强化学习系列(一)
1.为什么要学习强化学习?
训练大模型时,不能仅仅使用有监督微调。
这是因为NLP中语言的多样性,大模型给出的很多答案的含义是一样的。
并且有监督微调通常需要大量的高质量问答文本,这类文本的整理需要耗费大量的人力与时间成本。
强化学习的优化目标不再是让模型输出结果与标准答案相同,而是要使模型生成高质量回复。这样,模型在生成答案后,奖励模型可以对答案给出质量判断、质量排序。
2.强化学习的基本框架
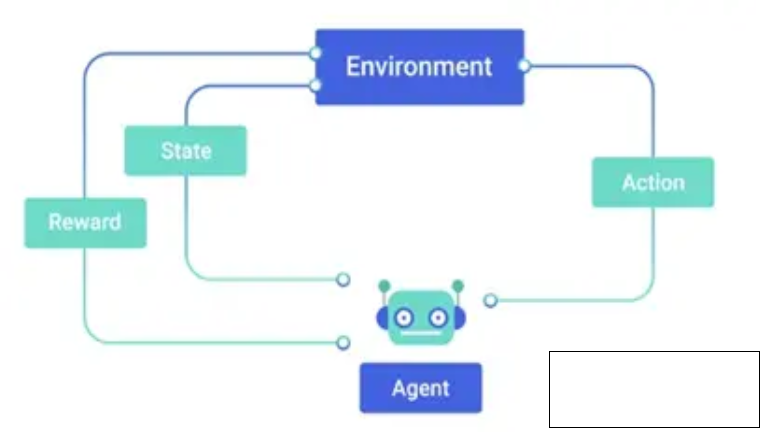
Agent:智能体;Enviroment:环境;强化学习主要由Agent和Enviroment组成;
Step1:智能体在环境中获取到某个状态State()
Step2:智能体会根据这个状态输出一个动作Action (),动作会在环境中执行。
Step3:环境根据Action,给出当前动作带来的奖励Reward()和下一个状态()。
智能体的目标是尽可能多地从环境中获取奖励。
3.强化学习相关概念
(1):智能体:可以做出决策并执行动作的物体。
(2):环境:智能体所在的场景。环境会根据智能体的行为给出反馈,通常以奖励的形式。
(3):状态、行为与奖励:智能体会评估当前环境的状态。基于这些状态,它会采取某种动作,在它采用执行动作后,环境随后会给出一个奖励。
(4):策略与价值:在智能体尝试各种行为的过程中,智能体其实是在学习一个策略(Policy)。策略可以视为一套指导其在特定状态下如何行动的准则。与此同时,智能体还试图估计价值(Value)函数,也就是预测在未来采用某一行为所能带来的奖励。
4.强化学习的目标
强化学习的目标就是让智能体在环境中学习到一个策略,使得自身奖励最大化。
5.详细讲讲“策略“
策略决定了:智能体在环境下采取的动作。
可以分为两种:随机性策略与确定性策略。
随机性策略:
假设用A表示智能体在环境中所有动作的集合,那么为t时刻下智能体的动作,那么我们用,表示智能体所有动作的概率。利用这个概率分布进行采样,就可以得到智能体将采取的动作。
确定性策略:
我们可以对π(a|s)取极值,即可得到智能体最有可能(概率最大)的动作。
5.详细讲讲“价值函数“
前面说到,智能体会预测未来采用某一行为所能带来的奖励。
那么,这个过程用可用以下两种价值函数,其值反应在使用π策略所能获得到的奖励值表示:
只受当前状态s决定的价值函数:,y为折扣因子。
同时受当前状态s和动作a决定的价值函数:,y为折扣因子。
6.强化学习之意义
1.强化学习的反馈粒度相比有监督微调粒度更大
有监督微调往往要求模型针对给定的输入给出确切的答案;而强化学习则是针对整个输出文本进行反馈。这就说明了强化学习更能允许模型给出不同的多样性表达。
有监督微调通常采用交叉熵损失,由于总和规则,造成个别词元只会对整体损失产生小的影响。 但是,一个否定词(个别词元)完全是可以改变文本的整体含义。
2.强化学习相比有监督微调,能解决幻觉问题
我们知道,大语言模型有三个问题:“”偏见,幻觉,过时”。
幻觉问题:当用户提出问题,需要模型根据自己的内在知识提供真实答案时,模型根据自己训练出的参数,给出了一些错误答案。
强化学习,通过使用强化学习方法。定制价值函数,将正确答案赋予非常高的分数,将放弃回答的答案赋予中低分数,将不正确的答案赋予非常高的负分,使得模型学会放弃回答,从而缓解幻觉问题。
3.强化学习可以更好的解决多轮对话问题。
评估多轮对话的质量,是很难用有监督学习方法进行构建的。而使用强化学习方法,定制价值函数,可以根据多轮对话的连贯性、上下文背景对模型的输出进行有效评估。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下