C4.5分类树算法介绍
为什么C4.5会出现?
因为ID3算法节点的分支越多,信息增益也就越大,这会出现过拟合的现象,因此提出C4.5算法。
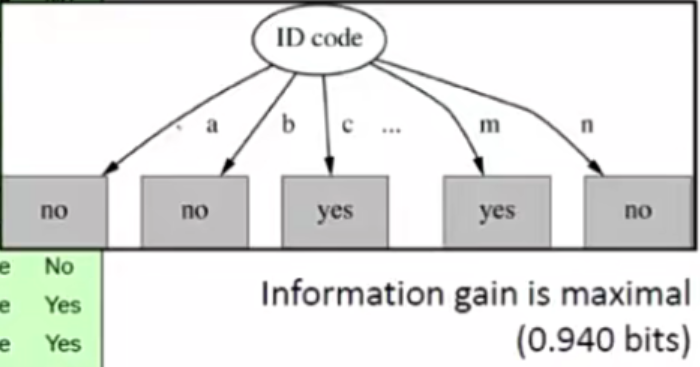
图1
C4.5的属性选择方法——获利比例
获利比例=信息增益/分支度IV
分支度IV与各分支下的类别数目之比成负相关:
假如14个样本一共分4支:
划分方法1为:分支1数目:分支2数目:分支3数目:分支4数目 = 1:1:1:11。
划分方法2为:分支1数目:分支2数目:分支3数目:分支4数目 = 1:1:6:6。
划分方法3为:分支1数目:分支2数目:分支3数目:分支4数目 = 3:3:4:4。
那么划分方法1的分支度IV为1.089,划分方法1的分支度IV为1.592,划分方法3的分支度IV为1.985。
这里的划分方法3,各分支下的数目趋于一致,就像图1中分支的分布,虽然划分了5个类,各个类别下有一个样本,但只针对此次训练集是划分准确的。
加入分支度IV,可有效避免这个问题。
C4.5的砍树方法
假设预测一笔数据的信心水准是CONFIDENCE LEVEL= 25%(CONFIDENCE LEVEL越小,树被修剪的程度越大。)
U25%(0,1)=0.75,U25%(0,6)=0.206,U25%(0,9)=0.143 。 (这里的U25%(0,1)表示:1笔训练数据,训练数据无错,但测试集的错误概率是0.75。)
假设某决策树含以下分支
节点B(15Y,1N)
b1 b2 b3
| | |
(6Y,0N) (9Y,0N) (0Y,1N)
则:
b1的错误率为U25%(0,6)* 6
b2的错误率为U25%(0,9)* 9
b3的错误率为U25%(0,1)* 1
分支后的总错误率为U25%(0,6)* 6 + U25%(0,9)* 9 + U25%(0,1) = 3.273 [16笔测试数据如果到此节点,展开的话,预计会错3.273笔。]
分支前的总错误率为U25%(1,16)* 6 = 2.512 [16笔测试数据如果到此节点,预计会错2.5笔。]
3.273 > 2.512。分支后的错误升高,因此得出结论,将此分支砍掉。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律