第二次结对作业
| 作业要求 | 第二次结对作业:班级成绩表 |
|---|---|
| 作业目标 | 通过爬取在线动态网页信息进行解析,并通过一定的方式处理数据,输出到文档中 |
| 作业源代码 | https://gitee.com/liuihongyu/pair |
| 队员1 | 211806336 |
| 队员2 | 211806343 |
时间分布
-
需求分析0.5h
这次作业的需求很容易理解,就是阿荣想将所有同学课堂完成部分的成绩爬取下来,并计算每位同学在该课程中课堂完成部分获得的总分,
并以总分降序将所有的学信息输出到文档中,并计算最高经验值,最低经验值,平均经验值 -
代码实现6h
而代码写起来就没那么简单了,首先需要获得该课程中所有课堂完成部分的网址,并且将网址进行解析,获取所有学生的名单,以及学生所对应的每次课堂完成的分数,并进行相加
将所有学生信息以及对应的总分储存到对象数组中,并进行排序。还需要所有总分计算得出最高经验值,最低经验值,平均经验值并输出 -
代码92行
这92行写出了920行的感觉😥
互相评价
刘鸿宇:浪浪子可蒸流啤,总是能快速发现问题在了哪里,在网址解析的时候,对网址的数据分析能求同存异
王浪浪:原来屠龙勇士不止会屠龙,还会写代码,新知识的使用他很有一手

编码过程
-
1.保存header信息
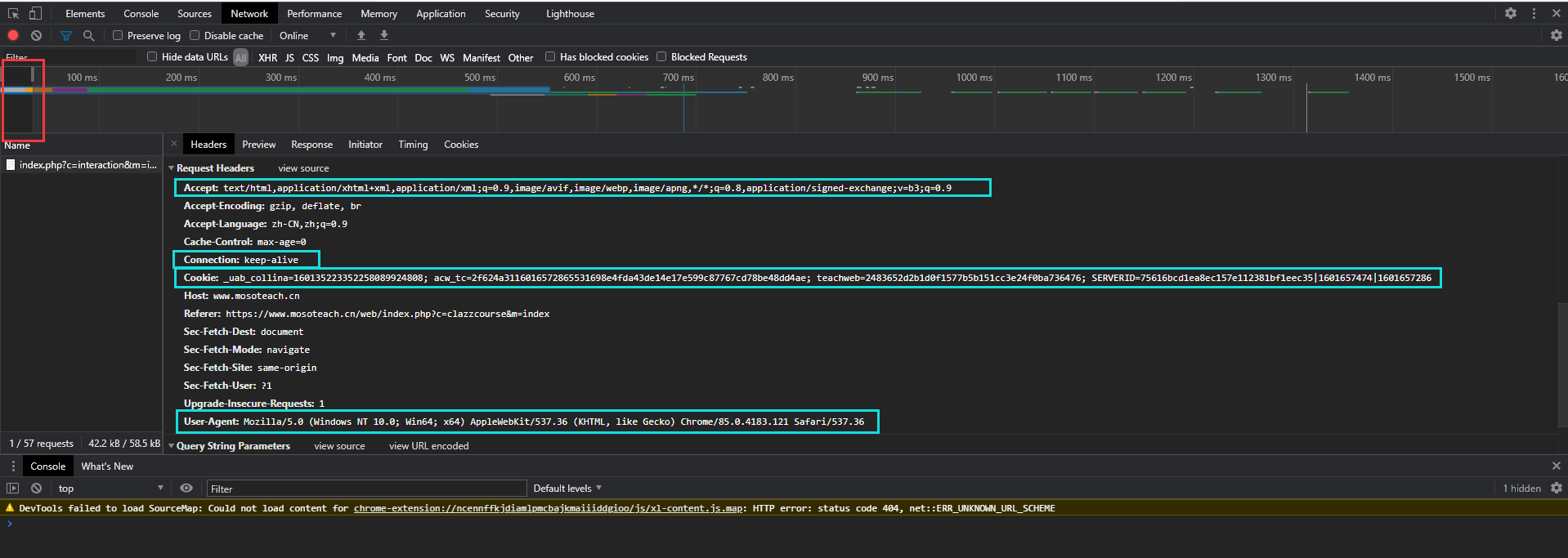
在网页中成功登陆后,打开开发者工具,刷新一下网页,就可以通过network获得header信息
查找一开始网页请求的内容,保存下cookie,就可以在执行代码的时候不会因为需要用户登录而进入不了需要的页面
其他的信息是可以模拟浏览器登录所请求的网址
将具体信息写入配置文件中
如果自己第一次打开代码能进入网站,而第二次却得到的是未登录的内容,那就需要去重新查找cookie了,因为cookie会更新,原本的cookie就不能用了
-
2.通过cookie登录在线的网页
#获取指定班级的主页信息
cf = configparser.ConfigParser()
cf.read(r"./resource/config.ini")
base_url = cf.get("URL", "url")
def html_data(url):
# 获取配置文件header和url信息
header = dict(cf.items("Header"))
#解决网址错误的问题
really_url = str(url).replace("&", "&")
# 解析网页
wb_data = requests.get(really_url, headers=header).text
soup = BeautifulSoup(wb_data, 'html.parser')
return soup
定义一个登录网页并获取网页信息的函数
在resource中的config.ini配置文件含有网址以及网页的头部信息
该函数可以通过传入网址参数用 BeautifulSoup 来解析出该网址的信息
因为要获取的网页不仅仅是主页,还有很多课堂完成部分的网页,这样只需要传入想要的网址参数就能得出信息,从而减少很多重复的步骤
至于为什么要解决网址错误问题,网址为什么会有错,之后会讲到
-
3.获取所有的课程网址
def course_url():
soup = html_data(base_url).decode("utf-8")
class_name = re.compile("data-url=\"(.*?)\">", re.S).findall(soup)
return class_name
定义一个获取所有课程网址的函数
需要获取课程的经验,我们先要获取课程的网址
要是一个个去保存网址那可挺累人的,这个函数可以帮我们自动获取网址

比如说我们想在主页网址中获得这次作业的网址,就可以通过data-url来查找
-
