IMBALANCED TARGET DISTRIBUTIONS LEARING(目标类别不平衡学习)
什么是目标类别不平衡?
假设你训练集中数据的目标类别的分布较为均匀,那么这样的数据集所建立的分类模型,通常会有比较好的分类效能。
假设你训练集中数据的目标类别的分布不均匀(存在Majority Class和Minority Class的时候),那么这样的数据集造成的问题是分类模型通常倾向将所有数据预测为多数类别,而完全忽视少数类别。
解决目标类别不平衡的方法:
减少多数类别的抽样法:
最近邻策略(KNN Approach)减少多数类别:
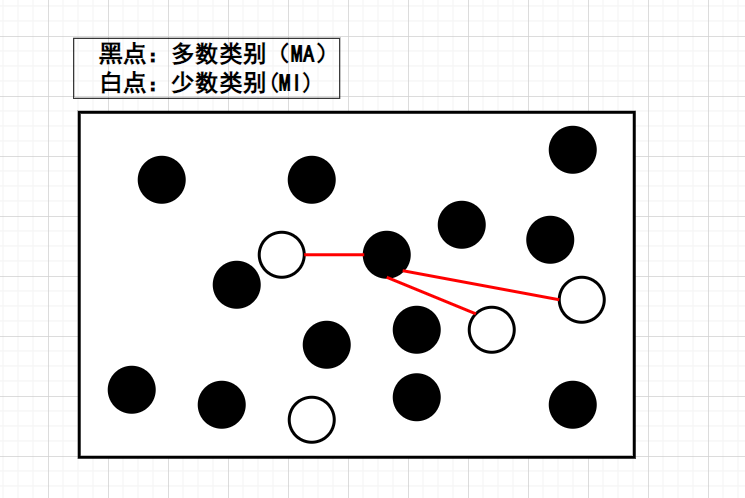
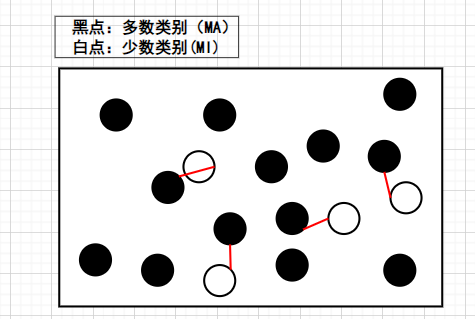
- NearMiss-1(核心思想:如果与MI比较近的样本点,模型都可以分开,那么其他离MI比较远的点,模型自然可以分开。)
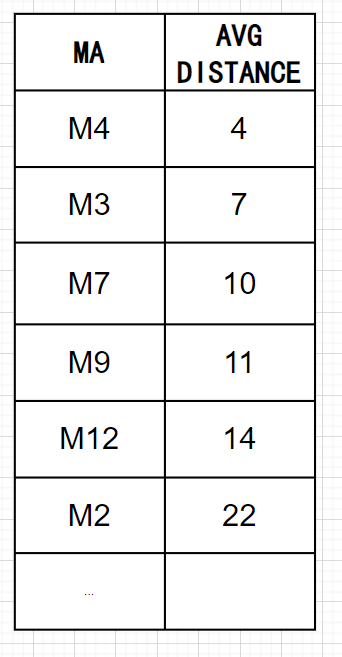
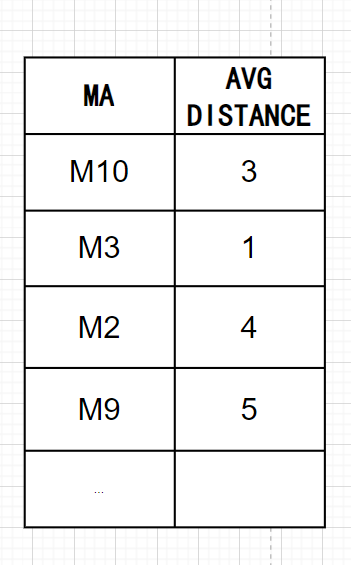
Step1:首先计算每个MA与所有MI的距离,然后每个MA会挑选与它最接近的3个MI,并计算与这3个MI的平均距离。
Step2:假如想降到多数类别:少数类别的比例为1:1,那么我们可以选取平均距离较小的前4个MA。
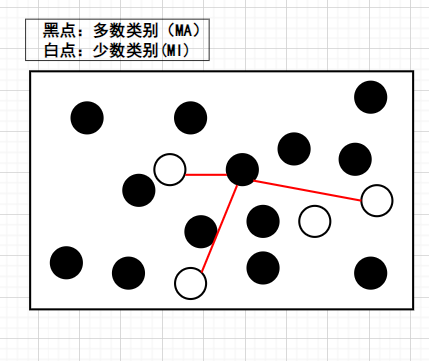
- NearMiss-2:(核心思想:NearMiss-1的条件有些严格,可能导致后续分类模型不再能将样本点分开。NearMiss-2对其做了距离上的改进。)
