Kudu的模式设计
模式设计基础
1.表至少有一个主键。
2.只有主键才会被索引。(考虑查询会使用什么作为条件)
3.不能更新主键。
4.只有主键才能被用来做表分区。
主键和列的设计
设计表模式,最重要的一项是决定你的主键。你只能将主键用作分区模式的一部分,但无法更新它们。
其他列可以通过update和upsert选项更新
kudu表必须有一个或多个列被定义为主键。这些列不能为空,不可更改的。
分区的基础知识
分区是把数据集划分为几个不重叠的集合的机制。
把数据分成n个分区。
范围分区:假设我们尝试将0~9的整数分到两个分区。
比如将[0,9]分成[0,5)和(5,9]
哈希分区:选择需要哈希的列以及确定数据要分布在哪几个桶中。Kudu使用哈希函数决定一个给定的行应存在哪个桶中。
案例分析
想象一下,当你假期开车出去兜风,结果已经走了半天了,发现车库没关。
借助当今大数据系统,你只需在手机应用上点一个按钮,就关闭了车库
车库数据记录:
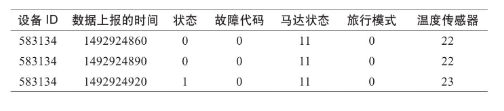
Kudu实现:
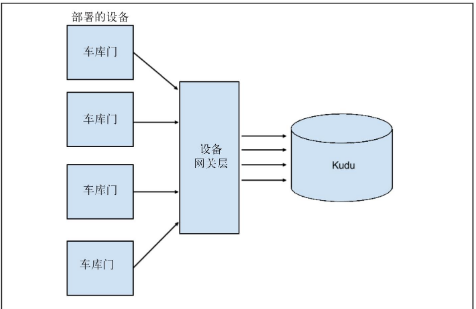
几年前,我们会用两个不同存储层设计这个系统,采用Kudu,开发时间会更快,更容易维护,成本更低。
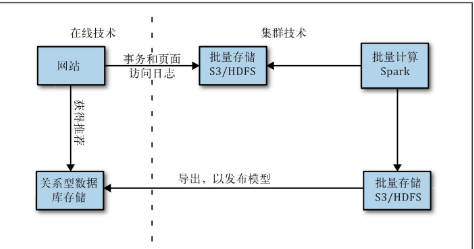
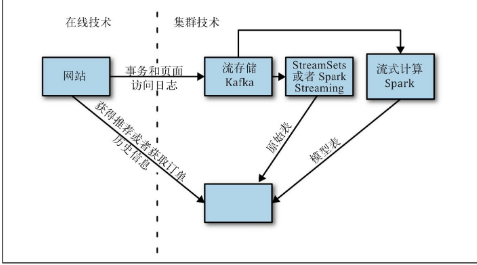
想象一下,你要为客户推荐商品服务
过去你需要一个存储层存储事务和页面浏览日志还有一个批处理执行层计算模型。
存储层可以选用HDFS或Amazon S3 执行层选用Spark,训练好模型后,我们需要它发布到某个地方,以便实时访问。(导出到关系型数据库)
使用KUDU后,消除把数据导出到另一个系统做的复杂工作。因为KUDU支持通过主键快速检索。
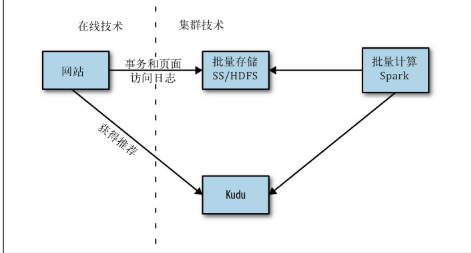
使用流式或实时条件更新批量计算的结果
现实场景:
数据是从不同站点的不同传感器发送过来,所以其到达平台时可能是无序的。
过去:将所有数据存储在一个临时区域,等待所有站点发送完数据,将整个数据集排序再插入表和分区。
现在:Kudu是将数据按照基于主键的顺序存储,因此无需把数据临时存储到其他地方。数据一到达,就可以插入到系统。我们还可以没有延迟的检索数据
“ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程”

