09-JDBC
数据库系统(DBS)#

在 DBS 中,数据不再仅仅服务于某个程序或用户,而是按一定的结构存储在数据库,作为共享资源。由数据库管理系统(DBMS)软件管理,使得数据能为尽可能多的应用服务
敲 SQL 命令的 CMD 窗口、Navicat Premium、PL/SQL developer 这都属于客户端!不是数据库服务器(DBMS)。客户端连接到数据库服务器,通过向服务器端发送 SQL 命令,让数据库服务器(DBMS)操作数据库,将操作结果返回给客户端。
乱码#
- 情景:插入一条记录,Error: Data too long for column 'name' at row1
- 乱码原因

- 乱码解决 → 统一编码
- 通知 Server,当前 Client 是什么编码集
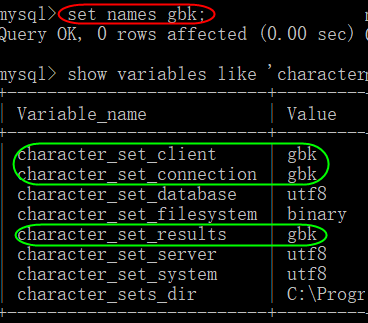
- 想要根本上解决,默认 Client 用的就是 GBK,得改配置文件
- [%MySQL_HOME%/my.ini] default-character-set=gbk
- 重启 [MySQL服务]
- 通知 Server,当前 Client 是什么编码集
补充:数据库用的是 U8,Client 用的是 GBK,那存储起来不就又乱码了吗?但是,结果显示并没有乱码,为什么?
- 编码:将字符编成二进制
- 解码:将二进制解析为字符
- 转码:将一个字符从《A字符集》表示的二进制转为《B字符集》表示的二进制的过程
事务#
review JDBC 管理事务:
try {
conn.setAutoCommit(false);
// SQL
SavePoint sp = conn.setSavePoint();
// SQL
conn.commit();
} catch () {
if (sp != null) {
conn.rollback(sp);
conn.commit();
} else conn.rollback();
} finally {
// close resource
}
Isolation 概述#
事务四大特性中的隔离性(Isolation)
- 如果两个线程并发修改,肯定会有问题,必须利用锁机制来防止多个线程的并发修改
- 如果两个线程并发查询,则没有线程安全问题
- 如果两个线程一个查询,一个修改,可能会有如下问题 → 设置隔离级别
- 脏读:一个事务读取到另一个事务未提交的数据
- 不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同(行级别)
- 虚读(幻读):在一个事务内读取到了别的事务插入的数据,导致前后读取不一致(表级别)
隔离级别#
- 基于一个查一个改可能出现的 3 个问题,数据库提出 4 个隔离级别:
- Read uncommitted:不防止任何问题
- Read committed:防止 [脏读]
- Repeatable read:防止 [脏读]、[不可重复读]
- Serializable:防止 All(被设计成单线程)
- 总结
- 从安全性考虑:Serializable > Repeatable read > Read committed > Read uncommitted
- 从效率上考虑:Read uncommitted > Read committed > Repeatable read > Serializable
- 真正使用 DB 的时候,根据自己使用数据库的需求,综合分析对安全性和对效率的要求,选择一个隔离级别,使数据库运行在这个隔离级别上
- 相关命令
- 查询当前数据库的隔离级别:
select @@tx_isolation; - 设置隔离级别:
set [global/session] transaction isolation level xxxxx;- 默认是 session,即修改 "当前 Client 的隔离级别"
- 若设置为 globe,修改的是 "数据库的默认隔离级别"
- 查询当前数据库的隔离级别:
锁机制#
数据库中的锁机制
- 共享锁
- 在 !Serializable 隔离级别下做查询不加任何锁,而在 Serializable 隔离级别下做查询加 [共享锁]
- 特点:[共享锁] 与 [共享锁] 可以共存,但是 [共享锁] 和 [排他锁] 不能共存
- 排他锁
- 在所有隔离级别下进行增删改操作都会加 [排他锁]
- 特点:和任意其它锁都不能共存
死锁问题
- 用户A开启事务,进行查询操作,获得 [共享锁];同时,用户B也开启事务,进行查询操作,也获得了 [共享锁],因为 [共享锁] 可以共存,所以OK。
- 此时,用户A做修改操作(即将 [共享锁] 升级为 [排他锁]),但与用户B的 [共享锁] 互斥了,于是陷入等待;用户B这时候也做修改操作(同理),但是与用户A的 [共享锁] 互斥了(用户A此时锁还没升级成功),于是也陷入等待状态。← DeadLock
- 而一旦发生死锁,MySQL 会自动将造成死锁的一方退出,另一方放行:

