

一、带着问题看解读
pick_next_task_fair用于CFS调度器选择下一个要运行的候选任务。对于没有cgroup的情况下比较简单,但是如果有多层级的cgroup则需要考虑一些情况。在展开pick_next_task_fair()整体框架之前,这里先提出一些问题,带着问题来展开。
1.1 对于有cgroup的公平调度而言(CFS),选下一个任务时,是从底向上选还是从cgroup顶层开始向下选?
假设上一个要调度出去的任务对应的调度实体是prev,那要选择下一个需要运行的任务时,是从第一层(root)开始向下层遍历,每遍历一层就在该层级选择一个最优的调度实体;然后再从这个"最优"实体起选择最优的下一层级的调度实体,依次往下直到叶子节点,叶子节点调度实体代表的就是一个任务。
1.2 选择下一个任务时的算法是什么样的?
选下一个任务时,更准确的说是下一个调度实体,前面已经提到过是从上到下层级依次选择调度实体,直到叶子节点。这个选择的函数:
se = pick_next_entity(cfs_rq, curr)
参数cfs_rq表示遍历的当前层级的就绪队列,是一颗红黑树;参数curr表示当前正在运行调度实体;返回值是选中的下一个运行的调度实体se。
这里具体的选择算法遵循如下几个原则:
/* * Pick the next process, keeping these things in mind, in this order: * 1) keep things fair between processes/task groups * 2) pick the "next" process, since someone really wants that to run * 3) pick the "last" process, for cache locality * 4) do not run the "skip" process, if something else is available */
1) 尽量保持任务之间的公平性,选择时选择cfs_rq中vruntime最小的,也就是红黑树中最左边的节点;2) 在保证一定公平性的基础上尽量选择cfs_rq->next; 3) 在保证一定公平性的基础上,为了cache尽量选择cfs_rq->last; 3) 避开cfs_rq->skip。详情参考后面代码解析。
1.3 选好了下一个要运行的任务next后,对于有cgroup的情况下如何完成prev到next的交接?
1.3.1 考虑交接的范围
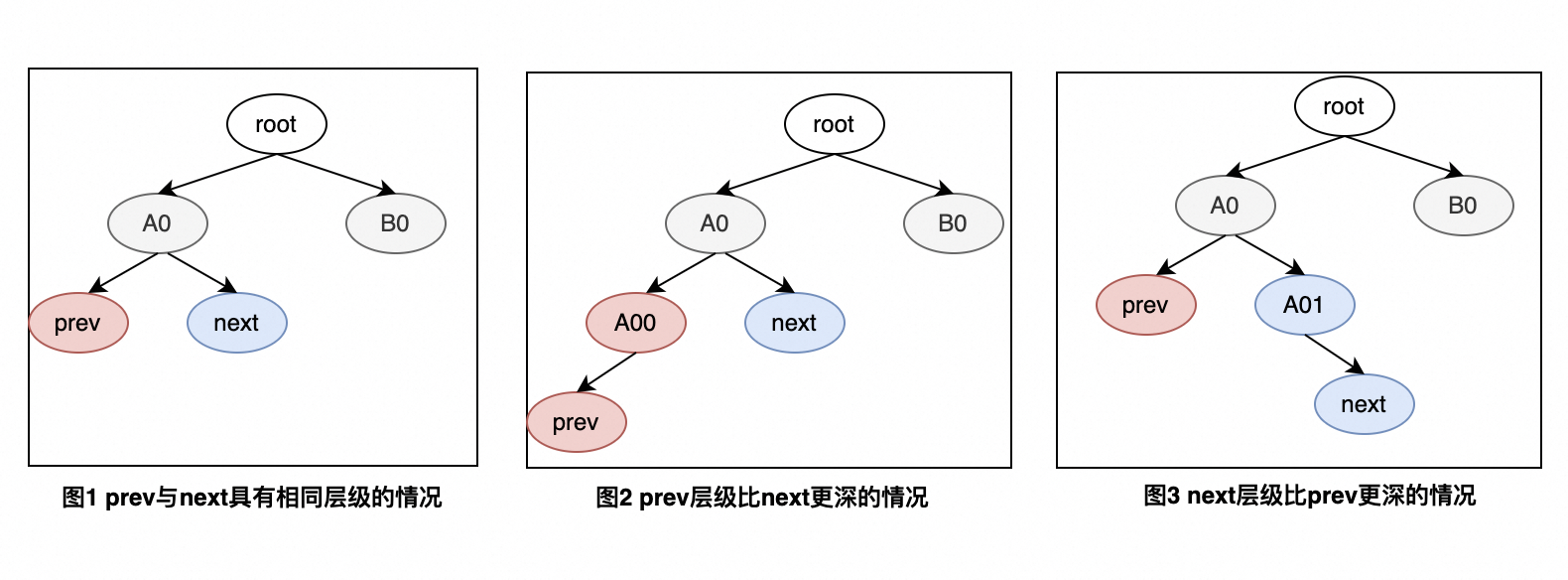
next与prev都是叶子节点,next与prev的交接还会涉及到它们的上层调度实体。如果next与prev处于同一个group(prev_se->cfs_rq == next_se->cfs_rq),则不会影响它们共同的上层级;否则交接的过程需要从叶子节点一直向上进行,直到它们达到相同的层级。
情况1:如图1所示,prev与next在同一个层级,且拥有相同的parent和相同的cfs_rq,因此不用进行"对齐",直接交接;
情况2:如图2所示,prev层级比next层级更深,此时prev需要向上遍历,直到与next在同一个层级且具有相同的cfs_rq和parent,然后进行交接;
情况3:如图3所示,next层级比prev要更深,此时next需要向上遍历,直到与prev在同一个层级且具有相同的cfs_rq和parent,然后进行交接。
1.3.2 如何交接
对于前一个任务而言,会将其对应的调度实体以及parent的调度实体通过put_prev_entity()完成几件事情:(1)更新运行数据;(2)检查cfs_rq是否超额; (3)如果调度实体prev->on_rq为真,则将prev调度实体放回到cfs_rq红黑树; (4)将cfs_rq->curr先置为NULL,为next设置为curr做准备。
对于下一个任务而言,会将其对应的调度实体以及parent的调度实体通过set_next_entity()完成几件事情:(1)如果next->on_rq为真,则next调度实体从cfs_rq红黑树摘除; (2)将cfs_rq->curr设置为next
二、整体流程代码解读
下面结合开源linux-5.10代码流程进行的解读和注解:

struct task_struct * pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf) { struct cfs_rq *cfs_rq = &rq->cfs; //cfs_rq是此rq的顶层cfs_rq队列 struct sched_entity *se; struct task_struct *p; int new_tasks; again: if (!sched_fair_runnable(rq)) //【1】rq->cfs.nr_running>0; goto idle; #ifdef CONFIG_FAIR_GROUP_SCHED if (!prev || prev->sched_class != &fair_sched_class) goto