通过 docker-compose 快速部署 Hadoop 集群详细教程
一、概述
docker-compose 项目是docker官方的开源项目, 负责实现对docker容器集群的快速编排,来轻松高效的管理容器,定义运行多个容器。
-
通过docker-compose来部署应用是非常简单和快捷的。但是因为docker-compose是管理单机的,所以一般通过docker-compose部署的应用用于测试、poc环境以及学习等非生产环境场景。生产环境如果需要使用容器化部署,建议还是使用K8s。
-
Hadoop集群部署还是稍微比较麻烦点的,针对小伙伴能够快速使用Hadoop集群,这里就使用docker-compose来部署Hadoop集群。
关于docker-compose介绍可以参考我以下几篇文章:
如果需要通过k8s来部署Hadoop环境,可以参考我之前的以下几篇文章:
Hadoop NameNode HA 架构:

Hadoop YARN HA 架构:

二、安装 docker 和 docker-compose
1)安装 docker
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 建议使用阿里云yum源:(推荐)
#yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
yum install -y docker-ce
# 启动并开机启动
systemctl enable --now docker
docker --version
2)安装 docker-compose
官方安装地址教程:https://docs.docker.com/compose/install/other/
curl -SL https://github.com/docker/compose/releases/download/v2.16.0/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
docker-compose --version
三、docker-compose deploy
在讲Hadoop之前这里先补充几个重要的知识点,其实在k8s里面也讲过,只是这里正对docker-compose再来讲解一次。
1)设置副本数
replicas_test.yaml
version: '3'
services:
replicas_test:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/centos:7.7.1908
restart: always
command: ["sh","-c","sleep 36000"]
deploy:
replicas: 2
healthcheck:
test: ["CMD-SHELL", "hostname"]
interval: 10s
timeout: 5s
retries: 3
执行
docker-compose -f replicas_test.yaml up -d
docker-compose -f replicas_test.yaml ps

从上图可知,通过配置 deploy.replicas 来控制创建服务容器的数量,但是并非所有场景都适用,下面Hadoop的有些组件是不适用的,像要求设置主机名和容器名的时候,就不太适用通过这个参数来调整容器的数量。
2)资源隔离
docker-compose的资源隔离跟k8s里面的是一样的,所以通过下面示例就很好理解了,示例如下:
resources_test.yaml
version: '3'
services:
resources_test:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/centos:7.7.1908
restart: always
command: ["sh","-c","sleep 36000"]
deploy:
replicas: 2
resources:
# 容器资源申请的最大值,容器最多能适用这么多资源
limits:
cpus: '1'
memory: 100M
# 所需资源的最小值,跟k8s里的requests一样,就是运行容器的最小值
reservations:
cpus: '0.5'
memory: 50M
healthcheck:
test: ["CMD-SHELL", "hostname"]
interval: 10s
timeout: 5s
retries: 3
执行
docker-compose -f resources_test.yaml up -d
docker-compose -f resources_test.yaml ps
# 查看状态
docker stats deploy-test-resources_test-1

四、docker-compose network
network 在容器中是非常重要的一个知识点,所以这里重点以示例讲解的方式来看看不同docker-compose项目之间如果通过名称访问,默认清楚下,每个docker-compose就是一个项目(不同目录,相同目录的多个compose属于一个项目),每个项目就会默认生成一个网络。注意,默认情况下只能在同一个网络中使用名称相互访问。那不同项目中如何通过名称访问呢,接下来就一示例讲解。
test1/test1.yaml
version: '3'
services:
test1:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/centos:7.7.1908
container_name: c_test1
hostname: h_test1
restart: always
command: ["sh","-c","sleep 36000"]
healthcheck:
test: ["CMD-SHELL", "hostname"]
interval: 10s
timeout: 5s
retries: 3
test2/test2.yaml
version: '3'
services:
test2:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/centos:7.7.1908
container_name: c_test2
hostname: h_test2
restart: always
command: ["sh","-c","sleep 36000"]
healthcheck:
test: ["CMD-SHELL", "hostname"]
interval: 10s
timeout: 5s
retries: 3
执行验证结果如下:
docker-compose -f test1/test1.yaml up -d
docker-compose -f test2/test2.yaml up -d
# 查看network,会生成两个network,如果两个yaml文件在同一个目录下,只会生成一个,它们也就属于同一个network下,是可以通过名称相互访问的。这里是在不同的目录下,就会生成两个network,默认情况下,不同的network是隔离的,不能通过名称访问的。yaml文件所在的目录名就是项目名称。这个项目名称是可以通过参数指定的,下面会细讲。
docker network ls
# 互ping
docker exec -it c_test1 ping c_test2
docker exec -it c_test1 ping h_test2
docker exec -it c_test2 ping c_test1
docker exec -it c_test2 ping h_test1
# 卸载
docker-compose -f test1/test1.yaml down
docker-compose -f test2/test2.yaml down