更新丢失#
问题描述#
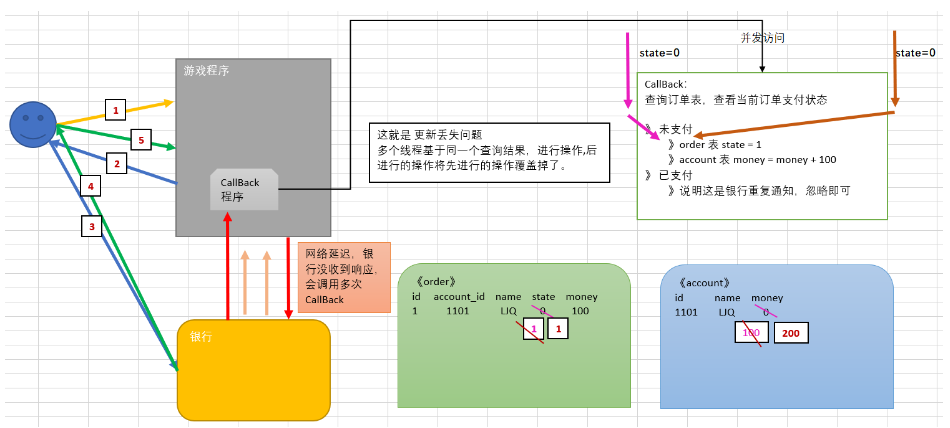
问题解决#
实现并发控制的主要手段大致可以分为乐观并发控制和悲观并发控制两种。
- 悲观锁
- 概述:悲观地认为每次操作都会造成更新丢失问题,故在每次查询时就加上排他锁
- 代码:
SELECT state FROM order WHERE id = 1 FOR UPDATE; - 分析:A执行,首先查询 state 字段(加排他锁),此时就算B来了,他也查不上 state(排他锁加不上),只能等待A执行完整套流程,释放锁之后,B才能做操作,在此之前,B只能等待A释放锁
- 情景:查询多,修改少
- 乐观锁
- 概述:乐观地认为每次查询都不会造成更新丢失,利用一个版本字段进行控制
- 代码(先为 order 表增加一个 version 字段)
start transaction; select state from order where id = 1; if(stat == 0) update order set state=1 and version=version+1 where id=1 and version=0; if(affectedRow == 1) update account set money=money+100 where id = 1; commit; - 分析:乐观锁每次在执行数据的修改操作时,都会带上一个版本号,一旦版本号和数据的版本号一致就可以执行修改操作并对版本号执行+1操作,否则就执行失败。因为每次操作的版本号都会随之增加,所以不会出现ABA问题,因为版本号只会增加不会减少。
- 情景:修改多,查询少
一篇文章#
并发控制
当程序中可能出现并发的情况时,就需要通过一定的手段来保证在并发情况下数据的准确性,通过这种手段保证了当前用户和其他用户一起操作时,所得到的结果和他单独操作时的结果是一样的。这种手段就叫做并发控制。并发控制的目的是保证一个用户的工作不会对另一个用户的工作产生不合理的影响。
没有做好并发控制,就可能导致脏读、幻读和不可重复读等问题。

