自然语言处理——实战:使用tf-idf提取关键词并生成词云
关键词提取
关键词的定义:这是一个仁者见仁,智者见智的问题。
一:词频统计
通过统计文章中反复出现的词语。
词频统计的流程:分词、停用词过滤、按词频取前n个。(m个元素取前n个元素通常利用最大堆解决。其复杂度为O(mlogn))
缺点:高频词并不等价于关键词。
二:使用TF-IDF(词频-倒排文档频次)
在TF-IDF算法中,词的重要程度不光正比于他在文档中的频次,还反比于有多少文档包含他。
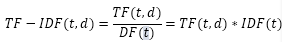
t代表单词,d代表文档,TF(t,d)代表t在d中的出现频次,DF(t)代表多少篇文档包含t。
三:实战测试
数据来源:10000条用户关于套餐内容的投诉信息。包括时间、地址、账号、订单号、英文类型等无关内容。
需求:提取前关键词,生成词云图。
实战结果:
使用了sklearn的TfidfVectorizer算法包,根据tfidf值作为词频生成词云图
结果:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律