接下来我们加上network再进行测试验证
test1/network_test1.yaml
在 test1/network_test1.yaml 定义创建新network,在下面test2/network_test2.yaml引用test1创建的网络,那么这两个项目就在同一个网络中了,注意先后执行顺序。
version: '3'
services:
network_test1:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/centos:7.7.1908
container_name: c_network_test1
hostname: h_network_test1
restart: always
command: ["sh","-c","sleep 36000"]
# 使用network
networks:
- test1_network
healthcheck:
test: ["CMD-SHELL", "hostname"]
interval: 10s
timeout: 5s
retries: 3
# 定义创建新网络
networks:
test1_network:
driver: bridge
test2/network_test2.yaml
version: '3'
services:
network_test2:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/centos:7.7.1908
container_name: c_network_test2
hostname: h_network_test2
restart: always
networks:
- test1_network
command: ["sh","-c","sleep 36000"]
healthcheck:
test: ["CMD-SHELL", "hostname"]
interval: 10s
timeout: 5s
retries: 3
# 引用test1的网络
networks:
# 项目名_网络名,可以通过docker network ls查看network名称
test1_test1_network:
external: true
执行验证结果如下:
docker-compose -f test1/network_test1.yaml up -d
docker-compose -f test2/network_test2.yaml up -d
# 查看网络
docker network ls
# 互ping
docker exec -it c_network_test1 ping -c3 c_network_test2
docker exec -it c_network_test1 ping -c3 h_network_test2
docker exec -it c_network_test2 ping -c3 c_network_test1
docker exec -it c_network_test2 ping -c3 h_network_test1
# 卸载,注意顺序,要先卸载应用方,要不然network被应用了是删除不了的
docker-compose -f test2/network_test2.yaml down
docker-compose -f test1/network_test1.yaml down

从上实验可知,只有多个项目在同一个网络里才可以通过主机名或着容器名访问的。
五、docker-compose 项目
默认的项目名称就是当前yaml文件所在的目录名称,上面讲解network的时候生成的网络名称也会最前面的项目名称,但是项目名称是可以自定义的,示例讲解如下:
# test.yaml
version: '3'
services:
test:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/centos:7.7.1908
restart: always
command: ["sh","-c","sleep 36000"]
healthcheck:
test: ["CMD-SHELL", "hostname"]
interval: 10s
timeout: 5s
retries: 3
执行
# 先不加参数
docker-compose -f test.yaml up -d
# 查看网络
network ls
# 使用参数自定义项目名称,-p, --project-name,有四种写法
docker-compose -p=p001 -f test.yaml up -d
docker-compose -p p002 -f test.yaml up -d
docker-compose --project-name=p003 -f test.yaml up -d
docker-compose --project-name p004 -f test.yaml up -d
# 查看网络
docker network ls
# 查看所有项目
docker-compose ls