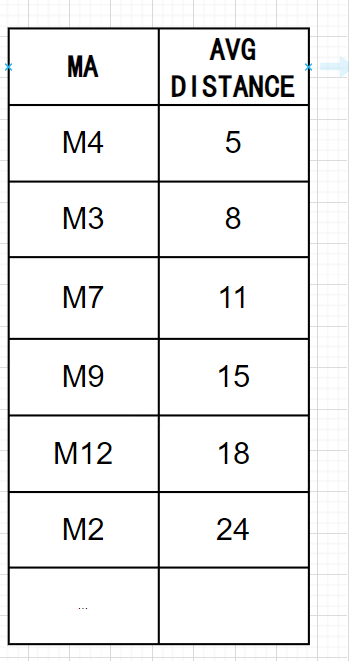
Step1:首先计算每个MA与所有MI的距离,然后每个MA会挑选与它最远的3个MI,并计算与这3个MI的平均距离。
Step2:假如想降到多数类别:少数类别的比例为1:1,那么我们可以选取平均距离较小的前4个MA。
- NearMiss-3:(核心思想:NearMiss-3试图将距离最近的MA和MI拆分开。)
Step1:首先计算每个MA与所有MI的距离。
Step2:假如想降到多数类别:少数类别的比例为1:1,那么我们可以对每个MI挑选1个距离较近的MA;如果想降到2:1,那么我们可以对每个MI挑选2个距离较近的MA。
最近邻策略(KNN Approach)减少多数类别的缺点:
1.计算时间过长 计算每个MA与所有MI的距离通常需要花时间。假设正、负样本数量为3000:900w,那么相当于要算 900w^3000次,之后算完后还要排序,计算平均距离。
2.分类效果并没有想象中那么好
3.方法没有考虑多数类别的分布情形 假如数据集有两个MA,一个MI,那么虽然我们为每个MI寻找了各自的“MA“,但如果选择的都是两个MA中数量较多的MA,那么分类结果可能并不偏向于较少的MA。
结合聚类解决目标类别不平衡问题
- Cluster_based Approach:该方法的假设样本可以分为多个不同的类别,设法从多数类别中抽取出具有代表性的样本点。
假设原来资料点本身的类别是不平衡的,(MA:1000;MI:100)。
Step_1:对原来的资料点进行聚类,假设我们聚了3类。
