大数据Hadoop之——Hadoop HDFS多目录磁盘扩展与数据平衡实战操作
一、概述
hdfs 需要存写大量文件,有时磁盘会成为整个集群的性能瓶颈,所以需要优化 hdfs 存取速度,将数据目录配置多磁盘,既可以提高并发存取的速度,还可以解决一块磁盘空间不够的问题。
Hadoop 环境部署可以参考我之前的文章:大数据Hadoop之——Hadoop 3.3.4 HA(高可用)原理与实现(QJM)
二、Hadoop DataNode多目录磁盘配置
1)配置hdfs-site.xml
在配置文件中$HADOOP_HOME/etc/hadoop/hdfs-site.xml添加如下配置:
<!-- dfs.namenode.name.dir是保存FsImage镜像的目录,作用是存放hadoop的名称节点namenode里的metadata-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/bigdata/hadoop/hadoop-3.3.4/data/namenode</value>
</property>
<!-- 存放HDFS文件系统数据文件的目录(存储Block),作用是存放hadoop的数据节点datanode里的多个数据块。 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data1,/data2,/data3,/data4</value>
</property>
<!-- 设置数据存储策略,默认为轮询,现在的情况显然应该用“选择空间多的磁盘存”模式 -->
<property>
<name>dfs.datanode.fsdataset.volume.choosing.policy</name>
<value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
</property>
<!-- 默认值0.75。它的含义是数据块存储到可用空间多的卷上的概率,由此可见,这个值如果取0.5以下,对该策略而言是毫无意义的,一般就采用默认值。-->
<property>
<name>dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction</name>
<value>0.75f</value>
</property>
<!-- 配置各个磁盘的均衡阈值的,默认为10G(10737418240),在此节点的所有数据存储的目录中,找一个占用最大的,找一个占用最小的,如果在两者之差在10G的范围内,那么块分配的方式是轮询。 -->
<property>
<name>dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold</name>
<value>10737418240</value>
</property>