六、Hadoop 部署(非高可用)
1)安装 JDK
# jdk包在我下面提供的资源包里,当然你也可以去官网下载。
tar -xf jdk-8u212-linux-x64.tar.gz
# /etc/profile文件中追加如下内容:
echo "export JAVA_HOME=`pwd`/jdk1.8.0_212" >> /etc/profile
echo "export PATH=\$JAVA_HOME/bin:\$PATH" >> /etc/profile
echo "export CLASSPATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar" >> /etc/profile
# 加载生效
source /etc/profile
2)下载 hadoop 相关的软件
### 1、Hadoop
# 下载地址:https://dlcdn.apache.org/hadoop/common/
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz --no-check-certificate
### 2、hive
# 下载地址:http://archive.apache.org/dist/hive
wget http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
### 2、spark
# Spark下载地址:http://spark.apache.org/downloads.html
wget https://dlcdn.apache.org/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz --no-check-certificate
### 3、flink
wget https://dlcdn.apache.org/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz --no-check-certificate
3)构建镜像 Dockerfile
FROM registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/centos:7.7.1908
RUN rm -f /etc/localtime && ln -sv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone
RUN export LANG=zh_CN.UTF-8
# 创建用户和用户组,跟yaml编排里的user: 10000:10000
RUN groupadd --system --gid=10000 hadoop && useradd --system --home-dir /home/hadoop --uid=10000 --gid=hadoop hadoop
# 安装sudo
RUN yum -y install sudo ; chmod 640 /etc/sudoers
# 给hadoop添加sudo权限
RUN echo "hadoop ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
RUN yum -y install install net-tools telnet wget nc
RUN mkdir /opt/apache/
# 安装 JDK
ADD jdk-8u212-linux-x64.tar.gz /opt/apache/
ENV JAVA_HOME /opt/apache/jdk1.8.0_212
ENV PATH $JAVA_HOME/bin:$PATH
# 配置 Hadoop
ENV HADOOP_VERSION 3.3.5
ADD hadoop-${HADOOP_VERSION}.tar.gz /opt/apache/
ENV HADOOP_HOME /opt/apache/hadoop
RUN ln -s /opt/apache/hadoop-${HADOOP_VERSION} $HADOOP_HOME
ENV HADOOP_COMMON_HOME=${HADOOP_HOME} \
HADOOP_HDFS_HOME=${HADOOP_HOME} \
HADOOP_MAPRED_HOME=${HADOOP_HOME} \
HADOOP_YARN_HOME=${HADOOP_HOME} \
HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop \
PATH=${PATH}:${HADOOP_HOME}/bin
# 配置Hive
ENV HIVE_VERSION 3.1.3
ADD apache-hive-${HIVE_VERSION}-bin.tar.gz /opt/apache/
ENV HIVE_HOME=/opt/apache/hive
ENV PATH=$HIVE_HOME/bin:$PATH
RUN ln -s /opt/apache/apache-hive-${HIVE_VERSION}-bin ${HIVE_HOME}
# 配置spark
ENV SPARK_VERSION 3.3.2
ADD spark-${SPARK_VERSION}-bin-hadoop3.tgz /opt/apache/
ENV SPARK_HOME=/opt/apache/spark
ENV PATH=$SPARK_HOME/bin:$PATH
RUN ln -s /opt/apache/spark-${SPARK_VERSION}-bin-hadoop3 ${SPARK_HOME}
# 配置 flink
ENV FLINK_VERSION 1.17.0
ADD flink-${FLINK_VERSION}-bin-scala_2.12.tgz /opt/apache/
ENV FLINK_HOME=/opt/apache/flink
ENV PATH=$FLINK_HOME/bin:$PATH
RUN ln -s /opt/apache/flink-${FLINK_VERSION} ${FLINK_HOME}
# 创建namenode、datanode存储目录
RUN mkdir -p /opt/apache/hadoop/data/{hdfs,yarn} /opt/apache/hadoop/data/hdfs/namenode /opt/apache/hadoop/data/hdfs/datanode/data{1..3} /opt/apache/hadoop/data/yarn/{local-dirs,log-dirs,apps}
COPY bootstrap.sh /opt/apache/
COPY config/hadoop-config/* ${HADOOP_HOME}/etc/hadoop/
RUN chown -R hadoop:hadoop /opt/apache
ENV ll "ls -l"
WORKDIR /opt/apache
开始构建镜像
docker build -t hadoop:v1 . --no-cache
# 为了方便小伙伴下载即可使用,我这里将镜像文件推送到阿里云的镜像仓库
docker tag hadoop:v1 registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
### 参数解释
# -t:指定镜像名称
# . :当前目录Dockerfile
# -f:指定Dockerfile路径
# --no-cache:不缓存
4)配置
配置文件会统一放在最下面提供的资源包里的。
1、Hadoop 配置
主要有以下几个文件:core-site.xml、dfs.hosts、dfs.hosts.exclude、hdfs-site.xml、mapred-site.xml、yarn-hosts-exclude、yarn-hosts-include、yarn-site.xml
2、Hive 配置
主要有以下几个文件:hive-env.sh、hive-site.xml,这篇文章不会讲hive部分,会放到下篇文章讲解。
5)启动脚本 bootstrap.sh
# bootstrap.sh
#!/usr/bin/env sh
wait_for() {
echo Waiting for $1 to listen on $2...
while ! nc -z $1 $2; do echo waiting...; sleep 1s; done
}
start_hdfs_namenode() {
if [ ! -f /tmp/namenode-formated ];then
${HADOOP_HOME}/bin/hdfs namenode -format >/tmp/namenode-formated
fi
${HADOOP_HOME}/bin/hdfs --loglevel INFO --daemon start namenode
tail -f ${HADOOP_HOME}/logs/*namenode*.log
}
start_hdfs_datanode() {
wait_for $1 $2
${HADOOP_HOME}/bin/hdfs --loglevel INFO --daemon start datanode
tail -f ${HADOOP_HOME}/logs/*datanode*.log
}
start_yarn_resourcemanager() {
${HADOOP_HOME}/bin/yarn --loglevel INFO --daemon start resourcemanager
tail -f ${HADOOP_HOME}/logs/*resourcemanager*.log
}
start_yarn_nodemanager() {
wait_for $1 $2
${HADOOP_HOME}/bin/yarn --loglevel INFO --daemon start nodemanager
tail -f ${HADOOP_HOME}/logs/*nodemanager*.log
}
start_yarn_proxyserver() {
wait_for $1 $2
${HADOOP_HOME}/bin/yarn --loglevel INFO --daemon start proxyserver
tail -f ${HADOOP_HOME}/logs/*proxyserver*.log
}
start_mr_historyserver() {
wait_for $1 $2
${HADOOP_HOME}/bin/mapred --loglevel INFO --daemon start historyserver
tail -f ${HADOOP_HOME}/logs/*historyserver*.log
}
case $1 in
hadoop-hdfs-nn)
start_hdfs_namenode
;;
hadoop-hdfs-dn)
start_hdfs_datanode $2 $3
;;
hadoop-yarn-rm)
start_yarn_resourcemanager
;;
hadoop-yarn-nm)
start_yarn_nodemanager $2 $3
;;
hadoop-yarn-proxyserver)
start_yarn_proxyserver $2 $3
;;
hadoop-mr-historyserver)
start_mr_historyserver $2 $3
;;
*)
echo "请输入正确的服务启动命令~"
;;
esac
6)YAML 编排 docker-compose.yaml
version: '3'
services:
hadoop-hdfs-nn:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-nn
hostname: hadoop-hdfs-nn
restart: always
env_file:
- .env
ports:
- "30070:${HADOOP_HDFS_NN_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-nn"]
networks:
- hadoop_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_HDFS_NN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-hdfs-dn-0:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-dn-0
hostname: hadoop-hdfs-dn-0
restart: always
depends_on:
- hadoop-hdfs-nn
env_file:
- .env
ports:
- "30864:${HADOOP_HDFS_DN_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-dn hadoop-hdfs-nn ${HADOOP_HDFS_NN_PORT}"]
networks:
- hadoop_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_HDFS_DN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-hdfs-dn-1:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-dn-1
hostname: hadoop-hdfs-dn-1
restart: always
depends_on:
- hadoop-hdfs-nn
env_file:
- .env
ports:
- "30865:${HADOOP_HDFS_DN_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-dn hadoop-hdfs-nn ${HADOOP_HDFS_NN_PORT}"]
networks:
- hadoop_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_HDFS_DN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-hdfs-dn-2:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-dn-2
hostname: hadoop-hdfs-dn-2
restart: always
depends_on:
- hadoop-hdfs-nn
env_file:
- .env
ports:
- "30866:${HADOOP_HDFS_DN_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-dn hadoop-hdfs-nn ${HADOOP_HDFS_NN_PORT}"]
networks:
- hadoop_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_HDFS_DN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-yarn-rm:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
user: "hadoop:hadoop"
container_name: hadoop-yarn-rm
hostname: hadoop-yarn-rm
restart: always
env_file:
- .env
ports:
- "30888:${HADOOP_YARN_RM_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-yarn-rm"]
networks:
- hadoop_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_YARN_RM_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-yarn-nm-0:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
user: "hadoop:hadoop"
container_name: hadoop-yarn-nm-0
hostname: hadoop-yarn-nm-0
restart: always
depends_on:
- hadoop-yarn-rm
env_file:
- .env
ports:
- "30042:${HADOOP_YARN_NM_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-yarn-nm hadoop-yarn-rm ${HADOOP_YARN_RM_PORT}"]
networks:
- hadoop_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_YARN_NM_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-yarn-nm-1:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
user: "hadoop:hadoop"
container_name: hadoop-yarn-nm-1
hostname: hadoop-yarn-nm-1
restart: always
depends_on:
- hadoop-yarn-rm
env_file:
- .env
ports:
- "30043:${HADOOP_YARN_NM_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-yarn-nm hadoop-yarn-rm ${HADOOP_YARN_RM_PORT}"]
networks:
- hadoop_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_YARN_NM_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-yarn-nm-2:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
user: "hadoop:hadoop"
container_name: hadoop-yarn-nm-2
hostname: hadoop-yarn-nm-2
restart: always
depends_on:
- hadoop-yarn-rm
env_file:
- .env
ports:
- "30044:${HADOOP_YARN_NM_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-yarn-nm hadoop-yarn-rm ${HADOOP_YARN_RM_PORT}"]
networks:
- hadoop_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_YARN_NM_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-yarn-proxyserver:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
user: "hadoop:hadoop"
container_name: hadoop-yarn-proxyserver
hostname: hadoop-yarn-proxyserver
restart: always
depends_on:
- hadoop-yarn-rm
env_file:
- .env
ports:
- "30911:${HADOOP_YARN_PROXYSERVER_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-yarn-proxyserver hadoop-yarn-rm ${HADOOP_YARN_RM_PORT}"]
networks:
- hadoop_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_YARN_PROXYSERVER_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-mr-historyserver:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop:v1
user: "hadoop:hadoop"
container_name: hadoop-mr-historyserver
hostname: hadoop-mr-historyserver
restart: always
depends_on:
- hadoop-yarn-rm
env_file:
- .env
ports:
- "31988:${HADOOP_MR_HISTORYSERVER_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-mr-historyserver hadoop-yarn-rm ${HADOOP_YARN_RM_PORT}"]
networks:
- hadoop_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_MR_HISTORYSERVER_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
networks:
hadoop_network:
driver: bridge
.env 文件内容如下:
HADOOP_HDFS_NN_PORT=9870
HADOOP_HDFS_DN_PORT=9864
HADOOP_YARN_RM_PORT=8088
HADOOP_YARN_NM_PORT=8042
HADOOP_YARN_PROXYSERVER_PORT=9111
HADOOP_MR_HISTORYSERVER_PORT=19888
【温馨提示】
- 如果是不同的compose文件生成的容器,如果不指定一样的network,它们直接是不能通过主机名访问的。
depends_on只能决定容器的启动先后顺序,无法决定容器里服务的启动顺序,作用不大,所以在上面bootstrap.sh脚本里加上一个wait_for函数来真正控制服务的启动顺序。
7)启动服务
# 这里-f docker-compose.yaml可以省略,如果文件名不是docker-compose.yaml就不能省略,-d 后台执行
docker-compose -f docker-compose.yaml up -d
# 查看状态
docker-compose -f docker-compose.yaml ps
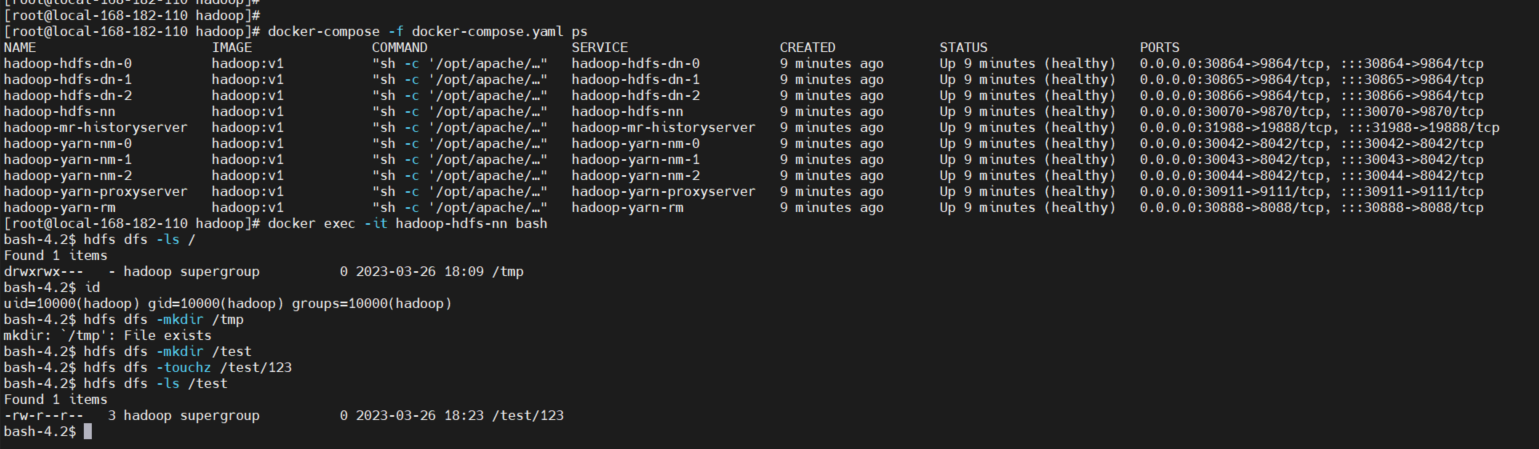
8)测试验证
HDFS:http://ip:30070/


