
11、C预处理
翻译程序
在预处理之前,编译器必须对该程序进行一些翻译处理。
-
第一,编译器把源代码中出现的字符映射到源字符集。该过程处理多字节字符和三字符序列:字符扩展让C更加国际化
-
第二,编译器定位每个反斜杠后面跟着换行符的实例,并删除它们。也就是说,把下面两个物理行(physical line):
printf("That's wond\ erful!\n");转换成一个逻辑行(logical line):
printf("That's wonderful\n!");由于预处理表达式的长度必须是一个逻辑行,所以这一步为预处理器做好了准备工作。一个逻辑行可以是多个物理行。
-
第三,编译器把文本划分成预处理记号序列、空白序列和注释序列(记号是由空格、制表符或换行符分隔的项,详见16.2.1)。
这里要注意的是,编译器将用一个空格字符替换每一条注释。因此,下面的代码:
int/*这看起来并不像一个空格*/fox;将变成:
int fox;而且,实现可以用一个空格替换所有的空白字符序列(不包括换行符)。最后,程序已经准备好进入预处理阶段,预处理器查找一行中以#号开始的预处理指令。
明示常量:#define
指令可以出现在源文件的任何地方,其定义从指令出现的地方到该文件末尾有效。
我们大量使用#define指令来定义明示常量(maniestconstant)(也叫做符号常量)
#define基本使用
反斜杠可以把定义延续到下一行
#define OW "Hello \
world"
在预处理前,编译器会把多行物理行处理为一行逻辑行:
#define OW "Hello world"
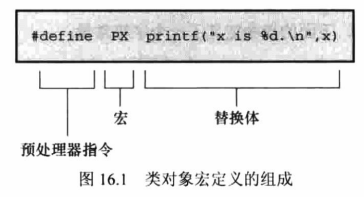
#define的组成
每行#define(逻辑行)都由3部分组成
-
第1部分是#define指令本身。
-
第2部分是选定的缩写也称为宏。
-
有些宏代表值,这些宏被称为类对象宏(objec1-ikemacro)。
-
C语言还有类函数宏(fumcrion-like macro),如下:
#define PX printf("x is %d.\n", x) int main() { int x = 2; PX; // 替换后变成了 printf("x is %d.\n", x); return 0; } // 运行结果 /* x is 2. */宏可以表示任何字符串,甚至可以表示整个C表达式
注意:宏的名称中不允许有空格,而且必须遵循C变量的命名规则:只能使用字符、数字和下划线(_)字符,而且首字符不能是数字。
-
-
第3部分(指令行的其余部分)称为替换列表或替换体。
一旦预处理器在程序中找到宏的示实例后,就会用替换体代替该宏(也有例外,稍后解释)。
从宏变成最终替换文本的过程称为宏展开(macroexpansion)。
注意,可以在#define 行使用标准C注释。如前所述,每条注释都会被一个空格代替。
宏定义还可以包含其他宏
有些编译器不支持这种嵌套功能
般而言,预处理器发现程序中的宏后,会用宏等价的替换文本进行替换。如果替换的字符串中还包含宏,则继续替换这些宏。唯一例外的是双引号中的宏
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define DS1 "hello"
#define DS2 "world"
#define PX printf("DS1:%s, DS2:%s\n", DS1, DS2)
int main()
{
PX;
return 0;
}
// 运行结果
/*
DS1:hello, DS2:world
*/
字符常量
对于绝大部分数字常量,应该使用字符常量。
- 如果在算式中用字符常量代替数字,常量名能更清楚地表达该数字的含义。如果是表示数组大小的数字,用符号常量后更容易改变数组的大小和循环次数。如果数字是系统代码(如,EOF),用符号常量表示的代码更容易移植(只需改变EOF的定义)。助记、易更改、可移植,这些都是符号常量很有价值的特性。
C语言现在也支持const关键字,提供了更灵活的方法。用const可以创建在程序运行过程中不能改变的变量,可具有文件作用域或块作用域。另一方面,宏常量可用于指定标准数组的大小和const 变量的初始值。
#define LIMIT 20
const int LIM=50;
static int datal[LIMIT]; //有效
static int data2[LIM]; //无效
const int IM2=2*LIMIT; //有效
const int LIM3=2*LIM; //无效
这里解释一下上面代码中的“无效”注释。在C中,非自动数组的大小应该是整型常量表达式,不包括const 声明的值(这也是C++和C的区别之一,在C++中可以把const 值作为常量表达式的一部分)。
记号型字符串
