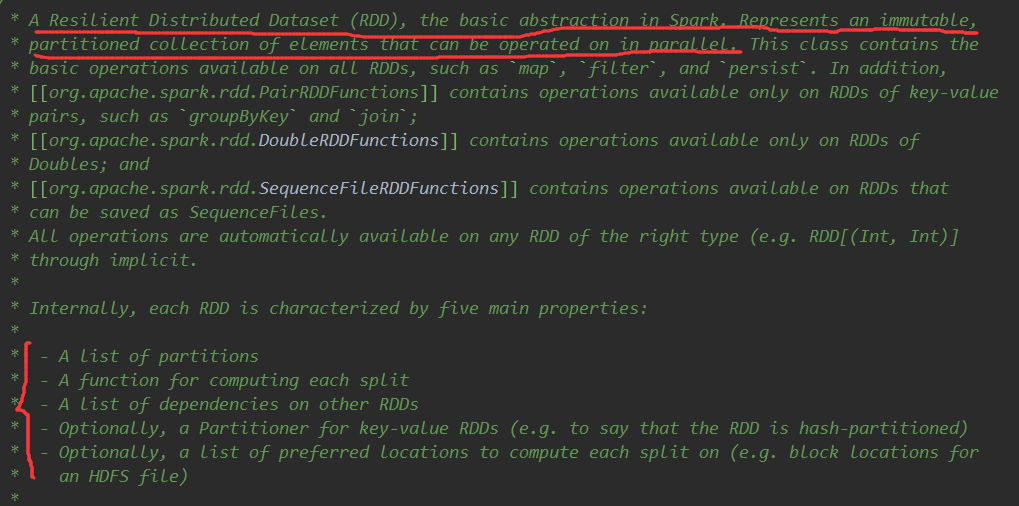
RDD:弹性分布式数据集,是spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
五大特性:
—分区列表,RDD中的数据都存在一个分区列表里面
—作用在每一个分区中的函数
—RDD依赖于其他多个RDD
—Partitioner针对KV类型的RDD
—数据本地性,数据位置最优