YARN:http://ip:30070/


docker-compose部署非高可用的Hadoop的详细部署就先到这里了,下面继续把高可用的环境部署。
七、Hadoop HA 部署(高可用)
1)安装 JDK
# jdk包在我下面提供的资源包里,当然你也可以去官网下载。
tar -xf jdk-8u212-linux-x64.tar.gz
# /etc/profile文件中追加如下内容:
echo "export JAVA_HOME=`pwd`/jdk1.8.0_212" >> /etc/profile
echo "export PATH=\$JAVA_HOME/bin:\$PATH" >> /etc/profile
echo "export CLASSPATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar" >> /etc/profile
# 加载生效
source /etc/profile
2)下载 hadoop 相关的软件
### 1、zookeeper
# 下载地址:https://zookeeper.apache.org/releases.html
# zookeeper非高可用用不到
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz --no-check-certificate
tar -xf apache-zookeeper-3.8.0-bin.tar.gz
### 2、Hadoop
# 下载地址:https://dlcdn.apache.org/hadoop/common/
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz --no-check-certificate
### 3、spark
# Spark下载地址:http://spark.apache.org/downloads.html
wget https://dlcdn.apache.org/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz --no-check-certificate
### 4、flink
wget https://dlcdn.apache.org/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz --no-check-certificate
3)构建镜像 Dockerfile
FROM registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/centos:7.7.1908
RUN rm -f /etc/localtime && ln -sv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone
RUN export LANG=zh_CN.UTF-8
# 创建用户和用户组,跟yaml编排里的user: 10000:10000
RUN groupadd --system --gid=10000 hadoop && useradd --system --home-dir /home/hadoop --uid=10000 --gid=hadoop hadoop
# 安装sudo
RUN yum -y install sudo ; chmod 640 /etc/sudoers
# 给hadoop添加sudo权限
RUN echo "hadoop ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
RUN yum -y install install net-tools telnet wget
RUN mkdir /opt/apache/
# 安装 JDK
ADD jdk-8u212-linux-x64.tar.gz /opt/apache/
ENV JAVA_HOME /opt/apache/jdk1.8.0_212
ENV PATH $JAVA_HOME/bin:$PATH
# 配置zookeeper
ENV ZOOKEEPER_VERSION 3.8.0
ADD apache-zookeeper-${ZOOKEEPER_VERSION}-bin.tar.gz /opt/apache/
ENV ZOOKEEPER_HOME /opt/apache/zookeeper
RUN ln -s /opt/apache/apache-zookeeper-${ZOOKEEPER_VERSION}-bin $ZOOKEEPER_HOME
COPY config/zookeeper-config/* ${ZOOKEEPER_HOME}/conf/
# 配置 Hadoop
ENV HADOOP_VERSION 3.3.5
ADD hadoop-${HADOOP_VERSION}.tar.gz /opt/apache/
ENV HADOOP_HOME /opt/apache/hadoop
RUN ln -s /opt/apache/hadoop-${HADOOP_VERSION} $HADOOP_HOME
ENV HADOOP_COMMON_HOME=${HADOOP_HOME} \
HADOOP_HDFS_HOME=${HADOOP_HOME} \
HADOOP_MAPRED_HOME=${HADOOP_HOME} \
HADOOP_YARN_HOME=${HADOOP_HOME} \
HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop \
PATH=${PATH}:${HADOOP_HOME}/bin
# 配置Hive
ENV HIVE_VERSION 3.1.3
ADD apache-hive-${HIVE_VERSION}-bin.tar.gz /opt/apache/
ENV HIVE_HOME=/opt/apache/hive
ENV PATH=$HIVE_HOME/bin:$PATH
RUN ln -s /opt/apache/apache-hive-${HIVE_VERSION}-bin ${HIVE_HOME}
# 配置spark
ENV SPARK_VERSION 3.3.2
ADD spark-${SPARK_VERSION}-bin-hadoop3.tgz /opt/apache/
ENV SPARK_HOME=/opt/apache/spark
ENV PATH=$SPARK_HOME/bin:$PATH
RUN ln -s /opt/apache/spark-${SPARK_VERSION}-bin-hadoop3 ${SPARK_HOME}
# 配置 flink
ENV FLINK_VERSION 1.17.0
ADD flink-${FLINK_VERSION}-bin-scala_2.12.tgz /opt/apache/
ENV FLINK_HOME=/opt/apache/flink
ENV PATH=$FLINK_HOME/bin:$PATH
RUN ln -s /opt/apache/flink-${FLINK_VERSION} ${FLINK_HOME}
# 创建namenode、datanode存储目录
RUN mkdir -p /opt/apache/hadoop/data/{hdfs,yarn} /opt/apache/hadoop/data/hdfs/{journalnode,namenode} /opt/apache/hadoop/data/hdfs/datanode/data{1..3} /opt/apache/hadoop/data/yarn/{local-dirs,log-dirs,apps}
COPY bootstrap.sh /opt/apache/
COPY config/hadoop-config/* ${HADOOP_HOME}/etc/hadoop/
RUN chown -R hadoop:hadoop /opt/apache
ENV ll "ls -l"
WORKDIR /opt/apache
开始构建镜像
docker build -t hadoop-ha:v1 . --no-cache
# 为了方便小伙伴下载即可使用,我这里将镜像文件推送到阿里云的镜像仓库
docker tag hadoop:v1 registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
### 参数解释
# -t:指定镜像名称
# . :当前目录Dockerfile
# -f:指定Dockerfile路径
# --no-cache:不缓存
4)配置
配置文件会统一放在最下面提供的资源包里的。
1、Hadoop 配置
主要有以下几个文件:core-site.xml、dfs.hosts、dfs.hosts.exclude、hdfs-site.xml、mapred-site.xml、yarn-hosts-exclude、yarn-hosts-include、yarn-site.xml
2、Hive 配置
主要有以下几个文件:hive-env.sh、hive-site.xml,这篇文章不会讲hive部分,会放到下篇文章讲解。
5)启动脚本 bootstrap.sh
#!/usr/bin/env sh
wait_for() {
echo Waiting for $1 to listen on $2...
while ! nc -z $1 $2; do echo waiting...; sleep 1s; done
}
start_zookeeper() {
${ZOOKEEPER_HOME}/bin/zkServer.sh start
tail -f ${ZOOKEEPER_HOME}/logs/zookeeper-*.out
}
start_hdfs_journalnode() {
wait_for $1 $2
${HADOOP_HOME}/bin/hdfs --loglevel INFO --daemon start journalnode
tail -f ${HADOOP_HOME}/logs/*journalnode*.log
}
start_hdfs_namenode() {
