

(转)Python 运算符重载2
原文:https://zhuanlan.zhihu.com/p/358748722
前言
运算符重载这个语言特性其实一直备受争议,鉴于太多 C++ 程序员滥用这个特性,Java 之父 James Gosling 很干脆的决定不为 Java 提供运算符重载功能。但另一方面,正确的使用运算符重载确实能提高代码的可读性和灵活性。为此,Python 施加了一些限制,在灵活性、可用性和安全性之间做到了平衡。主要包括:
- 不能重载内置类型的运算符
- 不能新建运算符,只能重载现有的
- is、and、or 和 not 运算符不能重载(但位运算符 &、\| 和 ~ 可以)
Python 的运算符重载非常方便,只需要重写对应的特殊方法。在上面一节我们已经介绍了如何重载一个向量类的 "+" 和 "==" 运算符,实现还算简单,接下来我们考虑一个更复杂的情形:不只限于二维向量相加的 Vector 类,以引入 Python 运算符重载更全面的知识点。
改进版的 Vector
考虑到高维向量的应用场景,我们应当支持不同维度向量的相加操作,并且为低维向量的缺失值做默认添 0 处理,这也是一些统计分析应用的常用缺失值处理方式。基于此,首先要确定的便是,Vector 类的构造函数不再只接收固定数量和位置的参数,而应当接收可变参数。
通常情况下,Python 函数接收可变参数有两种处理方式。一种是接收不定长参数,即 *args,这样我们就可以用类似 Vector(1, 2) 或 Vector(1, 2, 3) 的方式来初始化不同维数的向量类。在这种情况下,函数会将不定长参数打包成名为 args 的元组进行处理,当然能满足迭代的需求。虽然这种方式看上去很直观,但考虑到向量类从功能上讲也是一个序列类,而 Python 中的内置序列类型的构造方法基本上都是接收可迭代对象(Iterable)作为参数,考虑到一致性我们也采取这种形式,并且通过重写 __repr__ 输出更直观的向量类的数学表示形式。
class Vector:
def __init__(self, components: Iterable):
self._components = array('i', components)
def __repr__(self):
return str(tuple(self._components))为了方便之后对向量分量的处理,将其保存在一个数组中,第一个参数 ‘i’ 标明这是一个整型数组。这样做还有一个好处就是,保证了向量序列的不可变性,这一点同 Python 内置类型不可变列表 tuple 类似。如此定义后,我们可以这样实例化 Vector 类:
>>> from vector import Vector
>>> Vector([1, 2])
(1, 2)
>>> Vector((1, 2, 3))
(1, 2, 3)
>>> Vector(range(4))
(0, 1, 2, 3)由于 Vector 类接收 Iterable 对象作为构造参数,而任何实现了 __iter__ 方法的类都会被绑定为 Iterable 的子类,所以可以传入 list、tuple 和 range 等可迭代对象。
接下来,重载 Vector 类的加号运算符,为了满足之前所说的低维向量默认添 0 处理,我们引入迭代工具包下的 zip_longest 方法,它可以接收多个可迭代对象,将其打包成一个个的元组,如 zip_longest(p, q, ...) --> (p[0], q[0]), (p[1], q[1]), ...。同时关键字参数 fillvalue 可以指定填充的默认值。但在这之前,由于 zip_longest 参数必须是可迭代对象,我们还需要为 Vector 类实现 __iter__ 方法。
class Vector:
def __iter__(self):
return iter(self._components)
def __add__(self, other):
pairs = itertools.zip_longest(self, other, fillvalue=0)
return Vector(a + b for a, b in pairs)__add__ 的实现逻辑很简单,按位相加返回一个新的 Vector 对象,在构造 Vector 对象时使用到了生成器表达式,而生成器 Generator 是 Iterable 的子类,所以也符合构造参数的要求。
为了验证效果,还需要重载 == 运算符,考虑到两个向量维度可能不同,首先要对维度,也就是向量分量的个数进行比较,为此需要重写 __len__ 方法。其次是进行按位比较,内置的 zip 函数可以将两个迭代对象打包从而同时进行遍历。