常说的并发控制,一般都和数据库管理系统(DBMS)有关。在DBMS中的并发控制的任务,是确保在多个事务同时存取数据库中同一数据时,不破坏事务的隔离性和统一性以及数据库的统一性。
实现并发控制的主要手段大致可以分为乐观并发控制和悲观并发控制两种。
首先要明确:无论是悲观锁还是乐观锁,都是人们定义出来的概念,可以认为是一种思想。其实不仅仅是关系型数据库系统中有乐观锁和悲观锁的概念,像hibernate、tair、memcache等都有类似的概念。所以,不应该拿乐观锁、悲观锁和其他的数据库锁等进行对比。
悲观锁
当要对数据库中的一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是直接对该数据进行加锁以防止并发。这种借助数据库锁机制,在修改数据之前先锁定,再修改的方式被称之为悲观并发控制(又名“悲观锁”,Pessimistic Concurrency Control,缩写“PCC”)。
悲观锁,正如其名,具有强烈的独占和排他特性。它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度。因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
之所以叫做悲观锁,是因为这是一种对数据的修改抱有悲观态度的并发控制方式。我们一般认为数据被并发修改的概率比较大,所以需要在修改之前先加锁。
悲观锁主要分为共享锁或排他锁:
- 共享锁【Shared lock】又称为读锁,简称S锁。顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
- 排他锁【Exclusive lock】又称为写锁,简称X锁。顾名思义,排他锁就是不能与其他锁并存,如果一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据行读取和修改。
悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证。

但是在效率方面,处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会。另外还会降低并行性,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数据。
乐观锁
乐观锁是相对悲观锁而言的,乐观锁假设数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则返回给用户错误的信息,让用户决定如何去做。
乐观锁机制采取了更加宽松的加锁机制。乐观锁是相对悲观锁而言,也是为了避免数据库幻读、业务处理时间过长等原因引起数据处理错误的一种机制,但乐观锁不会刻意使用数据库本身的锁机制,而是依据数据本身来保证数据的正确性。
相对于悲观锁,在对数据库进行处理的时候,乐观锁并不会使用数据库提供的锁机制。一般的实现乐观锁的方式就是记录数据版本。

乐观并发控制相信事务之间的数据竞争(data race)的概率是比较小的,因此尽可能直接做下去,直到提交的时候才去锁定,所以不会产生任何锁和死锁。
实现方式
悲观锁实现方式:
悲观锁的实现,往往依靠数据库提供的锁机制。在数据库中,悲观锁的流程如下:
- 在对记录进行修改前,先尝试为该记录加上排他锁(exclusive locking)。
- 如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。具体响应方式由开发者根据实际需要决定。
- 如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
- 期间如果有其他对该记录做修改或加排他锁的操作,都会等待解锁或直接抛出异常。
拿比较常用的MySql Innodb引擎举例,来说明一下在SQL中如何使用悲观锁。
要使用悲观锁,必须关闭MySQL数据库的自动提交属性。因为MySQL默认使用autocommit模式,也就是说,当执行一个更新操作后,MySQL会立刻将结果进行提交。(sql语句:set autocommit=0)
以电商下单扣减库存的过程说明一下悲观锁的使用:
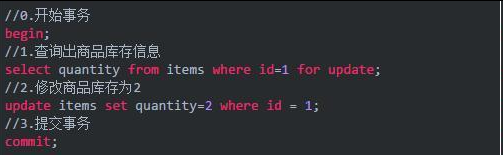
以上,在对id = 1的记录修改前,先通过for update的方式进行加锁,然后再进行修改。这就是比较典型的悲观锁策略。
如果以上修改库存的代码发生并发,同一时间只有一个线程可以开启事务并获得id=1的锁,其它的事务必须等本次事务提交之后才能执行。这样可以保证当前的数据不会被其它事务修改。
上面提到,使用select…for update会把数据给锁住,不过需要注意一些锁的级别,MySQL InnoDB默认行级锁。行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁把整张表锁住,这点需要注意。
乐观锁实现方式:
使用乐观锁就不需要借助数据库的锁机制了。
乐观锁的概念中其实已经阐述了它的具体实现细节。主要就是两个步骤:冲突检测和数据更新。其实现方式有一种比较典型的就是CAS(Compare and Swap)。
CAS是项乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
比如前面的扣减库存问题,通过乐观锁可以实现如下:

以上,在更新之前,先查询一下库存表中当前库存数(quantity),然后在做update的时候,以库存数作为一个修改条件。当提交更新的时候,判断数据库表对应记录的当前库存数与第一次取出来的库存数进行比对,如果数据库表当前库存数与第一次取出来的库存数相等,则予以更新,否则认为是过期数据。
以上更新语句存在一个比较重要的问题,即传说中的ABA问题。
比如说一个线程one从数据库中取出库存数3,这时候另一个线程two也从数据库中取出库存数3,并且two进行了一些操作变成了2,然后two又将库存数变成3,这时候线程one进行CAS操作发现数据库中仍然是3,然后one操作成功。尽管线程one的CAS操作成功,但是不代表这个过程就是没有问题的。
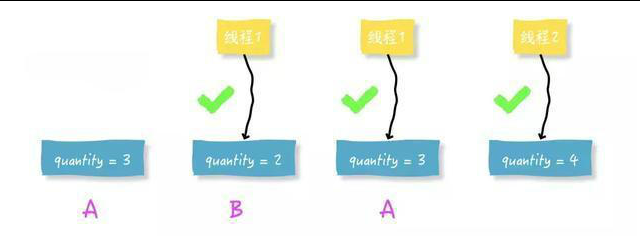
有一个比较好的办法可以解决ABA问题,那就是通过一个单独的可以顺序递增的version字段。改为以下方式即可:

乐观锁每次在执行数据的修改操作时,都会带上一个版本号,一旦版本号和数据的版本号一致就可以执行修改操作并对版本号执行+1操作,否则就执行失败。因为每次操作的版本号都会随之增加,所以不会出现ABA问题,因为版本号只会增加不会减少。
除了version以外,还可以使用时间戳,因为时间戳天然具有顺序递增性。
以上SQL其实还是有一定的问题的,就是一旦遇上高并发的时候,就只有一个线程可以修改成功,那么就会存在大量的失败。对于像淘宝这样的电商网站,高并发是常有的事,总让用户感知到失败显然是不合理的。所以,还是要想办法减少乐观锁的粒度的。有一条比较好的建议,可以减小乐观锁力度,最大程度的提升吞吐率,提高并发能力!如下:
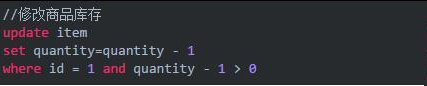
以上SQL语句中,如果用户下单数为1,则通过quantity - 1 > 0的方式进行乐观锁控制。
以上update语句,在执行过程中,会在一次原子操作中自己查询一遍quantity的值,并将其扣减掉1。
高并发环境下锁粒度把控是一门重要的学问,选择一个好的锁,在保证数据安全的情况下,可以大大提升吞吐率,进而提升性能。
如何选择
在乐观锁与悲观锁的选择上面,主要看下两者的区别以及适用场景就可以了。
- 乐观锁并未真正加锁,效率高。一旦锁的粒度掌握不好,更新失败的概率就会比较高,容易发生业务失败。
- 悲观锁依赖数据库锁,效率低。更新失败的概率比较低。
随着互联网三高架构(高并发、高性能、高可用)的提出,悲观锁已经越来越少的被应用到生产环境中了,尤其是并发量比较大的业务场景。
连接池#
- 应用程序直接获取链接的缺点

- 使用数据库连接池优化程序性能

- 编写连接池需实现
javax.sql.DataSource<I>,并实现连接池功能的步骤:- 在 DataSource 构造函数中批量创建与数据库的连接,并把创建的连接保存到一个集合对象中
- 实现
getConnection(),使该方法每次被调用时,从集合对象中取一个 Connection 返回给用户 - 当用户使用完 Connection,调用
close()时,Collection 对象应保证将自己返回到连接池的集合对象中,而不要把 conn 还给数据库