wait_for $1 $2
if [ ! -f /opt/apache/hadoop/data/hdfs/namenode/formated ];then
${ZOOKEEPER_HOME}/bin/zkCli.sh -server zookeeper:${ZOOKEEPER_PORT} ls /hadoop-ha 1>/dev/null
if [ $? -ne 0 ];then
$HADOOP_HOME/bin/hdfs zkfc -formatZK
$HADOOP_HOME/bin/hdfs namenode -format -force -nonInteractive && echo 1 > /opt/apache/hadoop/data/hdfs/namenode/formated
else
$HADOOP_HOME/bin/hdfs namenode -bootstrapStandby && echo 1 > /opt/apache/hadoop/data/hdfs/namenode/formated
fi
fi
$HADOOP_HOME/bin/hdfs --loglevel INFO --daemon start zkfc
$HADOOP_HOME/bin/hdfs --loglevel INFO --daemon start namenode
tail -f ${HADOOP_HOME}/logs/*.out
}
start_hdfs_datanode() {
wait_for $1 $2
${HADOOP_HOME}/bin/hdfs --loglevel INFO --daemon start datanode
tail -f ${HADOOP_HOME}/logs/*datanode*.log
}
start_yarn_resourcemanager() {
wait_for $1 $2
${HADOOP_HOME}/bin/yarn --loglevel INFO --daemon start resourcemanager
tail -f ${HADOOP_HOME}/logs/*resourcemanager*.log
}
start_yarn_nodemanager() {
wait_for $1 $2
${HADOOP_HOME}/bin/yarn --loglevel INFO --daemon start nodemanager
tail -f ${HADOOP_HOME}/logs/*nodemanager*.log
}
start_yarn_proxyserver() {
wait_for $1 $2
${HADOOP_HOME}/bin/yarn --loglevel INFO --daemon start proxyserver
tail -f ${HADOOP_HOME}/logs/*proxyserver*.log
}
start_mr_historyserver() {
wait_for $1 $2
${HADOOP_HOME}/bin/mapred --loglevel INFO --daemon start historyserver
tail -f ${HADOOP_HOME}/logs/*historyserver*.log
}
case $1 in
zookeeper)
start_zookeeper
;;
hadoop-hdfs-jn)
start_hdfs_journalnode $2 $3
;;
hadoop-hdfs-nn)
start_hdfs_namenode $2 $3
;;
hadoop-hdfs-dn)
start_hdfs_datanode $2 $3
;;
hadoop-yarn-rm)
start_yarn_resourcemanager $2 $3
;;
hadoop-yarn-nm)
start_yarn_nodemanager $2 $3
;;
hadoop-yarn-proxyserver)
start_yarn_proxyserver $2 $3
;;
hadoop-mr-historyserver)
start_mr_historyserver $2 $3
;;
*)
echo "请输入正确的服务启动命令~"
;;
esac
6)YAML 编排 docker-compose.yaml
version: '3'
services:
zookeeper:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: zookeeper
hostname: zookeeper
restart: always
env_file:
- .env
ports:
- ${ZOOKEEPER_PORT}
command: ["sh","-c","/opt/apache/bootstrap.sh zookeeper"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${ZOOKEEPER_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-hdfs-jn-0:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-jn-0
hostname: hadoop-hdfs-jn-0
restart: always
depends_on:
- zookeeper
env_file:
- .env
expose:
- ${HADOOP_HDFS_JN_PORT}
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-jn zookeeper ${ZOOKEEPER_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_HDFS_JN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-hdfs-jn-1:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-jn-1
hostname: hadoop-hdfs-jn-1
restart: always
depends_on:
- hadoop-hdfs-jn-0
env_file:
- .env
expose:
- ${HADOOP_HDFS_JN_PORT}
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-jn zookeeper ${ZOOKEEPER_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_HDFS_JN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-hdfs-jn-2:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-jn-2
hostname: hadoop-hdfs-jn-2
restart: always
depends_on:
- hadoop-hdfs-jn-1
env_file:
- .env
expose:
- ${HADOOP_HDFS_JN_PORT}
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-jn zookeeper ${ZOOKEEPER_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_HDFS_JN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-hdfs-nn-0:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-nn-0
hostname: hadoop-hdfs-nn-0
restart: always
depends_on:
- hadoop-hdfs-jn-2
env_file:
- .env
ports:
- "30070:${HADOOP_HDFS_NN_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-nn hadoop-hdfs-jn-2 ${HADOOP_HDFS_JN_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_HDFS_NN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-hdfs-nn-1:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-nn-1
hostname: hadoop-hdfs-nn-1
restart: always
depends_on:
- hadoop-hdfs-nn-0
env_file:
- .env
ports:
- "30071:${HADOOP_HDFS_NN_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-nn hadoop-hdfs-nn-0 ${HADOOP_HDFS_NN_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_HDFS_NN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 6
hadoop-hdfs-dn-0:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-dn-0
hostname: hadoop-hdfs-dn-0
restart: always
depends_on:
- hadoop-hdfs-nn-1
env_file:
- .env
ports:
- "30864:${HADOOP_HDFS_DN_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-dn hadoop-hdfs-nn-1 ${HADOOP_HDFS_NN_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_HDFS_DN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 8