class Vector:
def __len__(self):
return len(self._components)
def __eq__(self, other):
return len(self) == len(other) and all(a == b for a, b in zip(self, other))最佳实践:用 zip 函数同时遍历两个迭代器。《Effective Python》的第 11 条提到了这一点。在 Python 中经常会遇到需要平行地迭代两个序列的情况。一般的做法是,写一个 for 循环对一个序列进行迭代,然后想办法获得其索引,通过索引访问第二个序列的对应元素。常见的做法是借助 enumerate 函数,通过 for index, item in enumerate(items) 的方式获取索引。现在有一种更优雅的写法,使用内置的 zip 函数,它可以将两个及以上的迭代器封装成生成器,这个生成器能在每次迭代时从每个迭代器中取出下一个值构成元组,再结合元组拆包就能达到平行取值的目的,如上述代码中的 for a, b in zip(self, other)。显然,这种方式可读性更高。但如果待遍历序列不等长,zip 函数会提前终止,这可能导致意外的结果。所以在不确定序列是否等长的条件下,可以考虑使用 itertools 模块中过的 zip_longest 函数。
至此,重载的 "+" 和 "==" 运算符初步完成了,可以编写测试用例进行验证了,作为本系列第一个比较全面的测试类,我将在文末贴出完整的测试代码,这里先在控制台演示重载之后的效果。
>>> v1 = Vector([1, 2])
>>> v1 == (1, 2)
True
>>> v1 + Vector((1, 1))
(2, 3)
>>> v1 + [1, 1]
(2, 3)
>>> v1 + (1, 1, 1)
(2, 3, 1)由于 __add__ 方法中的 other 只要求是可迭代对象而没有类型限制,所以重载的加号运算符不止可以对两个 Vector 实例进行相加,也支持 Vector 实例与一个可迭代对象相加,不管是 list、tuple 还是其他 Iterable 类型。但需要注意的是,可迭代对象必须作为第二个操作数,也就是 "+" 右侧的操作数。理解这一点并不难,因为我们只实现了 Vector 的 __add__ 方法,而 Python 的内置类型类可不明白怎么对加上一个向量进行处理,比如下面报错提示的 tuple 类。
>>> (1, 1) + v1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate tuple (not "Vector") to tuple反向运算符
那么有什么方法,不需要重写 tuple 类中的 __add__ 方法(显然这种方式也不合理),也能使重载的加号运算符支持 (1, 1) + v1 呢?答案是有的,在此之前,不得不提到 Python 的运算符分派机制。
对于中缀运算符,Python 提供了特殊的分派机制。对于表达式 a + b,解释器会执行以下几步操作:
- 如果 a 有
__add__方法且不返回 NotImplemented,调用a.__add__(b); - 如果 a 没有
__add__方法或调用返回 NotImplemented,检查 b 有没有__radd__方法,如果有且不返回 NotImplemented,调用b.__radd__(a); - 如果 b 没有
__radd__方法或调用返回 NotImplemented,抛出 TypeError。
注:NotImplemented 是 Python 内置的特殊单例值,如果运算符特殊方法不能处理给定的操作数,那么要把它返回给解释器。
如果将 __add__ 称为正向方法,那么 __radd__ 就可以称为 __add__ 方法的反向方法,或者右向方法,这个方法的作用是支持操作数从右至左进行计算。因此,为了支持 (1, 1) + v1,我们需要定义 Vector 类的反向方法。而反向方法只需要委托给已经定义好的 __add__ 方法。
class Vector:
def __add__(self, other):
try:
pairs = itertools.zip_longest(self, other, fillvalue=0)
return Vector(a + b for a, b in pairs)
except TypeError:
return NotImplemented
def __radd__(self, other):