public class MyPool implements DataSource {
private static List<Connection> pool = new LinkedList<Connection>();
static {
try {
Class.forName("com.mysql.jdbc.Driver");
for(int i = 0; i<5; i++) {
Connection conn = DriverManager.getConnection("jdbc:mysql:///test","root","root");
pool.add(conn);
}
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
public Connection getConnection() throws SQLException {
if(pool.size() == 0)
for(int i = 0; i<5; i++) {
Connection conn = DriverManager.getConnection("jdbc:mysql:///test", "root", "root");
pool.add(conn);
}
System.out.println("拿走一个!");
// 局部内部类可以使用外部方法的局部变量,但是局部变量必须是 final 的
final Connection conn = pool.remove(0);
// 动态代理
return (Connection) Proxy.newProxyInstance(conn.getClass().getClassLoader(),
conn.getClass().getInterfaces(), new InvocationHandler() {
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
if(method.getName().equals("close")) {
System.out.println("[动态代理] 通过调用close将连接还回来");
retConn(conn);
return null;
} else {
return method.invoke(conn, args);
}
}
});
}
private void retConn(Connection conn) throws SQLException {
if(conn!=null && !conn.isClosed()) {
System.out.println("还回一个!");
pool.add(conn);
}
}
}
元数据#
元数据:数据库、表、列的定义信息
数据库元数据#
- 获取元数据对象:
DatabaseMetaData metaData = conn.getMetaData(); - 获取DB连接时使用的URL:
String url = metaData.getURL(); - 获取数据库的用户名:
String user = metaData.getUserName(); - 获取驱动名称:
String driver = metaData.getDriverName(); - 获取数据库中指定表的主键信息

ResultSet rs = metaData.getPrimaryKeys(null, null, "account"); while(rs.next()) { short cSeq = rs.getShort("KEY_SEQ"); String cName = rs.getString("COLUMN_NAME"); System.out.println(cSeq+":"+cName); // 1:id } - 获取表(可模糊查询当前数据库中的表)

rs = metaData.getTables(null, null, "%", new String[]{"TABLE"}); while(rs.next()) { String tableName = rs.getString("TABLE_NAME"); System.out.println(tableName); }
参数元数据#
- 获取元数据对象:
ParameterMetaData metaData = ps.getParameterMetaData(); - 获取参数(占位符)个数:
int count = metaData.getParameterCount(); - 获取参数的 SQL 类型(不支持)
- 需要先在连接的 url 后拼接一个参数,否则会抛异常:
?generateSimpleParameterMetadata=true - 异常虽然不抛了,但返回值永远是 VARCHAR:
String paramType = getParameterTypeName(1)
- 需要先在连接的 url 后拼接一个参数,否则会抛异常:
结果集元数据#
- 获取元数据对象:
ResultSetMetaData metaData = rs.getMetaData(); - 获取结果集中的列数:
int columnCount = metaData.getColumnCount(); - 获取结果集中指定列的名称:
String columnName = metaData.getColumnName(2); - 获取结果集中指定列类型的名称(支持):
String columnTypeName = metaData.getColumnTypeName(1);
System.out.println("------------------------------------");
int columnCount = metaData.getColumnCount();
for(int i = 1; i<=columnCount; i++)
System.out.print(metaData.getColumnName(i)+"["+metaData.getColumnTypeName(i)+"]\t");
System.out.println("\n------------------------------------");
while(rs.next()) {
for(int i = 1; i<=columnCount; i++) {
Object obj = rs.getObject(i);
System.out.print(obj+"\t\t");
}
System.out.println();
}
System.out.println("------------------------------------");
DbUtils#