hadoop-hdfs-dn-1:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-dn-1
hostname: hadoop-hdfs-dn-1
restart: always
depends_on:
- hadoop-hdfs-nn-1
env_file:
- .env
ports:
- "30865:${HADOOP_HDFS_DN_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-dn hadoop-hdfs-nn-1 ${HADOOP_HDFS_NN_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_HDFS_DN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 8
hadoop-hdfs-dn-2:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-hdfs-dn-2
hostname: hadoop-hdfs-dn-2
restart: always
depends_on:
- hadoop-hdfs-nn-1
env_file:
- .env
ports:
- "30866:${HADOOP_HDFS_DN_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-hdfs-dn hadoop-hdfs-nn-1 ${HADOOP_HDFS_NN_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_HDFS_DN_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 8
hadoop-yarn-rm-0:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-yarn-rm-0
hostname: hadoop-yarn-rm-0
restart: always
depends_on:
- zookeeper
env_file:
- .env
ports:
- "30888:${HADOOP_YARN_RM_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-yarn-rm zookeeper ${ZOOKEEPER_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_YARN_RM_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-yarn-rm-1:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-yarn-rm-1
hostname: hadoop-yarn-rm-1
restart: always
depends_on:
- hadoop-yarn-rm-0
env_file:
- .env
ports:
- "30889:${HADOOP_YARN_RM_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-yarn-rm hadoop-yarn-rm-0 ${HADOOP_YARN_RM_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_YARN_RM_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-yarn-nm-0:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-yarn-nm-0
hostname: hadoop-yarn-nm-0
restart: always
depends_on:
- hadoop-yarn-rm-1
env_file:
- .env
ports:
- "30042:${HADOOP_YARN_NM_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-yarn-nm hadoop-yarn-rm-1 ${HADOOP_YARN_RM_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_YARN_NM_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-yarn-nm-1:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-yarn-nm-1
hostname: hadoop-yarn-nm-1
restart: always
depends_on:
- hadoop-yarn-rm-1
env_file:
- .env
ports:
- "30043:${HADOOP_YARN_NM_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-yarn-nm hadoop-yarn-rm-1 ${HADOOP_YARN_RM_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_YARN_NM_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-yarn-nm-2:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-yarn-nm-2
hostname: hadoop-yarn-nm-2
restart: always
depends_on:
- hadoop-yarn-rm-1
env_file:
- .env
ports:
- "30044:${HADOOP_YARN_NM_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-yarn-nm hadoop-yarn-rm-1 ${HADOOP_YARN_RM_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "curl --fail http://localhost:${HADOOP_YARN_NM_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-yarn-proxyserver:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-yarn-proxyserver
hostname: hadoop-yarn-proxyserver
restart: always
depends_on:
- hadoop-yarn-rm-1
env_file:
- .env
ports:
- "30911:${HADOOP_YARN_PROXYSERVER_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-yarn-proxyserver hadoop-yarn-rm-1 ${HADOOP_YARN_RM_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_YARN_PROXYSERVER_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 3
hadoop-mr-historyserver:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop-ha:v1
user: "hadoop:hadoop"
container_name: hadoop-mr-historyserver
hostname: hadoop-mr-historyserver
restart: always
depends_on:
- hadoop-yarn-rm-1
env_file:
- .env
ports:
- "31988:${HADOOP_MR_HISTORYSERVER_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hadoop-mr-historyserver hadoop-yarn-rm-1 ${HADOOP_YARN_RM_PORT}"]
networks:
- hadoopha_network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HADOOP_MR_HISTORYSERVER_PORT} || exit 1"]
interval: 10s
timeout: 5s
retries: 6
networks:
hadoopha_network:
driver: bridge
.env
ZOOKEEPER_PORT=2181
HADOOP_HDFS_JN_PORT=8485
HADOOP_HDFS_NN_PORT=9870
HADOOP_HDFS_DN_PORT=9864
HADOOP_YARN_RM_PORT=8088
HADOOP_YARN_NM_PORT=8042
HADOOP_YARN_PROXYSERVER_PORT=9111
HADOOP_MR_HISTORYSERVER_PORT=19888
7)启动服务
# 这里-f docker-compose.yaml可以省略,如果文件名不是docker-compose.yaml就不能省略,-d 后台执行
docker-compose -f docker-compose.yaml up -d
# 查看状态
docker-compose -f docker-compose.yaml ps