return self + other__radd__ 通常就是这么简单,由于解释器调用的是 b.__radd__(a),而这里的 b 即 v1 是一个 Vector 实例,能够与一个元组相加,所以这时 (1, 1) + v1 不会再报错。同时,还对 __add__ 方法做了些修改:捕获 TypeError 异常并返回 NotImplemented。这也是一种重载中缀运算符时的最佳实践,抛出异常将导致算符分派机制终止,而抛出 NotImplemented 则会让解释器再尝试调用反向运算符方法。当运算符左右操作数是不同类型时,反向方法也许能够正常运算。
现在,验证重载的反向运算符:
>>> v1 = Vector([1, 2])
>>> (1, 1) + v1
(2, 3)
>>> [1, 1, 1] + v1
(2, 3, 1)比较运算符
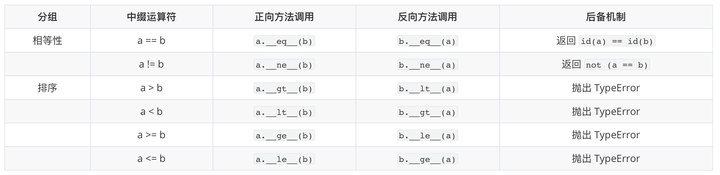
对于比较运算符,正向和反向调用使用的是同一系列方法,只不过对调了参数。注意是同一系列而不是同一方法。例如,对 "==" 来说,正向调用是 a.__eq__(b),那么反向调用就是 b.__eq__(a);而对 ">" 来说,正向 a.__gt__(b) 的反向调用是 b.__lt__(a)。
如果正向调用左操作数的 __eq__ 方法返回 NotImplemented,Python 解释器会去尝试反向调用右操作数的 __eq__ 方法,若右操作数也返回 NotImplemented,解释器不会抛出 TypeError 异常,而是会比较对象的 ID 作最后一搏。
对元组和 Vector 实例比较的具体步骤如下:
- 尝试调用 tuple 的
__eq__方法,由于 tuple 不认识 Vector 类,返回 NotImplemented; - 尝试调用 Vector 的
__eq__方法,返回 True。
>>> (1, 2) == Vector([1, 2])
True另外,对于 "!=" 运算符,Python 3 的最佳实践是只实现 __eq__ 方法而不实现它,因为从 object 继承来的 __ne__ 方法会对 __eq__ 返回的结果取反。而 Python 2 则不同,重载 "==" 的同时也应重载 "!=" 运算符。Python 之父 Guido 曾提到这是 Python 2 的一个设计缺陷且已在 Python 3 中修复了。
就地运算符
增量赋值运算符,也称就地运算符,如 "+=",有两种运算方式。对于不可变类型来说,a += b 的作用与 a = a + b 完全一致,增量赋值不会修改不可变目标,而是新建实例,然后重新绑定,也就是说运算前后的 a 不是同一对象。对于不可变类型,这是预期的行为。
而对于实现了就地运算符方法,如 __iadd__,的可变类型来说,a += b 会调用该方法就地修改左操作数,而不是创建一个新的对象。这一点,Python 的内置类型,不可变的 tuple 和可变的 list 就可以很好的说明。
>>> t = (1, 2)
>>> id(t)
4359598592
>>> t += (3,)
>>> id(t)
4359584960
>>> l = [1, 2]
>>> id(l)
4360054336
>>> l += [3, 4]
>>> id(l)
4360054336阅读源码你会发现,list 类 实现了 __iadd__ 方法而 tuple 类没有实现。对 list 而言,"+=" 就地运算符的逻辑与其 extend() 方法相同,将一个可迭代对象的元素依次追加到当前列表的末尾。而对 tuple 而言,即使没有定义 __iadd__ 方法,使用 "+=" 也会委托给 __add__ 方法进行运算返回一个新的 tuple 对象。
从设计层面考虑,Vector 应当与元组一致,被设计成不可变类型,即每次对向量进行运算后生成一个新的向量。站在函数式编程的角度,这种设计无副作用(不在函数内部修改传入参数状态),从而避免一些难以预料的问题。因此对于不可变类型,一定不能实现就地特殊方法。对 Vector 使用 "+=" 运算符会调用现有的 __add__ 方法生成一个新的 Vector 实例。v1 += (1, 1) 与 v1 = v1 + (1, 1) 行为一致。
>>> v1 = Vector([1, 2])
>>> id(v1)
4360163280
>>> v1 += (1, 1)
>>> v1
(2, 3)
>>> id(v1)
4359691376附录:代码
vector.py
import itertools
from array import array