ResultSetHandler<I> 实现类的示例:
public class ResultSetHandlerDemo {
QueryRunner runner = new QueryRunner(new ComboPooledDataSource());
// ArrayHandler: 把结果集中的第一行数据转成对象数组
public void test1() throws SQLException {
Object[] obj = runner.query("select * from account", new ArrayHandler());
System.out.println(obj);
}
// ArrayListHandler: 把结果集中的每一行数据都转成一个对象数组,再存放到List中
public void test2() throws SQLException {
List<Object[]> list = runner.query("select * from account", new ArrayListHandler());
System.out.println(list);
}
// BeanHandler: 将结果集中的第一行数据封装到一个对应的JavaBean中
public void test3() throws SQLException {
Account acc = runner.query("select * from account"
, new BeanHandler<Account>(Account.class));
System.out.println(acc);
}
// BeanListHandler: 把结果集中的每一行数据都转成一个JavaBean,再存放到List中
public void test4() throws SQLException {
List<Account> list = runner.query("select * from account"
, new BeanListHandler<Account>(Account.class));
System.out.println(list);
}
// MapHandler: 将结果集中的第一行数据封装到一个Map里,key是列名,value是对应值
public void test5() throws SQLException {
Map<String,Object> map = runner.query("select * from account", new MapHandler());
System.out.println(map);
}
// MapListHandler: 把结果集中的每一行数据都封装到一个Map里,再存放到List中
public void test6() throws SQLException {
List<Map<String,Object>> list = runner.query("select * from account"
, new MapListHandler());
System.out.println(list);
}
// ColumnListHandler: 将结果集中的某一列,组成List
public void test7() throws SQLException {
List<Object> list = runner.query("select * from account", new ColumnListHandler(3));
System.out.println(list);
}
// KeyedHandler: 将结果集中的每一行数据都封装到map里,把map再存到一个大Map里
// 大Map的键,就是"KeyedHandler构造器里给定参数"所对应列的值
public void test8() throws SQLException {
Map<Object,Map<String,Object>> map = runner.query("select * from account"
, new KeyedHandler(2));
System.out.println(map);
System.out.println(map.get("liujiaqi").get("user"));
}
// ScalarHandler: 获取结果集中第一行数据指定列的值(常用来进行"单值查询")
public void test9() throws SQLException {
Long count = (Long) runner.query("select count(*) from account", new ScalarHandler());
System.out.println(count);
}
}
整个 demo 简单理解下 QueryRunner 两行代码搞定 CRUD 的原理:
public class MyQueryRunner {
private DataSource source;
public MyQueryRunner() {}
public MyQueryRunner(DataSource source) {
this.source = source;
}
public int update(String sql, Object... params) throws SQLException {
Connection conn = source.getConnection();
PreparedStatement ps = conn.prepareStatement(sql);
ParameterMetaData metaData = ps.getParameterMetaData();
int paramCount = metaData.getParameterCount();
for(int i = 1; i<=paramCount; i++)
ps.setObject(i, params[i-1]);
int count = ps.executeUpdate();
DbUtils.closeQuietly(conn, ps, null);
return count;
}
public <T> T query(String sql, MyResultSetHandler<T> rsh, Object... params)
throws SQLException {
Connection conn = source.getConnection();
PreparedStatement ps = conn.prepareStatement(sql);
ParameterMetaData metaData = ps.getParameterMetaData();
int paramCount = metaData.getParameterCount();
for(int i = 1; i<=paramCount; i++)
ps.setObject(i, params[i-1]);
ResultSet rs = ps.executeQuery();
T t = rsh.handle(rs); // 回调[处理结果集的逻辑]
DbUtils.closeQuietly(conn, ps, rs);
return t;
}
}
interface MyResultSetHandler<T> {
public T handle(ResultSet rs) throws SQLException;
}
练习:在客户信息列表页面之前提供了一个条件查询的表单,允许通过"用户名"/"性别"/"客户类型"进行条件查询
public List<Cust> findCustByCond(Cust cust) {
String sql = "select * from customer where 1=1";
List<Object> list = new ArrayList<Object>();
if(cust.getName()!=null && !"".equals(cust.getName().trim())) {
sql += " and name like ?";
list.add("%" + cust.getName() + "%");
}
if(cust.getGender()!=null && !"".equals(cust.getGender())) {
sql += " and gender = ?";
list.add(cust.getGender());
}
if(cust.getType()!=null && !"".equals(cust.getType())) {
sql += " and type = ?";
list.add(cust.getType());
}
QueryRunner runner = new QueryRunner(DaoUtils.getSource());
try {
if(list.size() == 0)
return runner.query(sql, new BeanListHandler<Cust>(Cust.class));
else
return runner.query(sql, new BeanListHandler<Cust>(Cust.class), list.toArray());
} catch (SQLException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?