simple; //【2】由上而下遍历cgroup层级选择下一个要运行的任务 //由于set_next_buddy() in dequeue_task_fair() 很可能将next和prev在同一个cgroup,因此尽量只针对修改过的部分,而非调整整个整个hierarchy do { //从最顶层的cfs_rq开始遍历,直到层级的叶子节点se,即真正的task(判断叶子节点方法:se->my_q为NULL) struct sched_entity *curr = cfs_rq->curr; if (curr) { if (curr->on_rq) update_curr(cfs_rq); else curr = NULL; if (unlikely(check_cfs_rq_runtime(cfs_rq))) { cfs_rq = &rq->cfs; if (!cfs_rq->nr_running) goto idle; goto simple; } } se = pick_next_entity(cfs_rq, curr); cfs_rq = group_cfs_rq(se); //获取se->my_q,如果se->my_q为NULL表示它是叶子节点,即task } while (cfs_rq); p = task_of(se); if (prev != p) { //【3】完成prev和next的交接,这会涉及到二者的parent层级 struct sched_entity *pse = &prev->se; //从prev和se的叶子节点不断向上level调整层级,直到二者的se->cfs_rq一致,即同一个level为止 while (!(cfs_rq = is_same_group(se, pse))) { //循环对prev和next se做put或set,直到它们都在同一个level int se_depth = se->depth; //如何判断它们都层级深浅呢?通过se->depth来判定的。 int pse_depth = pse->depth; if (se_depth <= pse_depth) { //如果se<=prev的层级,则put prev,且prev往parent生一个level,最终目的是要和se保持同一个level put_prev_entity(cfs_rq_of(pse), pse); pse = parent_entity(pse); } if (se_depth >= pse_depth) { set_next_entity(cfs_rq_of(se), se); se = parent_entity(se); } } //到此二者的层级一致,此层级下面的层级都已经更新 // 这样se->parent的状态和se的状态保持一致,例如se->statistics.wait_start都会清0 //另外,如果se和pse在同一个group,会发生什么?pse是等待状态,但是pse->parent和se->parent是同一个 put_prev_entity(cfs_rq, pse); set_next_entity(cfs_rq, se); } goto done; simple: //……. done: __maybe_unused; #ifdef CONFIG_SMP list_move(&p->se.group_node, &rq->cfs_tasks); #endif if (hrtick_enabled(rq)) hrtick_start_fair(rq, p); update_misfit_status(p, rq); return p; //返回这个任务 idle: if (!rf) return NULL; new_tasks = newidle_balance(rq, rf); //如果是idle则进行idle balance if (new_tasks < 0) return RETRY_TASK; if (new_tasks > 0) goto again; update_idle_rq_clock_pelt(rq); return NULL; }
【1】 检查是否idle
判断rq->cfs.nr_running>0?如果不满足说明没有可运行任务则goto idle
【2】 由上而下遍历cgroup层级选择下一个要运行的任务
从最顶层的就绪队列rq->cfs逐层向下遍历,(1)检查每一层的cfs_rq是否throttle,如果throttle则判断是否还有可运行任务,若无则goto idle; (2) pick_next_entity(cfs_rq, curr)选择对应的调度实体,直到叶子节点task(se->my_q为空)。这里的pick_next_entity(cfs_rq, curr)究竟是如何选择下一个调度实体的,参考第5节。
【3】 prev与next的交接
经过第2步就选好了下一个要运行的task,接下来就要将prev task从CPU上”put”卸载下来;同时将next task从就绪队列set到curr。
这里要考虑几个因素:
(1) prev task从CPU卸载下来时,它的上层级se,如parent是否也要卸载?