4.网址错误问题
当我们通过get_course_url()函数来获得网址时,再检查输出时发现确实能输出网址,但是网址错了

明明data-url打开就能正确,可这次通过正则获取出来的url却去火星了

对比了一下两者的网址,发现两者值都是相同的,但是&却被替换成了& amp;
原来转义字符成为了他的火箭,让他火星了
#解决网址错误的问题
really_url = str(url).replace("&", "&")
所以在传入网址时需要用这个来将转义字符替换回来
-
5.自定义一个保存学生信息的对象数组
class Student(object):
def __init__(self, name, num, score):
self.name = name
self.num = num
self.score = score
student_list = [Student]*99
并把学生数组的空间设置为99
-
6.从网页中获取学生的信息
def student_info():
# 获取学生姓名和学号
soup = html_data(course_url()[0]).decode("utf-8")
student_name = re.compile("<span style=\"font-size: 12px; color: #333;\">(.*?)</span>", re.S).findall(soup)
student_num = re.compile("<div style=\"line-height: 20px; font-size: 12px; color: #666;\">(.*?)</div>",
re.S).findall(soup)
# 将信息存入对象数组
for i in range(len(student_name)):
student_list[i] = Student(student_name[i].lstrip().rstrip(), student_num[i].lstrip().rstrip(), 0)
# 获取经验值
for i in range(len(course_url())):
soup = html_data(course_url()[i]).decode("utf-8")
work = re.compile("title=\".*课堂完成部分").findall(soup)
if len(work) > 0:
if work[0] in soup:
for k in range(len(student_name)):
soup2 = html_data(course_url()[i])
student = soup2.findAll(attrs={'class': 'homework-item'})
name = re.compile("<span style=\"font-size: 12px; color: #333;\">(.*?)<").findall(str(student[k]))
score = re.compile("最终得分:</span>\n<span style=\"color: #8FC31F\">(.*?) 分<", re.S).findall(
str(student[k]))
if name[0] == student_list[k].name:
for j in range(len(score)):
student_list[k].score += int(score[j])
搜索关键词部分是通过正则表达式搜索的
先获取学生的姓名和学号信息存入数组,并将分数默认为0
接下来通过找到网址->判断是否为课堂完成部分的作业->搜索分数->将分数与学生对应->将分数相加
作业就获得了需要的分数
因为这部分代码对很多个很大的文档进行了判断和循环,运行起来非常慢,之后(或许)会优化一下吧
-
7.将数据进行排序