在C语言中,宏的替换体可以被视为记号型字符串而不是字符型字符串。C预处理器将宏定义中的替换体视为一系列单独的"词",这些词之间用空白分隔开。这些词可以是关键字、标识符、运算符、常量等,而不是简单的字符序列。
当预处理器替换宏时,它会根据宏定义中的替换体将宏调用中的标识符替换为相应的记号。这种替换是基于记号的,而不是基于字符的。这种记号级别的替换使得宏在展开时可以保持语法正确性。
因此,从技术角度来看,宏的替换体可以被看作是记号型字符串,其中每个记号代表一个独立的词或标记,而不是简单的字符序列。这种记号级别的处理有助于确保宏替换的正确性和语法性。
在C语言中,记号型字符串和字符型字符串有一些区别。
- 记号型字符串:
- 记号型字符串是由特定的符号或标记组成的字符串,通常用于表示特定的含义或进行特定的操作。
- 记号型字符串通常不包含可见字符,而是由特殊字符或符号组成。
- 记号型字符串在C语言中通常用于词法分析、编译器设计等领域。
- 字符型字符串(也称为C字符串):
- 字符型字符串是由字符组成的以空字符 '\0' 结尾的字符数组。
- 字符型字符串在C语言中用于表示文本数据,可以包含可见字符(如字母、数字、标点符号等)。
- 字符型字符串在C语言中有许多标准库函数支持,如strlen()、strcpy()、strcat()等。
总的来说,记号型字符串和字符型字符串在C语言中的使用场景和特点是不同的。记号型字符串通常用于编程语言设计和编译原理等领域,而字符型字符串则是用于处理文本数据和字符串操作。
如下面例子:
#define FOUR 2*3 // 该宏定义只有一个记号:2*3序列
#define SIX 2 * 3 // 该宏定义有三个记号:2、*、3
#define中使用参数
在#define 中使用参数可以创建外形和作用与函数类似的类函数宏。带有参数的宏看上去很像函数,因为这样的宏也使用圆括号。类函数宏定义的圆括号中可以有一个或多个参数,随后这些参数出现在替换换体中,如下图

使用示例:
#define SQUARE(x) x*x
int z = SQUART(2); // 替换后的语句为:int z = 2*2
这里,SQUARE是宏标识符,SQUARE(x)中x的是宏参数,x*x是替换列表。程序中出现SQUARE(X)的地方都会被 x*x替换。
这与前面的示例不同,使用该宏时,既可以用x,也可以用其他符号宏定义中的x由宏调用中的符号代替。因此,SOUARE(2)替换为2*2,x实际上起到参数的作用。
注意:宏参数与函数参数不完全相同
#define SQUARE(x) x*x
int x = 5;
printf("%d\n", SQUARE(x)); // 该语句打印的结果:25
printf("%d\n", SQUARE(2)); // 该语句打印的结果:4
这两行与预期相符
printf("%d\n", SQUARE(x + 2)); // 该语句打印的结果:17
程序中x等于5,x+2应该等于7,所以可能认为SQUARE(x + 2)应该是7*7,即49,但是输出的却是17
这是因为预处理器不做运算、不求值,只替换字符序列。所以预处理器把出现x的地方都替换成x+2。因此x*x变成了 x+2*x+2 = 5+2*5+2 = 17
想要解决上述问题,则需要添加圆括号来规定运算顺序:
#define SQUARE(x) (x)*(x) int x = 5; SQUARE(x+2); // 替换后的语句为:(x+2)*(x+2);
printf("%d\n", 100 / SQUARE(2)); // 该语句打印的结果:100
出现该问题的原因也是运算优先级的问题:100 / 2*2 = 100
解决该问题就再加上一个圆括号:
#define SQUARE(x) ((x)*(x)) int x = 5; 100 / SQUARE(2); // 替换后的语句为:100 / ((2)*(2));
printf("%d\n", SQUARE(++x)); // 该语句打印的结果:42
尽管如此,这样做还是无法避免这种情况的问题。
SQUARE(++x)变成了++x*++x,递增了两次x,一次在乘法运算之前,一次在乘法运算之后:
++x*++x = 6*7 = 42由于标准并未对这类运算规定顺序,所以有些编译器得7*6。而有些编译器可能在乘法运算之前已经递增了x,所以 7*7得49。在C标准中,对该表达式求值的这种情况称为未定义行为。无论哪种情况,x的开始值都是5,虽然从代码上看只递增了一次,但是x的最终值是7。
解决这个问题最简单的方法是,避免用++x作为宏参数。一般而言,不要在宏中使用递增或递减运算符。但是,++x可作为函数参数,因为编译器会对++x求值得5后,再把5传递给函数。
用宏参数创建字符串:#运算符
C允许再字符串中包含宏参数。在类函数宏的替换体中,#号作为一个预处理运算符,可以把记号转化为字符串。
假设 x 是一个宏的形参,那么#x 就是转换为字符串 "x"的形参名。这个过程称为字符串化(stringizing)。如下例:
#define PX(x) printf("宏形参为:"\#x"。结果为:%d\n", ((x) * (x)) ) // 字符串化
int x = 5;
PX(x);
PX(x + 2);
// 运行结果
/*
宏形参为:x。结果为:25
宏形参为:x + 2。结果为:49
*/
注意:完整的是: "#x" ,一定不要忘记双引号
预处理粘合剂:##运算符
##运算符可用于类函数宏的替换部分,还可用于对象宏的替换部分。##运算符把两个记号组合成一个记号。例如,可以这样做:
#define XNAME(n) x ## n
int XNAME(4) = 12; // 宏展开后的语句为:int x4 = 12;
将宏 XNAME(4) 展开后为:x4
变参宏:...和__VA_ARGS__
一些函数(如 printf())接受数量可变的参数。stdvar.h头文件也提供了工具,让用户可以自定义带可变参数的函数。
C99/C11也对宏提供了这样的工具。
通过把宏参数列表中最后的参数写成省略号(即,3个点...)来实现这一功能。这样,预定义宏__VA_ARGS__可用在替换部分中,表明省略号代表什么。例如,下面的定义:
#define PR(...) printf(__VA_ARGS__)
调用该宏
PR("hello"); // __VA_ARGS__展开为一个参数:"hello"
PR("a = %d, b = %f", a, b); // __VA_ARGS__展开为三个参数:"a = %d, b = %f"、a、b
// 所以展开后的代码为
printf("hello");
printf("a = %d, b = %f", a, b);
文件包含:#incldue
查找文件
include 指令有两种形式:
#include <stdio.h> // 文件名在尖括号中
#include "mystuff.h" // 文件名在双引号中
#include "/C:/user/biff/p.h" // 查找指定路径下的文件
在UNIX系统中,尖括号告诉预处理器在标准系统目录中查找该文件
双引号告诉预处理器首先在当前目录中(或文件名中指定的其他目录)查找该文件,如果未找到再查找标准系统目录:
集成开发环境(IDE)也有标准路径或系统头文件的路径。
许多集成开发环境提供菜单选项,指定用尖括号时的查找路径。在UNIX中,使用双引号意味着先查找本地目录,但是具体查找哪个目录取决于编译器的设定。有些编译器会搜索源代码文件所在的目录,有些编译器则搜索当前的工作目录,还有些搜索项目文件所在的目录。
头文件
C语言习惯用.h后缀表示头文件,这些文件包含需要放在程序顶部的信息。头文件经常包含一些预处理器指令。有些头文件(如stdio.h)由系统提供,当然你也可以创建自己的头文件。
头文件的常见内容极其作用
浏览任何一个标准头文件都可以了解头文件的基本信息。头文件中最常用的形式如下。
-
明示常量:例如,stdio.h中定义的 EOF、NULL和 BUFSIZE(标准 I/0 缓冲区大小)。
-
宏函数:例如,getc(stdin)通常用 getchar()定义,而 getc()经常用于定义较复杂的宏,头文件 ctype.h通常包含 ctype 系列函数的宏定义。
-
函数声明:例如,string.h头文件(一些旧的系统中是strings.h)包含字符串函数系列的函数声明。在ANSIC和后面的标准中,函数声明都是函数原型形式。
-
结构模版定义:标准 I/O函数使用 FILE结构,该结构中包含了文件和与文件缓冲区相关的信息。FILE 结构在头文件stdio.h中。
-
类型定义:标准I/O函数使用指向FILE的指针作为参数。通常,stdio.h用#define 或typedef把 FILE 定义为指向结构的指针。类似地,sizet和timet类型也定义在头文件中。
-
使用头文件声明外部变量供其他文件共享:
int status = 0; // 该变量具有文件作用域,在源文件中然后在与源代码文件相关联的头文件中进行引用式声明
extern int status; // 在头文件中
重定义宏:#undef
#undef指令用于取消已定义的 #define指令
#define LIMIT 100
#undef LIMIT // 移除了上面的定义,现在可以把LIMIT重新定义一个新值
即使原来没有定义LIMIT,取消LIMIT的定义仍然有效。
如果想使用一个名称,又不确定之前是否已经用过,为安全起见,可以用#undef 指令取消该名字的定义。
注意:#define 宏的作用域从它在文件中的声明处开始,直到用#undef指令取消宏为止,或延伸至文件尾(以二者中先满足的条件作为宏作用域的结束)。另外还要注意,如果宏通过头文件引入,那么#define 在文件中的位置取决于#include 指令的位置。
条件编译
#ifdef、#else、#endif指令
-
