谈工作中遇到的数据倾斜问题
问题呈现:
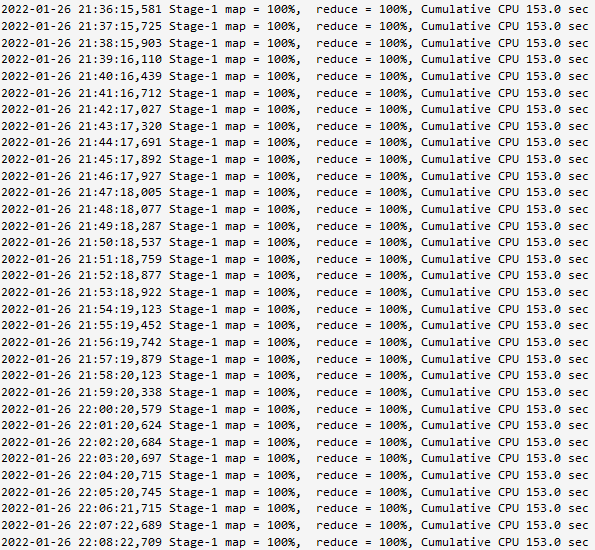
在hive中写SQL生成的MapReduce程序,卡了12个小时。
问题原因:
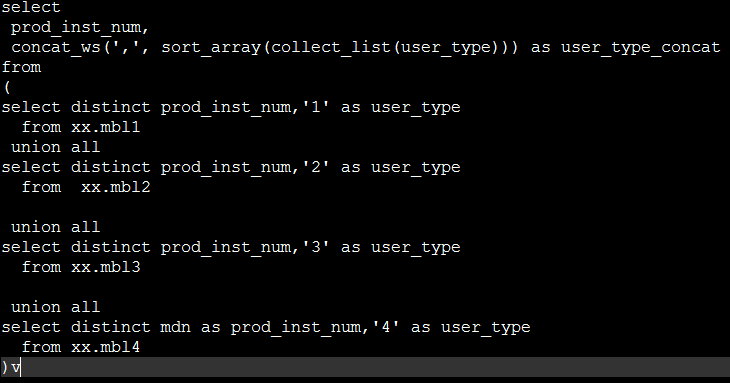
经过我的一番调查,认为是产生了数据倾斜,我的主表需要4个表一块union all,所以数据量还是很多的。
collect_list输出一个数组,中间结果会放到内存中,所以如果collect_list聚合太多数据,会导致内存溢出。而且我还要将该数组排序,使用了sort_array。也就是我要对全部的手机号,做这种聚合操作,如果shuffle后相同的key过多,那么hash的结果就是大量相同的key进入到同一个reduce中,导致数据倾斜。
解决方法:
1.调整reduce所执行的内存大小与reduce的个数
我这里已经是调到8个G了
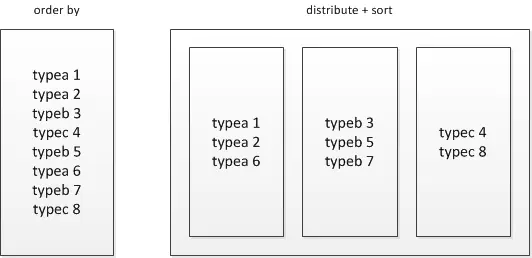
2.使用distribute by和sort by 排序,我这里尽管没有解决collect_list聚合太多数据导致的问题。但我改变了用sort_array排序
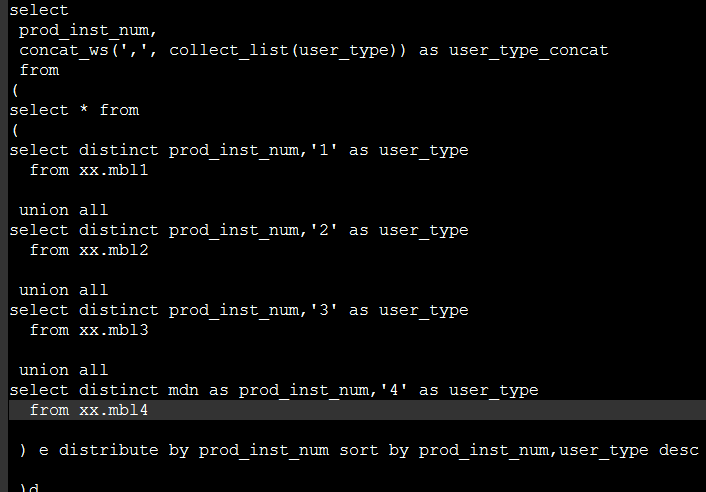
distribute by的功能是:distribute by 控制map结果的分发,它会将具有相同字段的map输出分发到一个reduce节点上做处理。
sort by是局部排序。sort by会根据数据量的大小启动一到多个reducer来干活。
参考文章:
https://blog.csdn.net/u013411339/article/details/120231983
https://blog.csdn.net/qq_40795214/article/details/82190827
https://www.cnblogs.com/qingyunzong/p/8847597.html
https://www.cnblogs.com/gxgd/p/9431525.html
https://blog.csdn.net/peishuai1987/article/details/89882764?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0.pc_relevant_default&spm=1001.2101.3001.4242.1&utm_relevant_index=3


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律