
记一次JAVA FULL GC问题处理【1】
1: 线上出现连续几次服务不可用,
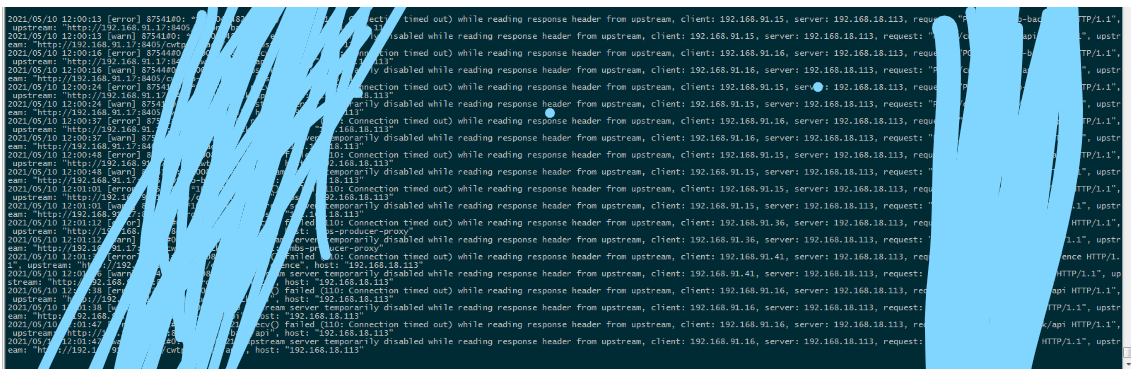
2: 刚开始通过查询内存JAVA对象大小的数量看是不是有内存泄露
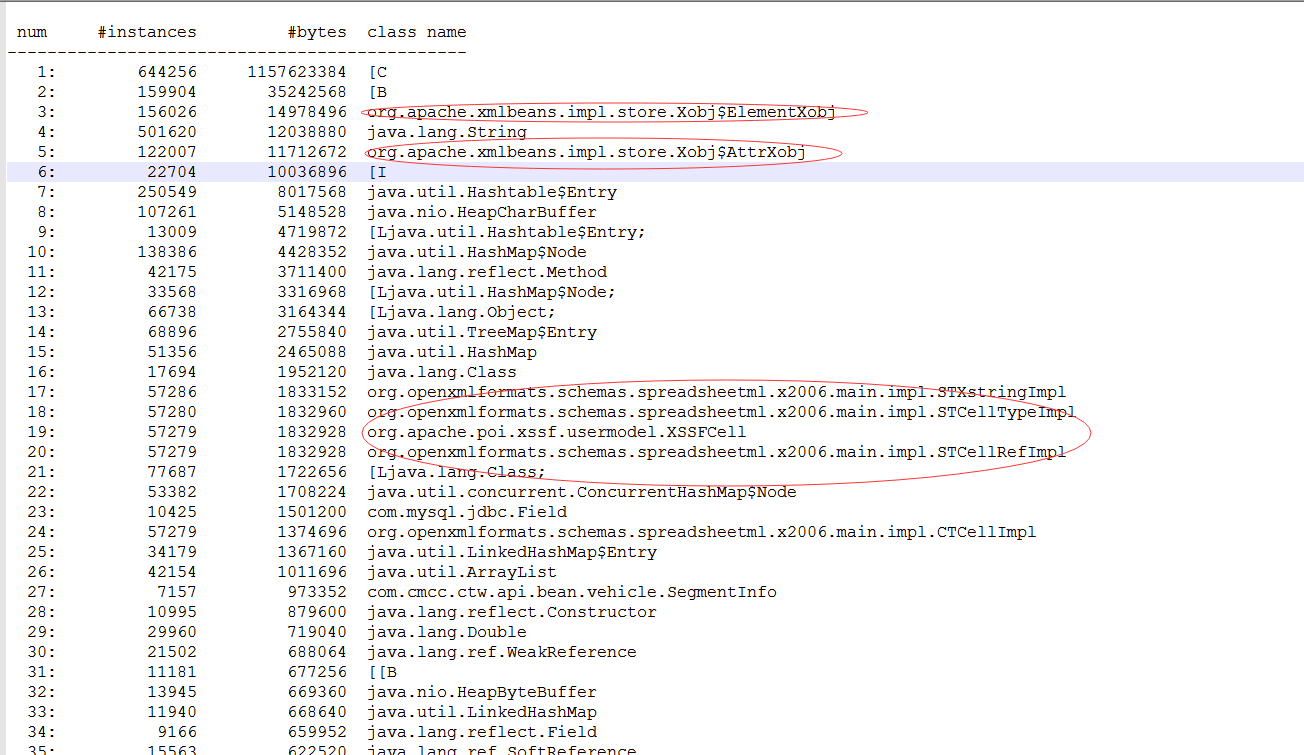
3: jmap -dump:format=b,file=heap.binnew 8 通过jvisualvm 查看这些对象的信息
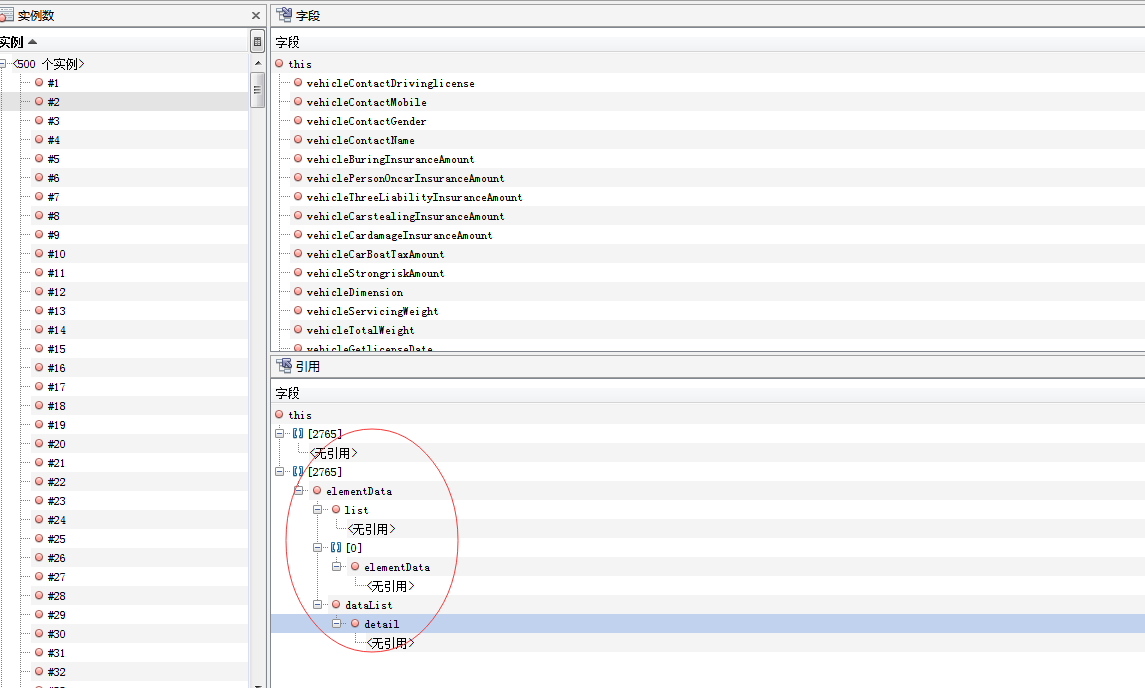
发现存在众多的无根引用对象,也就是内存泄露的问题,基本可以排除。
看到这里,觉得找到了真像,确认为是由于使用POI 的非流式服务,导致了在一次请求导出流程中,生成了过多的对象,导致YGC无法回收。