#ifdef指令说明,如果预处理器已定义了后面的标识符,则执行#else 或#endif 指令之前的所有指令并编译所有C代码(先出现哪个指令就执行到哪里)。
-
如果预处理器未定义#ifdef后面的标识符,且有#else指令,则执行#else 和#endif 指令之间的所有代码。
-
#ifdef、#else很像C的if、else。两者的主要区别是,预处理器不识别用于标记块的花括号( {}),因此它使用#e1se(如果需要)和#endif(必须存在)来标记指令块。这些指令结构可以嵌套。也可以用这些指令标记C语句块。
使用示例
#ifdef MA // 判断预处理器是否定义了标识符:MA
// 如果定义了标识符:MA,则执行下面语句
#define STA 5
#else // 这个指令不是必须的
// 如果没有定义标识符:MA,则执行下面语句
#define MA 2
#endif // 该指令是必须要有的,与#ifdef配套,组成一个块
注意:有的旧编译器可能不支持缩进,必须左对齐所有指令
#ifndef指令
#ifndef指令与#ifdef指令的用法类似,也是和#else、#endif一起使用,但是他们的逻辑相反。#ifndef指令判断后面的标识符是否是未定义的
使用示例
#ifndef MA // 判断预处理器是否定义了标识符:MA
// 如果没有定义了标识符:MA,则执行下面语句
#define MA 2
#else // 这个指令不是必须的
// 如果定义了标识符:MA,则执行下面语句
#define STA 5
#endif // 该指令是必须要有的,与#ifndef配套,组成一个块
该指令的常用于防止多次包含一个文件(假设下面是头文件:things.h的部分内容):
#ifndef THINGS_H_
#define THINGS_H_
/* 文件的其他内容 */
...
#endif
当预处理器首次发现该文件被包含时,THINGS_H_是未定义的,所以定义了THINGS_H_,并接着处理该文件的其他部分。当预处理器第2次发现该文件被包含时,THINGS_H_是已定义的,所以预处理器跳过了该文件的其他部分。
#if和#elif指令
#if指令与C语言中的 if 类似,#elif 指令与C语言中的 else if 类似
#if后面跟整型常量表达式,如果表达式为非零,则表达式为真。可以在指令中使用C的关系运算符和逻辑运算符。如下
#if SYS == 1
#include "lbm.h"
#elif SYS == 2
#include "vax.h"
#elif SYS == 3
#include "mac.h"
#else
#include "gen.h"
#endif
这两个代码基本等价
if(SYS == 1)
{
#inlcude "lbm.h"
}
else if(SYS == 2)
{
#include "vax.h"
}
else if(SYS == 3)
{
#include "mac.h"
}
else
{
#include "gen.h"
}
预定义宏
| 宏 | 含义 |
|---|---|
__DATE__ |
预处理的日期(“Mmm dd yyyy”形式的字面量) |
__FILE__ |
获取当前源文件的路径 |
__LINE__ |
表示当前所处位置的代码行数 |
__STDC__ |
设置为1时,表示遵循C标准 |
__STDC_HOSTED__ |
本机环境设置为1;否则设置为0 |
__STDC_VERSION__ |
支持C99标准设置为:199901L;支持C11标准设置为:201112L |
__TIME__ |
翻译代码的时间,格式为:"hh:mm:ss" |
C99标准提供一个名为__func__ 的预定义标识符,他表示包含了他的函数的函数名的字符串
所以__func__ 必须具有函数作用域,而从本质上看宏具有文件作用域。因此,__func__ 是C语言的预定义标识符,而不是预定义宏。
对上面部分预定义宏进行了演示
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
void my_func()
{
printf("当前代码所处的行是:%d\n", __LINE__);
printf("当前函数的函数名是:%s\n", __func__);
}
int main()
{
printf("当前源文件的路径是:%s.\n", __FILE__);
printf("当前代码预处理日期:%s.\n", __DATE__);
printf("当前代码翻译的时间:%s.\n", __TIME__);
printf("当前代码所处的行是:%d\n", __LINE__);
printf("当前函数的函数名是:%s\n", __func__);
my_func();
return 0;
}
// 运行结果
/*
当前源文件的路径是:E:\My_Apps\CODE_word\C\01\main.c.
