程序中在该语句以后出现的所有的 num 都用 100 代替。这种方法使用户能以一个简单的名字代替一个长的字符串,在预编译时将宏名替换成字符串的过程称为“宏展开”。宏定义,只在宏定义的文件中起作用。
- 宏名一般用大写,以便于与变量区别;
- 宏定义可以是常数、表达式等;
- 宏定义不作语法检查,只有在编译被宏展开后的源程序才会报错;
# define NUM 100 int main(void) { NUM = 123; // → 预编译: 100 = 123; → 编译报错 return 0; } - 宏定义不是 C 语言,不在行末加分号;
- 宏名有效范围为从定义到本源文件结束;
- 可以用
#undef命令终止宏定义的作用域; - 在宏定义中,可以引用已定义的宏名;
# define NUMA 10 # define NUMB 10 + NUMA
带参宏定义(宏函数)
在项目中,经常把一些短小而又频繁使用的函数写成宏函数,这是由于宏函数没有普通函数参数压栈、跳转、返回等的开销,可以调高程序的效率。
宏通过使用参数,可以创建外形和作用都与函数类似地类函数宏(function-like macro)。宏的参数用圆括号括起来。
# include <stdio.h>
// 多加括号,防止污染
# define SUM(x, y) ((x) + (y))
# define MAX(x, y) (((x)>(y)) ? (x) : (y))
# define ECHO() {printf("HelloWorld!"); printf("白世珠");}
int main() {
// 仅仅只是做文本替换 下例替换为 int sum = ((6)+(7));
// 不进行计算
int sum = SUM(6, 7);
printf("sum: %d\n", sum);
int max = MAX(6, 7);
printf("max: %d\n", max);
ECHO();
return 0;
}
- 宏的名字中不能有空格,但是在替换的字符串中可以有空格。ANSIC 允许在参数列表中使用空格
- 用括号括住每一个参数,并括住宏的整体定义
- 用大写字母表示宏的函数名
- 如果打算用宏代替函数来加快程序运行速度。假如在程序中只使用一次宏对程序的运行时间没有太大提高。
文件包含处理#
“文件包含处理”是指一个源文件可以将另外一个文件的全部内容包含进来。C 语言提供了 #include 命令用来实现“文件包含”的操作。

#incude<...> 和 #include"..." 的区别:
""表示系统先在 file1.c 所在的当前目录找 file1.h,如果找不到,再按系统指定的目录检索。<>表示系统直接按系统指定的目录检索。
注意:
#include <>常用于包含库函数的头文件;#include ""常用于包含自定义的头文件;- 理论上
#include可以包含任意格式的文件(.c、.h等) ,但一般用于头文件的包含;




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?