Kudu简介
Kudu介绍
需要实时分析应用场景下,便可能用到Kudu。
2.Kudu提供了更接近于RDBMS的功能和数据模型,提供类似于关系型数据库的存储结构来存储数据,允许用户以和关系型数据库相同的方式插入、更新、删除数据。
3.Kudu仅仅是一个存储层,然而它并不存储数据,而是依赖外部的Hadoop处理引擎(MapReduce,Spark,Impala)。Kudu把数据按照自己的列存储格式存储在底层Linux文件系统中。
实时数据流分析的历史方案
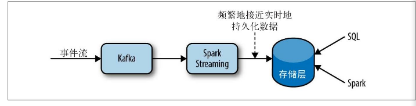
生产者 Spark Streaming 、数据源 Kafka 存储层可以是HDFS
实时处理(也叫流式处理)
流失处理的思想是在数据流中处理数据,而不是将数据保存到存储系统,然后批量处理。
批量处理:每个批次有明确的开始和结束点。
流失处理:持续对流入的小批量数据处理。
举例:
欺诈检测,需要参考用户历史数据(24小时特征)
医疗设备场景 (Hadoop+HBase+HDFS)
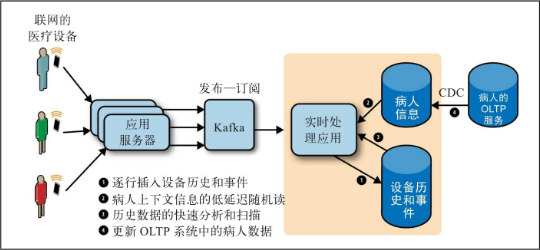
尽管Hadoop存储层可以处理快速插入数据,可以低延迟随机读、更新和扫描,但这个架构会变得复杂且难以维护。
KUDU设计
Kudu的表被水平分割成很多块,称为Tablet
广义地说,有两种关系型数据库:OLTP和OLAP
OLTP适用于对响应速度和数据完整性高的在线服务应用。(行格式存储:适合全行检索和更新)
OLAP适用于数据的大规模扫描。(列格式存储:扫描所有列中的几列)
KUDU适合这两种关系型数据库。
KUDU角色
KUDU中的核心是基于表的存储引擎。
KUDU存储自己的元数据(有关表的)信息和用户的数据,保存在Tablet中。
元数据存、用户数据储在master服务器管理的Tablet中。
存储在master服务器管理的Tablet中。
master:管理KUDU集群。
Tablet:集群中的工作节点。执行所有与数据相关的操作(存储、访问、编码、压缩)
KUDU以列格式存储所有数据。
KUDU写入操作流程:
写入操作->传入tablet
kudu会将新数据存储到一个临时的写缓冲区。缓冲区满了后,就会放到磁盘中的一个位置中。
比如插入一条新的数据,最终会将那一行所有列分成不同的区间
避免热点:
避免读或写查询落到同一个服务器上。
KUDU可以使用两种分区。范围分区(range partitioning)
KUDU实践:
使用KUDU QuickStart VM 熟悉Kudu API和工具(并未预装Hadoop工具)
KUDU几乎是与Impala使用,
Impala依赖于Hive,Hive依赖于HDFS


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律