(2) next task从就绪队列set为curr时,它的上层se,如parent是否也要同样set?
(3) 如果prev task和next task在同一个cgroup控制组,即它们都parent是同一个se,情况如何呢?
【3.1】 从prev和next task的叶子节点开始向上层级遍历(用pse和se分别代表prev和next的调度实体),直到prev和next处于同一层级,即 pse->cfs_rq == se->cfs_rq
【3.2】 在每次遍历过程中判断pse和se的层级深度,如果(pse->depth >= se->depth)则先put_prev_entity(pse)然后prev往parent上升一级pse = pse->parent;
相反,如果(se->depth >= pse->depth)则先set_next_entity(se)然后se往parent上升一级se = se->parent;
【3.3】 最终,se和pse处于同一个层级、同为sibling时整个遍历结束。
三 调度实体的选择
前面讲解了选择next task的整体框架流程。这里要对其中一个细节,即选择下一个se的核心函数pick_next_entity做一个详解。
整个流程我愿将其分为3个部分。
第一步,从cfs_rq选择最优的调度实体left。为什么称为left,因为cfs_rq选下一个运行任务的逻辑是选择调度实体vruntime最小的,而cfs_rq是根据vruntime值大小组织起来的红黑树,红黑树最左边的调度实体vruntime值最小。
第二步,尽量避免cfs_rq->skip作为下一个任务。
如果第一步选择的 se==cfs_rq->skip,则从cfs_rq中选择次优的调度实体second,如果left与second的vruntime差距不大(即wakeup_preempt_entity(second, left) < 1)则将left替换为second。这里的wakeup_preempt_entity(second, left)<1表示left的vruntime与second的差值不够大没有达到left失去公平性的程度。具体原则如下:
(1) 计算差值 vdfiff = second->vruntime - left->vruntime
(2) 如果vdiff > gran(left)则返回1表示 second比left的vruntime足够大,left需要抢占second;否则second与left差距不够大。
这里gran(se)的计算公式:sysctl_sched_wakeup_granularity/(weight of se)。其中分子sysctl_sched_wakeup_granularity在linux-5.10中的值默认为1000000;而分母(weight of se)表示调度实体se的权重,对于一个task而言,权重和它的优先级有关,如果nice为0则其权重为1024,换算过来这里的分母就是1。
因此,第一候选任务left==cfs_rq->skip时并非无下限的被替换掉,只有当cfs_rq中第二选择second与left的vruntime差值小于gran(left)才会选择second替代left。这里的判定函数wakeup_preempt_entity后面还会用到。
第三步,如果有next选next,有last选last。
如果cfs_rq->next不为NULL,且cfs_rq->next与left的vruntime差值小于gran(left)则选cfs_rq->next;否则,如果cfs_rq->last不为NULL,且cfs_rq->last与left的vruntime差值小于gran(left)则选cfs_rq->last。
这里的gran()计算规则和第二步相同不再赘述。
/* * Pick the next process, keeping these things in mind, in this order: * 1) keep things fair between processes/task groups * 2) pick the "next" process, since someone really wants that to run * 3) pick the "last" process, for cache locality * 4) do not run the "skip" process, if something else is available */ static struct sched_entity * pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr) { struct sched_entity *left = __pick_first_entity(cfs_rq); struct sched_entity *se; /* * If curr is set we have to see if its left of the leftmost entity * still in the tree, provided there was anything in the tree at all. */ if (!left || (curr && entity_before(curr, left))) left = curr; se = left; /* ideally we run the leftmost entity */ /* * Avoid running the skip buddy, if running something else can * be done without getting too unfair. */ if (cfs_rq->skip == se) { struct sched_entity *second; if (se == curr) { second = __pick_first_entity(cfs_rq); } else { second = __pick_next_entity(se); if (!second || (curr && entity_before(curr, second))) second = curr; } if (second && wakeup_preempt_entity(second, left) < 1) se = second; } if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1) { /* * Someone really wants this to run. If it's not unfair, run it. */ se = cfs_rq->next; } else if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1) { /* * Prefer last buddy, try to return the CPU to a preempted task. */ se = cfs_rq->last; } clear_buddies(cfs_rq, se); return se; }



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话