如果导出时间过长,从而导致这些对象进入老年代。 (看到这里,当时心里也有疑问,为什么不直接发生OOM呢)。 不过在现网找,确实也发地生过OOM。
4: 优化方式: 后来使用流式的SXSSFWorkbook 做导出操作。
并在测试环境做了对比测试, 因为测试环境只有400M,所以没法和现网比较(好吧,这个我承认我们很挫,尽然没有性能测试环境) 。只很通过修改前更的对比测试了。
在原来修改前使用XSSFWorkbook时,必然每次都发生,FULL GC 也有可能发生OOM。
在修改成SXSSFWorkbook后,情况大大的好转,发生FULL GC概率减少。 当时考虑到现网的内存比测试环境好,而且测试环境使用的到出极限数量比现网还大,觉得上线没有问题。
5:不好意思,运行十来天后,现网再次发生连续的FULL GC , 当时觉得不科学呀。通过监控看到YGC 基本失效了,FULL GC到时连续不断
发现FULL GC时间几秒到几十秒都会发生一次
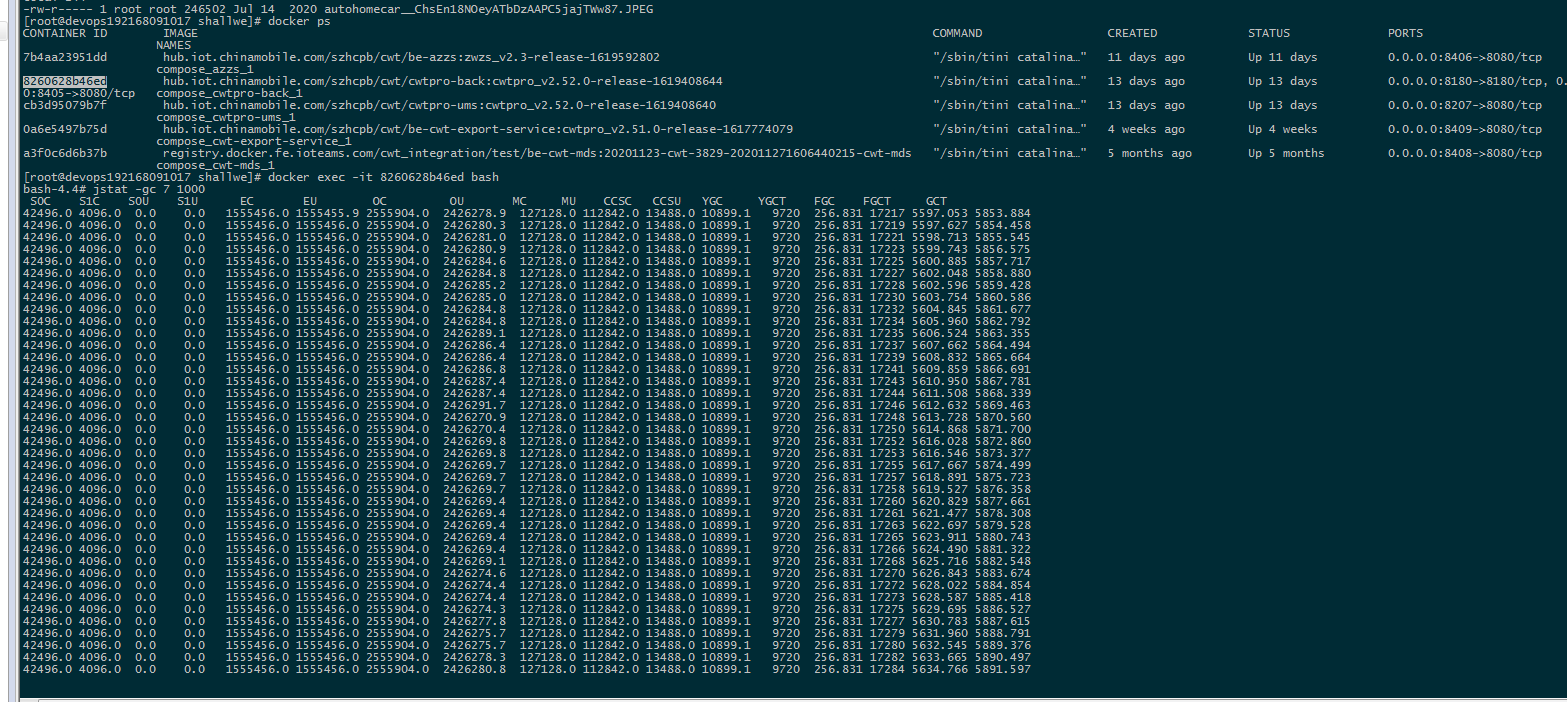
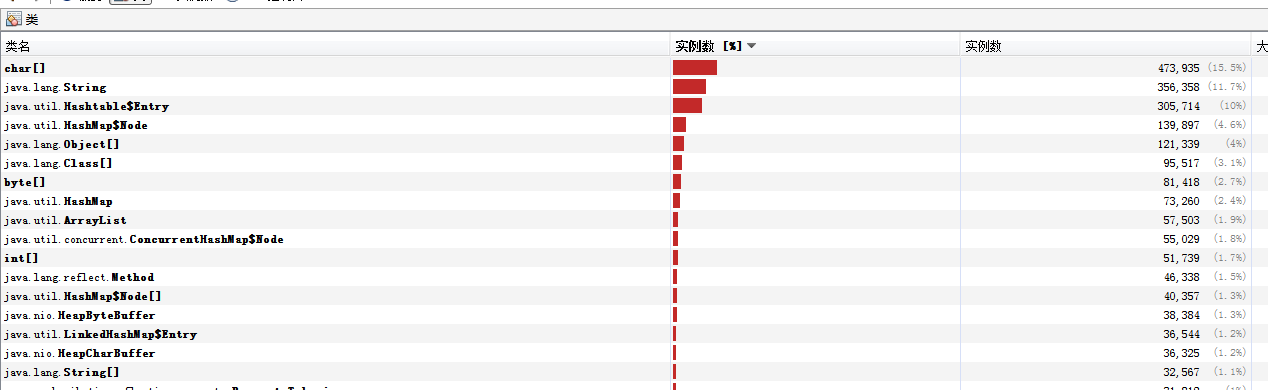
7: 也就是申请到的Survior的空间过小,考虑到Survior 空间过小的原因,先从启动参数说起。
JAVA启动参数:
-Xmx4g -Xms4g -Xmn1600m -XX:+UseParallelGC 可以看出,配置极少。 也就是除了指定新生代大小后,根本本没有指定 Survior区大小。但Survivor有个默认比例,完全与默认的的单个Survior应该有 有整个年轻代的1/10 。
/usr/local/tomcat # java -XX:+PrintFlagsFinal -version |grep NewRatio
uintx NewRatio = 2 {product}

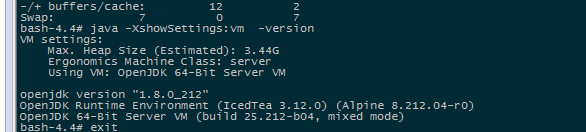
系统计算的可用堆内存, 是3.44G,与申请的内存大小4G有差距。
8: 后改用,并降低本机器其它的机器申请的Xmx数量,让本服务获得更多的内存,解决本问题。并取消JVM的自适应,防止内存不够时,把Survivor的内存放得更小。
-Xmx4g -Xms4g -Xmn16
00m -XX:+UseParallelGC -XX:-UseAdaptiveSizePolicy -XX:SurvivorRatio=8 -Djdk.tls.ephemeralDHKeySize=2048
9: 后续声音,我们的现网缩容了,原来20G的现网, 现在只有16G了, 而且docker服务多跑了一个。

10: 那本次Full GC Survior区值小的原因是什么呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号