

(转)python路径操作新标准:pathlib 模块
原文:https://zhuanlan.zhihu.com/p/139783331
之前如果要使用 python 操作文件路径,我总是会条件反射导入 os.path。 而现在,我会更加喜欢用新式的 pathlib, 虽然用得还是没有 os.path 熟练,但是以后会坚持使用。
pathlib 库从 python3.4 开始,到 python3.6 已经比较成熟。如果你的新项目可以直接用 3.6 以上,建议用 pathlib。相比于老式的 os.path 有几个优势:
- 老的路径操作函数管理比较混乱,有的是导入 os, 有的又是在 os.path 当中,而新的用法统一可以用 pathlib 管理。
- 老用法在处理不同操作系统 win,mac 以及 linux 之间很吃力。换了操作系统常常要改代码,还经常需要进行一些额外操作。
- 老用法主要是函数形式,返回的数据类型通常是字符串。但是路径和字符串并不等价,所以在使用 os 操作路径的时候常常还要引入其他类库协助操作。新用法是面向对象,处理起来更灵活方便。
- pathlib 简化了很多操作,用起来更轻松。
举个例子, 把所有的 txt 文本全部移动到 archive 目录当中(archive 目录必须存在)。
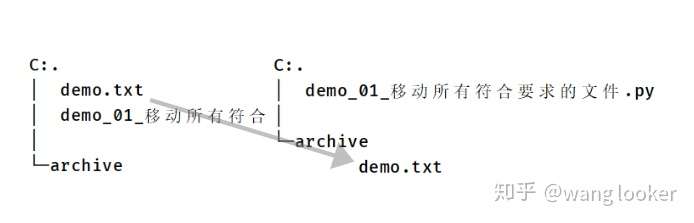
使用原来的用法:
import glob
import os
import shutil
# 获取运行目录下所有的 txt 文件。注意:不是这个文件目录下
print(glob.glob('*.txt'))
for file_name in glob.glob('*.txt'):
new_path = os.path.join('archive', file_name)
shutil.move(file_name, new_path)新的写法:
from pathlib import Path
Path("demo.txt").replace('archive/demo.txt')
这篇文章列举了 pathlib 的主要用法,细节知识有点多,我只会介绍 pathlib 的用法,不会每个都列举和 os 的区别。但是我会在文章最后放上主要操作使用 pathlib 和 os 的对比图。
最主要的路径操作,你可以参考国外一位大神总结的图:

1 路径获取
- 获取当前工作目录
>>> import pathlib
>>> pathlib.Path.cwd()
C:\Users\me\study
# WindowsPath('C:\Users\me\study')虽然在这里打印出来的很像一个字符串,但实际上得到的是一个 WindowsPath('C:\Users\me\study')对象。显示内容由 Path 类的 __repr__ 定义。
注意
工作目录是在哪个目录下运行你的程序,不是项目目录。
如果你只想得到字符串表示,不想要 WindowsPath 对象,可以用 str() 转化:
>>> str(pathlib.Path.cwd())
C:\Users\me\study- 获取用户 home 目录。
下面的例子因为基本都是使用 pathlib 下面的 Path 类,所以可以换一种导入方式。
from pathlib import Path
>>> Path.home()
c:\Users\me- 获取当前文件路径
>>> Path(__file__)
demo_01.py在 pycharm 中右击运行和在 cmd 运行的结果会不同。pycharm 会显示全路径,cmd 运行只会显示工作目录下的相对路径。如果想统一,可以添加后缀 .resolve() 转化成绝对路径,这个在后面还会提到。

- 获取任意字符串路径
>>> Path('subdir/demo_02.py')
subdir\demo_02.py
>>> Path('c:d:y/rad.txt')
c:d:y\rad.txt这里需要注意 2 点:
- 不管字符串使用的是正斜杠
/还是反斜杠\, 在 windows 系统里,得到的路径都是反斜杠\, pathlib 会根据操作系统智能处理。 - 第二个例子中字符串会被
/分割,c:d:y会被当做一个目录名字,pathlib 不会去判断这个文件真的存在哦。
- 获取绝对路径
只需要在任意路径对象后添加方法 .resolve() 就能获取路径的绝对路径。如果填入的路径是相对路径(windows 下没有盘符,linux 没有 / 开头),则会在当前工作目录后添加路径。如果是已经是绝对路径,则只会根据操作系统优化表达。
>>> file = Path('archive/demo.txt')
>>> file
archive\demo.txt
>>> file.resolve()
C:\Users\me\study\archive\demo.txt- 获取文件属性
文件属性比如文件大小,创建时间,修改时间等等。
file = Path('archive/demo.txt')
print(file.stat())
print(file.stat().st_size)
print(file.stat().st_atime)
print(file.stat().st_ctime)
print(file.stat().st_mtime)找出最后修改的文件的例子:
>>> path = Path.cwd()
>>> max(
[(f.stat().st_mtime, f)
for f in path.iterdir()
if f.is_file()]
)
1589171135.860173 C:\Users\me\study\demo_03.py
2 路径组成部分
获取路径的组成部分非常方便:
- .name 文件名,包含后缀名,如果是目录则获取目录名。
- .stem 文件名,不包含后缀。
- .suffix 后缀,比如