当前代码预处理日期:Apr 12 2024.
当前代码翻译的时间:02:48:33.
当前代码所处的行是:15
当前函数的函数名是:main
当前代码所处的行是:6
当前函数的函数名是:my_func
*/
#line和#error
#line指令可以重置 __LINE__和__FILE__宏报告的行号和文件名。如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
printf("#line指令重置前的源文件的路径是:%s.\n", __FILE__);
printf("#line指令重置前的代码所处的行是:%d\n", __LINE__);
printf("#line指令重置前的代码所处的行是:%d\n", __LINE__);
#line 100 "C:/ur/aaa.c"
printf("经过#line指令重置后的代码所处的行是:%d\n", __LINE__);
printf("经过#line指令重置后的代码所处的行是:%d\n", __LINE__);
printf("经过#line指令重置后的源文件的路径是:%s.\n", __FILE__);
printf("经过#line指令重置后的代码所处的行是:%d\n", __LINE__);
return 0;
}
// 运行结果
/*
#line指令重置前的源文件的路径是:E:\My_Apps\CODE_word\C\01\main.c.
#line指令重置前的代码所处的行是:7
#line指令重置前的代码所处的行是:8
经过#line指令重置后的代码所处的行是:100
经过#line指令重置后的代码所处的行是:101
经过#line指令重置后的源文件的路径是:C:/ur/aaa.c.
经过#line指令重置后的代码所处的行是:103
*/
#line 100 // 将行号重置为100
#line "aaa.c" // 将文件名重置为 aaa.c
#line 100 "aaa.c" // 将行号重置为100,文件名重置为 aaa.c
#error指令让处理器发出一条错误消息。该消息包含指令中的文本。编译过程也会中断
#ifndef STU
// 如果没有定义STU这个宏,则报错并中断编译
#error No Def STU
#endif
#pragma
#pragma是C语言留给编译器生产厂商对 C 语言进行扩展了一个特殊的预处理指示字。这也就导致了一个问题, #pragma 在不同的编译器之间可能是无法移植的,这里只看几个常用的功能。
-
#pragma c9x on在开发C99时,标准被称为C9X,用上面编译指示,让编译器支持C9x
-
#pragma once用于保证头文件只被编译一次
#pragma once 是编译器相关的,不一定被支持
前面知道了条件编译也可以保证头文件只被编译一次,这两者的区别如下:
- #ifndef 这种方法是被C语音支持的。实际上并不是只包含一次头文件,而是包含多次,但是使用宏保证只嵌入一次到源代码中。虽然只嵌入一次,但还是包含了多次,编译器还是要多次处理
- #pragma once 告诉预处理器当前头文件只被编译一次,只要#include 一次,后面的#include 相同的头文件都不起作用,不会被处理,所以#pragma once效率更高
实际工程中#ifndef 使用跟多,因为#ifndef是被C语言支持的,所有的编译器都可以编译,但是对于#pragma once有些编译器不支持
-
#pragma message(messagestring)在编译期间,将一个文字串(messagestring)发送到标准输出窗口。如下例子:
#ifdef STU #pragma message("定义了宏:STU") #endif
泛型选择(C11)
泛型编程(generic programming)指哪些没有特定类型,但是一旦指定一种类型,就可以转换成指定类型的代码
C11新增了一种表达式,叫作泛型选择表达式(generic selection expression)。可以根据表达式的类型选择一个值。
泛型选择表达式不是预处理器指令,但是在一些泛型编程中他常用于#define宏定义的一部分。
使用示例
_Generic(x, int: 0, float: 1, double: 2, default: 3)
_Generic是C11的关键字。 _Generic 后面的圆括号中包含多个用逗号分隔的项。
第1个项是一个表达式,后面的每个项都由一个类型、一个冒号和一个值组成,如float:1。
第1个项的类型匹配哪个标签,整个表达式的值是该标签后面的值。
例如,假设上面表达式中x是int 类型的变量,x的类型匹配int:标签,那么整个表达式的值就是0。如果没有与类型匹配的标签,表达式的值就是 default:标签后面的值。