from collections.abc import Iterable
class Vector:
def __init__(self, components: Iterable):
self._components = array('i', components)
def __iter__(self):
return iter(self._components)
def __len__(self):
return len(self._components)
def __repr__(self):
return str(tuple(self._components))
def __eq__(self, other):
return len(self) == len(other) and all(a == b for a, b in zip(self, other))
def __add__(self, other):
try:
pairs = itertools.zip_longest(self, other, fillvalue=0)
return Vector(a + b for a, b in pairs)
except TypeError:
return NotImplemented
def __radd__(self, other):
return self + othervector_test.py
from vector import Vector
class TestVector:
def test_should_compare_two_vectors_with_override_compare_operators(self):
v1 = Vector([1, 2])
v2 = Vector((1, 2))
v3 = Vector([2, 3])
v4 = Vector([2, 3, 4])
assert v1 == v2
assert v3 != v2
assert v4 != v3
assert (1, 2) == v2
assert v2 == [1, 2]
def test_should_add_two_same_dimension_vectors_with_override_add_operator(self):
v1 = Vector([1, 2])
v2 = Vector((1, 3))
result = Vector([2, 5])
assert result == v1 + v2
def test_should_add_two_different_dimension_vectors_with_override_add_operator(self):
v1 = Vector([1, 2])
v2 = Vector((1, 1, 1))
result = Vector([2, 3, 1])
assert result == v1 + v2
def test_should_add_vector_and_iterable_with_override_add_operator(self):
v1 = Vector([1, 2])
assert v1 + (1, 1) == (2, 3)
assert v1 + [1, 1, 1] == (2, 3, 1)
def test_should_add_iterable_and_vector_with_override_radd_method(self):
v1 = Vector([1, 2])
assert (1, 1) + v1 == (2, 3)
assert [1, 1, 1] + v1 == (2, 3, 1)
def test_should_create_new_vector_when_use_incremental_add_operator(self):
v1 = Vector([1, 2])
id1 = id(v1)
v1 += (1, 1)
assert id(v1) != id1附录:常见可重载运算符
一元运算符

二元运算符
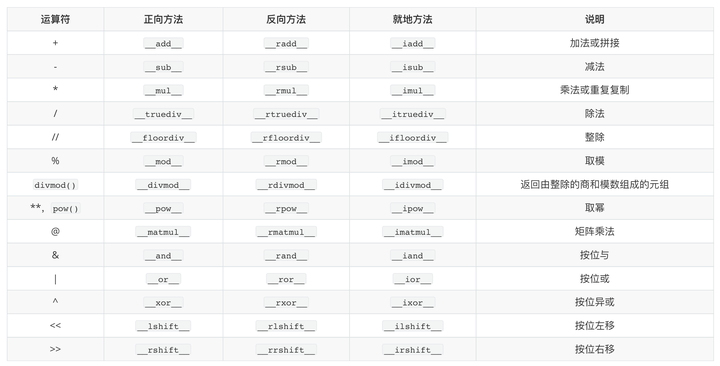
比较运算符


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验
· 百万级群聊的设计实践
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
· 永远不要相信用户的输入:从 SQL 注入攻防看输入验证的重要性
2017-11-22 (转)iptables简介
2017-11-22 (转)linux passwd批量修改用户密码