Step_2:假设第一个类别中的资料点分布比例为10:1,第二个类别中的资料点分布比例为20:1,第三个类别中的资料点分布比例为5:1
Step_3:假设总共要从原来资料点中总共抽取100笔的MA,以期将MA:MI比例降低到1:1。
那么我们认为,
第一类别要抽100×(10/35),
第二个类别要抽100×(20/35),
第三个类别要抽100×(5/35)。
Cluster_based Approach的缺点
- 聚类的方法需要根据特征来计算距离,不同的特征(重要、非重要)将直接影响到聚类结果的好坏,进而影响抽样的效果。
- 需抽取的数据数量需要大于该簇的数据总数。
增加少数类别的抽样法
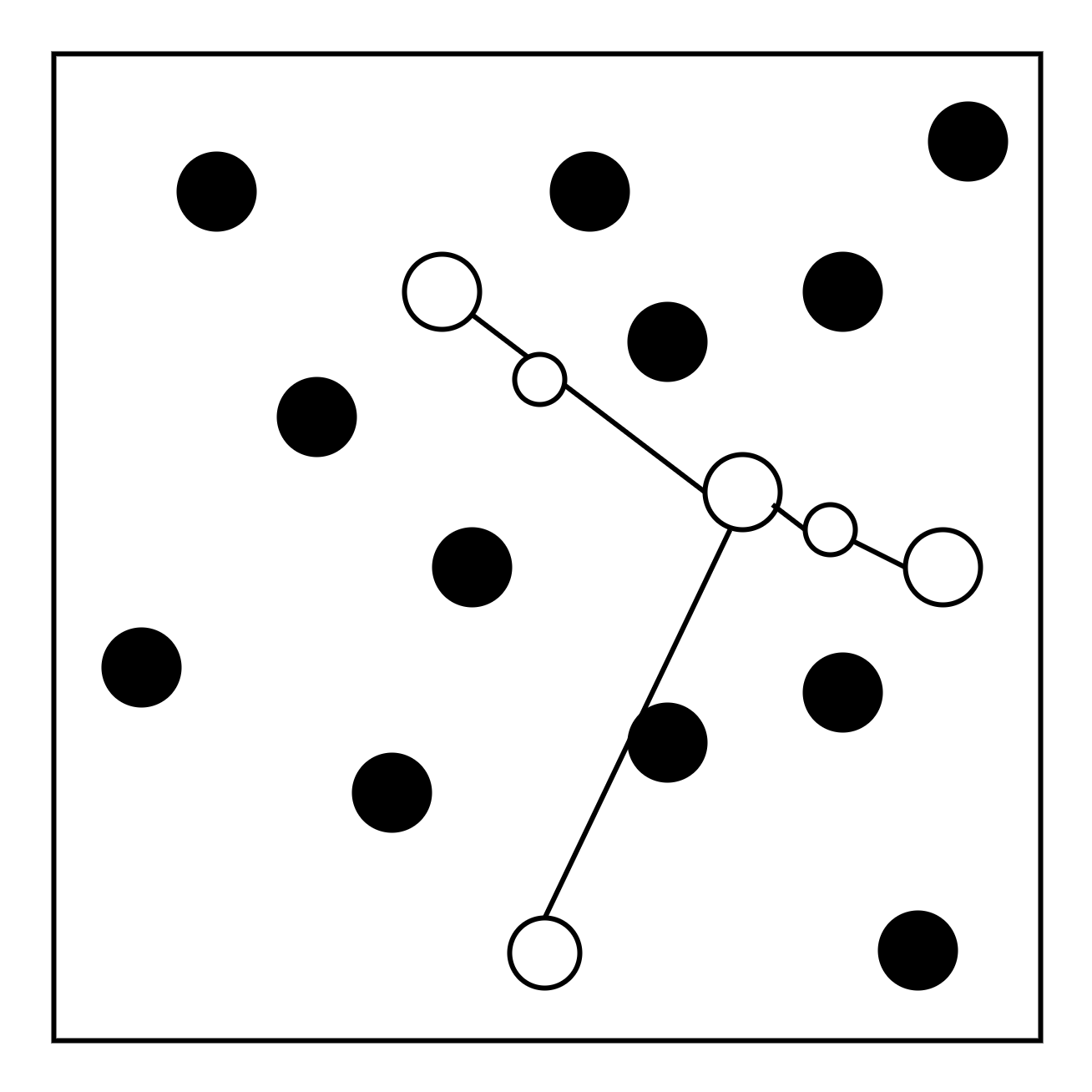
- SMOTE:SMOTE的基本假设是:两个MI直线距离之间的样本点也可以被认为是MI
Step1:针对每个MI,计算与之最近的K个MI。
Step2:随机选取某个MI中的数据i,并从与之最近的K个MI中随机选取一个数据j
Step3:计算数据i和数据j之间的差
Step4:随机产生一个介于0~1之间的值w
Step5:产生人造数据x+w*p
重复Step2~Step5,直到人造数据满足需求的个数为止。
重复Step2~Step6,直到所有MI都执行过一次,
SMOTE方法 增加少数类别的缺点:
1.没有考虑多数类别数据的分布情形 作者认为少数类别应该分布在一起,在少数类别数据间产生的数据也必然是少数类别。这种假设存在一定的局限性,因为多数类别的分布并没有被考虑进去。
2.分类效果并没有想象中那么好 SMOTE方法带来的分类效能在一些资料集上并没有明显的提升,其分类效能并未明显优于随机减少多数类别抽样法(随机欠采样)