8)测试验证
HDFS:http://ip:30070 、http://ip:30071
namenode主节点:

namenode备节点:

databnode 节点:

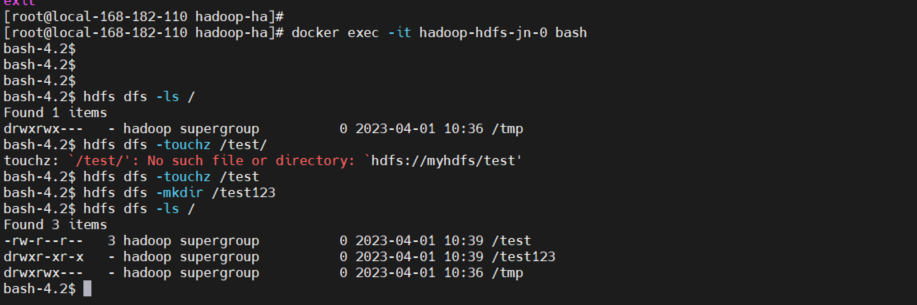
通过命令行测试验证:
# 随便登录一个容器即可
docker exec -it hadoop-hdfs-jn-0 bash
hdfs dfs -ls /
hdfs dfs -touchz /test
hdfs dfs -mkdir /test123
hdfs dfs -ls /
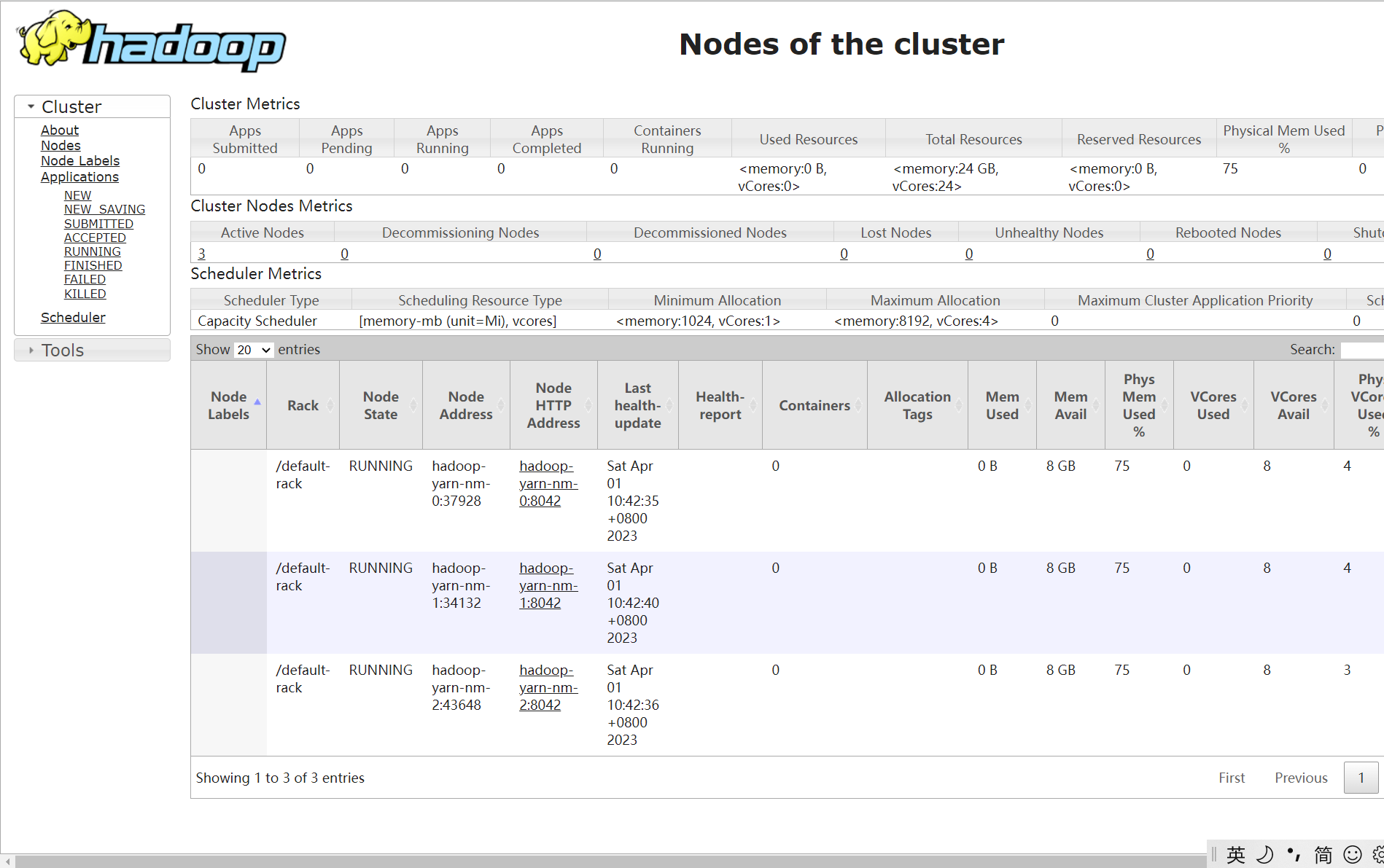
YARN:http://ip:30888、http://ip:30889
resourcemanager 主节点:

resourcemanager 备节点:

nodemanager 节点:
git 地址:https://gitee.com/hadoop-bigdata/docker-compose-hadoop
通过 docker-compose 快速部署 Hadoop 集群的详细过程就先到这了,有任何疑问欢迎给我留言,可关注我的公众号【大数据与云原生技术分享】回复【dch】获取上面的全套资源哦~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号