泛型选择语句与switch语句类似,只是前者用表达式的类型匹配标签,而后者用表达式的值匹配标签。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
int x = 2;
char c[10] = _Generic(x, int:"int", float : "float", default:"no");
printf("x的类型为:%s\n", c);
return 0;
}
// 运行结果
/*
x的类型为:int
*/
泛型选择语句和宏定义组合
#define MYTYPE(X) _Generic((X),\
int: "int",\
float: "float",\
double: "doule",\
default: "on def"\
)
宏必须定义为一条逻辑行,但是可以用\把一条逻辑行分隔成多条物理行。
上面的例子是对泛型选择表达式求值得字符串。
例如,对MYTYPE(5)求值得"int",因为值5的类型与int:标签匹配。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define MYTYPE(X) _Generic((X),\
int: "int",\
float: "float",\
default: "未定义的"\
)
int main()
{
int a = 2;
printf("a 的类型为:%s\n", MYTYPE(a));
printf("a*1.2f 的类型为:%s\n", MYTYPE(a * 1.2f));
printf("a*1.2 的类型为:%s\n", MYTYPE(a * 1.2));
return 0;
}
// 运行结果
/*
a 的类型为:int
a*1.2f 的类型为:float
a*1.2 的类型为:未定义的
*/
内联函数(C99)
通常函数调用都有一定的开销,因为函数的调用过程包括建立调用、传递参数、跳转到函数代码并返回。
内联函数(inline function)可以避免这样的开销
创建内联函数的定义有多种方法。标准规定具有内部链接的函数可以成为内联函数,还规定了内联函数的定义与调用该函数的代码必须在同一个文件中。
因此最简单的方法就是使用函数说明符inline和存储说明符static。通常内联函数应定义在首次使用他的文件中,所以内联函数也相当于函数原型。如下:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
inline static void eatline() // 内联函数的定义或声明
{
for (int i = 0; i < 3; i++)
{
printf("%d\n", i);
}
}
int main()
{
eatline(); // 调用内联函数
return 0;
}
编译器查看内联函数的定义(也是原型),可能会用函数体中的代码替换eatline()函数调用。也就是说,效果相当于在函数调用的位置输入函数体中的代码:
#define _CRT_SECURE_NO_WARNINGS #include <stdio.h> int main() { // 替换函数调用 for (int i = 0; i < 3; i++) { printf("%d\n", i); } return 0; }
内联函数应该比较短小,把较长的函数变成内联并未节约多少时间,因为执行代码的时间比调用代码的时间长的多
编译器优化内联函数必须知道该函数定义的内容
这意味着内联函数定义与函数调用必须在同一个文件中。鉴于此,一般情况下内联函数都具有内部链接。因此,如果程序有多个文件都要使用某个内联函数,那么这些文件中都必须包含该内联函数的定义。
最简单的做法是,把内联函数定义放入头文件,并在使用该内联函数的文件中包含该头文件即可。
// eatline.h
#ifndef EATLINE_H_
#define EATLINE_H_
inline static void eatline() // 内联函数的定义或声明
{
for (int i = 0; i < 3; i++)
{
printf("%d\n", i);
}
}
#endif
一般不在头文件中放置可执行代码,内联函数是个个例
_Noreturn函数(C11)
C99新增的关键字inline是唯一的函数说明符。C11新增了第二个函数说明符_Noreturn ,表明函数调用完成后不会在返回主调函数
注意:与void返回类型不同,void类型的函数在执行完毕后会返回主调函数,只是他不会提供返回值
exit()函数时_Noreturn函数的一个示例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号