def bubble_sort1(student_list):
for i in range(len(student_list) - 1):
for j in range(len(student_list) - i - 1):
if student_list[j].score < student_list[j + 1].score:
student_list[j], student_list[j + 1] = student_list[j + 1], student_list[j]
return student_list
def bubble_sort2(student_list):
for i in range(len(student_list) - 1):
for j in range(len(student_list) - i - 1):
if student_list[j].num > student_list[j + 1].num:
student_list[j], student_list[j + 1] = student_list[j + 1], student_list[j]
return student_list
通过冒泡排序法,将分数进行降序排序,以及对学号进行升序排序
-
8.计算最高分,最低分和总分
def count_avg():
sum = 0
for i in range(len(student_list)):
sum+=student_list[i]
return sum/len(student_list)
最高和最低经验值都可以从对象数组的第一和最后取出
只要计算一下平均数就可以了
-
9.将数据写入文档
def write_txt(str):
# 把信息输入txt文件内
file = open("studentInfo.txt", mode='b')
file.write(str)
-
主方法
if __name__ == '__main__':
student_info()
bubble_sort2(bubble_sort1(student_list))
soup = html_data(course_url()[0]).decode("utf-8")
student_name = re.compile("<span style=\"font-size: 12px; color: #333;\">(.*?)</span>", re.S).findall(soup)
write_txt("最高经验值:"+student_list[0].score+",最低经验值:"+student_list[len((student_name))].score+",平均经验值"+count_avg())
for j in range(len(student_name)):
write_txt(str(student_list[j].name) + "," + str(student_list[j].num) + "," + student_list[j].score +"\n")
-
运行结果
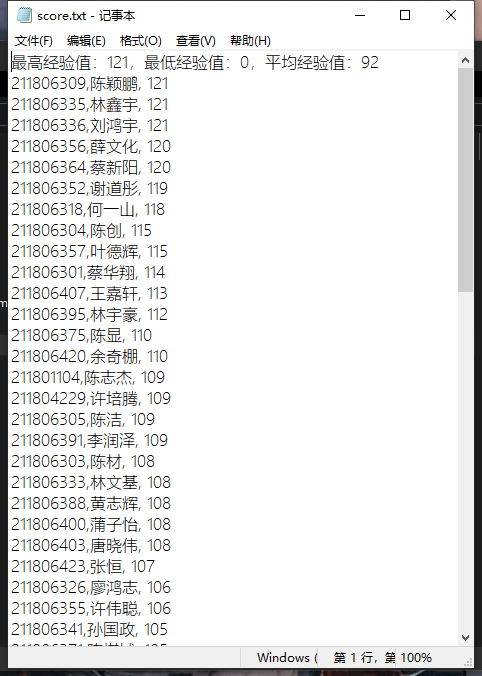
总结
因为这次的需要解析的网页很多,每个网页有同有异,为了保证数据得到的是对的,在测试代码上花了不少时间
解析网址时用了太多的选择和循环语句,导致代码运行很慢,负担很重,或许可以怎么优化一下?
对于函数运用的不熟练,需要不断地转换类型,也对运行造成了负担
特别鸣谢
有关Cookie的解释及使用
https://blog.csdn.net/w_linux/article/details/78448953
BeatuifulSoup的使用
http://www.jsphp.net/python/show-24-214-1.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号