.txt,.png。 - .parent 父级目录,相当于
cd .. - .anchor 锚,目录前面的部分
C:\或者/。
>>> file = Path('archive/demo.txt')
>>> file.name
demo.txt
>>> file.stem
demo
>>> file.suffix
.txt
>>> file.parent
C:\Users\me\study\archive
>>> file.anchor
'C:\'
- 获取上一级目录
>>> file = Path('archive/demo.txt')
>>> file.parent
archive获取上 2 级 和 3 级目录会有点问题。因为传入的是一个相对路径,上 3 级已经无法往上了,所以还是会停留在工作目录。所以你需要确保你的路径有这么多层级。
>>> file.parent.parent
.
>>> file.parent.parent.parent
.- 获取所有的上级目录:
>>> file.parents
<WindowsPath.parents>
>>> list(file.parents)
[WindowsPath('archive'), WindowsPath('.')]- 父级目录的另一种表示方法:
>>> file.parents[0]
archive如果路径是在当前工作目录下的子目录,最好转化成绝对路径再获取上层目录:
>>> file.resolve().parents[4]
C:\Users
# 不能使用负数在 os 模块中获取上 3 级目录简直令人奔溃,需要重复使用 dirname 函数,使用 pathlib 的 parent 可以极大简单化操作:
>>> import os
>>> os.path.dirname(file)- 相对其他某个路径的结果:
>>> file.relative_to('archive')
dmeo.txt3 子路径扫描
- dir_path.iterdir() 可以扫描某个目录下的所有路径(文件和子目录), 打印的会是处理过的绝对路径。
>>> cwd = Path.cwd()
>>> [path for path in cwd.iterdir() if cwd.is_dir()]
[
WindowsPath('C:/Users/me/study/archive'),
WindowsPath('C:/Users/me/study/demo_01.py'),
WindowsPath('C:/Users/me/study/new_archive')
]
- 使用 iterdir() 可以统计目录下的不同文件类型:
>>> path = Path.cwd()
>>> files = [f.suffix for f in path.iterdir() if f.is_file()]
>>> collections.Counter(files)
Counter({'.py': 3, '.txt': 1})
- 查找目录下的指定文件 glob 。
使用模式匹配(正则表达式)匹配指定的路径。正则表达式不熟练的可以查看 这个教程,真的让我学会了正则表达式。glob 只会匹配当前目录下, rglob 会递归所有子目录。下面这个例子,demo.txt 在 archive 子目录下。所以用 glob 找到的是空列表,rglob 可以找到。glob 得到的是一个生成器,可以通过 list() 转化成列表。
>>> cwd = Path.cwd()
>>> list(cwd.glob('*.txt'))
[]
>>> list(cwd.rglob('*.txt'))
[WindowsPath('C:/Users/me/study/archive/demo.txt')]- 检查路径是否符合规则 match
>>> file = Path('/archive/demo.txt')
>>> file.match('*.txt')
True4 路径拼接
pathlib 支持用 / 拼接路径。熟悉魔术方法的同学应该很容易理解其中的原理。
>>> Path.home() / 'dir' / 'file.txt'
C:\Users\me\dir\file.txt如果用不惯 / ,也可以用类似 os.path.join 的方法:
>>> Path.home().joinpath('dir', 'file.txt')
C:\Users\me\dir\file.txt5 路径测试(判断)
- 是否为文件
>>> Path("archive/demo.txt").is_file()
True
>>> Path("archive/demo.txt").parent.is_file()
False- 是否为文件夹 (目录)
>>> Path("archive/demo.txt").is_dir()
False
>>> Path("archive/demo.txt").parent.is_dir()
True- 是否存在
>>> Path("archive/demo.txt").exists
True
>>> Path("archive/dem.txt").exists
False6 文件操作
- 创建文件 touch
>>> file = Path('hello.txt')
>>> file.touch(exist_ok=True)
None
>>> file.touch(exist_ok=False)
FileExistsError: [Errno 17] File exists: 'hello.txt'exist_ok 表示当文件已经存在时,程序的反应。如果为 True,文件存在时,不进行任何操作。如果为 False, 则会报 FileExistsError 错误。
- 创建目录 path.mkdir
用 os 创建目录分为 2 个函数 : mkdir() 和 makedirs()。 mkdir() 一次只能创建一级目录, makedirs() 可以同时创建多级目录:
>>> os.mkdir('dir/subdir/3dir')
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'dir/subdir/3dir'
>>> os.makedirs('dir/subdir/3dir')
None
使用 pathlib 只需要用 path.mkdir() 函数就可以。它提供了 parents 参数,设置为 True 可以创建多级目录;不设置则只能创建 一层:
>>> path = Path('/dir/subdir/3dir')
>>> path.mkdir()
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'dir/subdir/3dir'
>>> path.mkdir(parents=True)
None
- 删除目录 path.rmdir()
删除目录非常危险,并且没有提示,一定要谨慎操作。一次只删除一级目录,且当前目录必须为空。
>>> path = Path('dir/subdir/3dir')
>>> path.rmdir()
None- 删除文件 path.unlink, 危险操作。
>>> path = Path('archive/demo.txt')
>>> path.unlink()- 打开文件
使用 open() 函数打开文件时,如果需要传入文件路径。可以用字符串作为参数传入:
with open('archive/demo.txt') as f:
print(f.read())
也可以传入 Path 对象:
file_path = Path('archive/demo.txt')
with open(file_path) as f:
print(f.read())
如果经常使用 pathlib,可以在获取到 Path 路径以后直接调用 path.open() 方法。至于到底用哪一个,其实不必太在意,因为 path.open() 也是调用内置函数 open()。
file = Path('archive/demo.txt')
with file.open() as f:
print(f.read())
不过 pathlib 对读取和写入进行了简单的封装,不再需要重复去打开文件和管理文件的关闭了。
- .read_text() 读取文本
- .read_bytes() 读取 bytes
- .write_text() 写入文本
- .write_bytes() 写入 tytes
>>> file_path = Path('archive/demo.txt')
>>> file_path.read_text() # 读取文本
'text in the demo.txt'
>>> file_path.read_bytes() # 读取 bytes
b'text in the demo.txt'
>>> file.write_text('new words') # 写入文本
9
>>> file.write_bytes(b'new words') # 写入 bytes
9
注意
file.write 操作使用的是 w 模式,如果之前已经有文件内容,将会被覆盖。
- 移动文件
txt_path = Path('archive/demo.txt')
res = txt_path.replace('new_demo.txt')
print(res)
这个操作会把 archive 目录下的 demo.txt 文件移动到当前工作目录,并重命名为 new_demo.txt。
移动操作支持的功能很受限。比如当前工作目录如果已经有一个 new_demo.txt 的文件,则里面的内容都会被覆盖。还有,如果需要移动到其他目录下,则该目录必须要存在,否则会报错:
# new_archive 目录必须存在,否则会报错
txt_path = Path('archive/demo.txt')
res = txt_path.replace('new_archive/new_demo.txt')
print(res)为了避免出现同名文件里的内容被覆盖,通常需要进行额外处理。比如判断同名文件不能存在,但是父级目录必须存在;或者判断父级目录不存在时,创建该目录。
dest = Path('new_demo.txt')
if (not dest.exists()) and dest.parent.exists():
txt_path.replace(dest)
- 重命名文件
txt_path = Path('archive/demo.txt')
new_file = txt_path.with_name('new.txt')
txt_path.replace(new_file)- 修改后缀名
txt_path = Path('archive/demo.txt')
new_file = txt_path.with_suffix('.json')
txt_path.replace(new_file)注意
不管是移动文件还是删除文件,都不会给任何提示。所以在进行此类操作的时候要特别小心。
对文件进行操作最好还是用 shutil 模块。
参考文献


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验
· 百万级群聊的设计实践
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
· 永远不要相信用户的输入:从 SQL 注入攻防看输入验证的重要性
2017-10-11 (转)如何修改windows下mysql的字符集
2017-10-11 (转)修改及查看mysql数据库的字符集
2017-10-11 (转) MySQL分区与传统的分库分表
2017-10-11 技术链接