【温馨提示】此处的
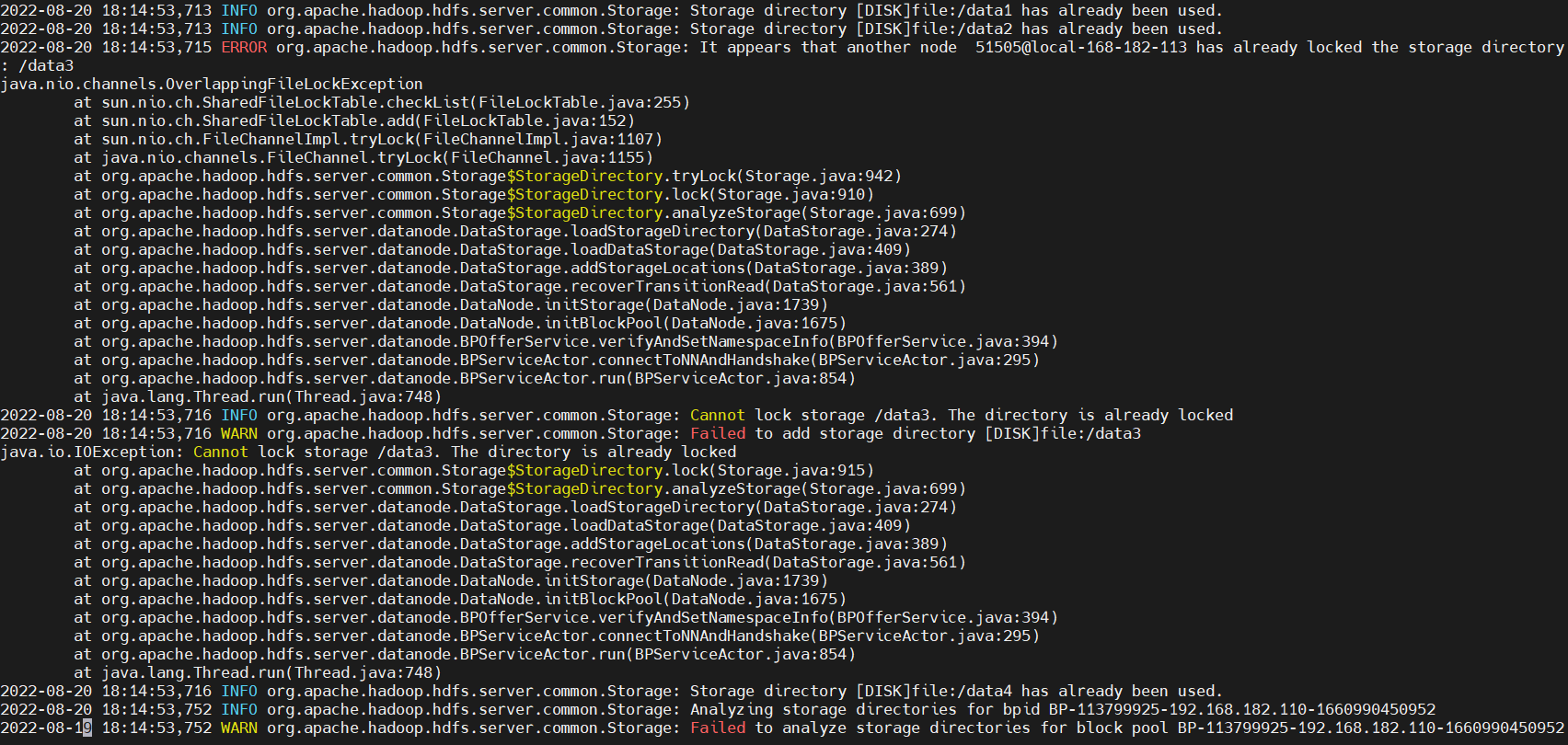
dfs.namenode.name.dir和dfs.datanode.data.dir位置需要不一样,不能是一个文件夹,之前设置成一个文件夹报错ERROR org.apache.hadoop.hdfs.server.common.Storage: It appears that another node 1003@iZ2zeh8q22e14pvqr3bu01Z has already locked the storage directory:
【原因】是当namenode启动后,锁定了文件夹,导致datanode无法启动。
2)配置详解
1、 dfs.datanode.data.dir
HDFS数据应该存储Block的地方。可以是逗号分隔的目录列表(典型的,每个目录在不同的磁盘)。这些目录被轮流使用,一个块存储在这个目录,下一个块存储在下一个目录,依次循环。每个块在同一个机器上仅存储一份。不存在的目录被忽略。必须创建文件夹,否则被视为不存在。
2、dfs.datanode.fsdataset.volume.choosing.policy
当我们往 HDFS 上写入新的数据块,DataNode 将会使用 volume 选择策略来为这个块选择存储的地方。通过参数 dfs.datanode.fsdataset.volume.choosing.policy 来设置,这个参数目前支持两种磁盘选择策略
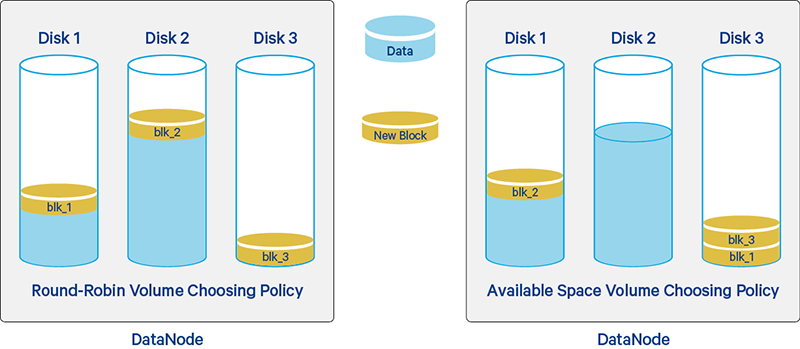
round-robin:循环(round-robin)策略将新块均匀分布在可用磁盘上。配置:org.apache.hadoop.hdfs.server.datanode.fsdataset.RoundRobinVolumeChoosingPolicy;实现类:RoundRobinVolumeChoosingPolicy.javaavailable space:循环(round-robin)策略将新块均匀分布在可用磁盘上。配置:org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy;实现类:AvailableSpaceVolumeChoosingPolicy.java
这两种方式的优缺点:
- 采用轮询卷存储方式虽然能保证每块盘都能得到使用,但是在长期运行的集群中由于数据删除和磁盘热插拔等原因,可能造成磁盘空间的不均。
- 所以最好将磁盘选择策略配置成第二种,根据磁盘空间剩余量来选择磁盘存储数据块,这样能保证节点磁盘数据量平衡IO压力被分散。
3、dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction
它的含义是数据块存储到可用空间多的卷上的概率,仅在 dfs.datanode.fsdataset.volume.choosing.policy 设置为 org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy 时使用。此设置控制将多少百分比的新块分配发送到可用磁盘空间比其他卷更多的卷。此设置应在 0.0 - 1.0 的范围内,但在实践中为 0.5 - 1.0,因为没有理由希望具有较少可用磁盘空间的卷接收更多块分配。
4、dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold
配置各个磁盘的均衡阈值的,默认为10G(10737418240),在此节点的所有数据存储的目录中,找一个占用最大的,找一个占用最小的,如果在两者之差在10G的范围内,那么块分配的方式是轮询。
- 所有的 volumes 磁盘可用空间差距没有超过10G,那么这些磁盘得到的最大可用空间和最小可用空间差值就会很小,这时候就会使用轮询磁盘选择策略来存放副本。
- 如果 volumes 磁盘可用空间相差大于10G,那么可用空间策略会将 volumes 配置中的磁盘按照一定的规则分为highAvailableVolumes 和 lowAvailableVolumes。
重启HDFS集群
stop-dfs.sh && start-dfs.sh
3)动态刷新hdfs/yarn配置
如果线上还有任务在执行,不能重启,可以执行以下命令让修改后的hdfs/yarn配置生效
1、动态刷新hdfs配置
如果是HA集群则在两个namenode节点上执行
# 默认端口是9000
hdfs dfsadmin -fs hdfs://local-168-182-110:8082 -refreshSuperUserGroupsConfiguration
hdfs dfsadmin -fs hdfs://local-168-182-113:8082 -refreshSuperUserGroupsConfiguration
# 查看状态
hdfs haadmin -getAllServiceState
2、动态刷新yarn配置
如果是HA集群则在两个namenode节点上执行
yarn rmadmin -fs hdfs://local-168-182-110:8082 -refreshSuperUserGroupsConfiguration
yarn rmadmin -fs hdfs://local-168-182-113:8082 -refreshSuperUserGroupsConfiguration
# 查看状态
yarn rmadmin -getAllServiceState
4)检查
web地址:
http://local-168-182-110:9870/
http://local-168-182-113:9870/
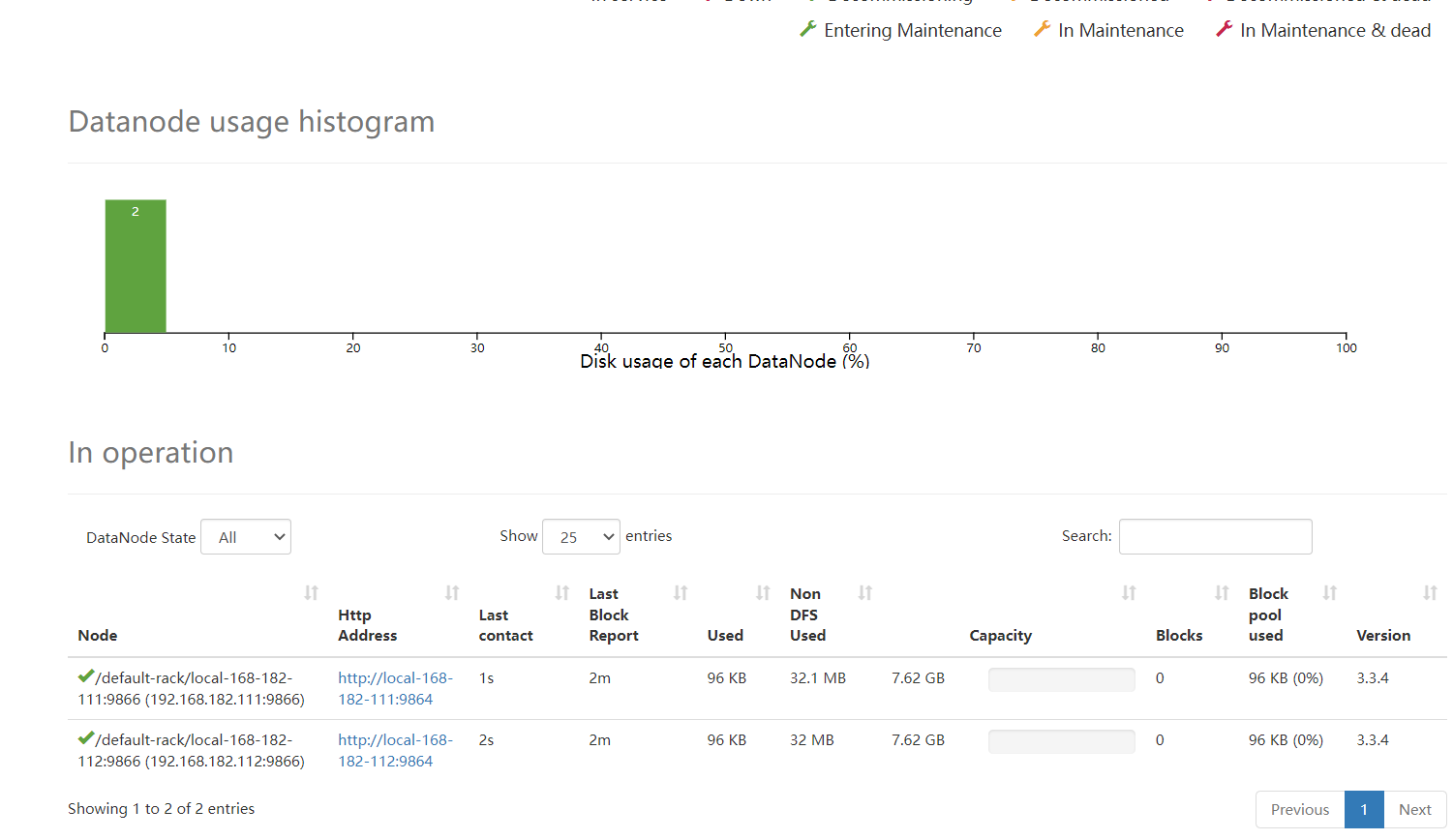
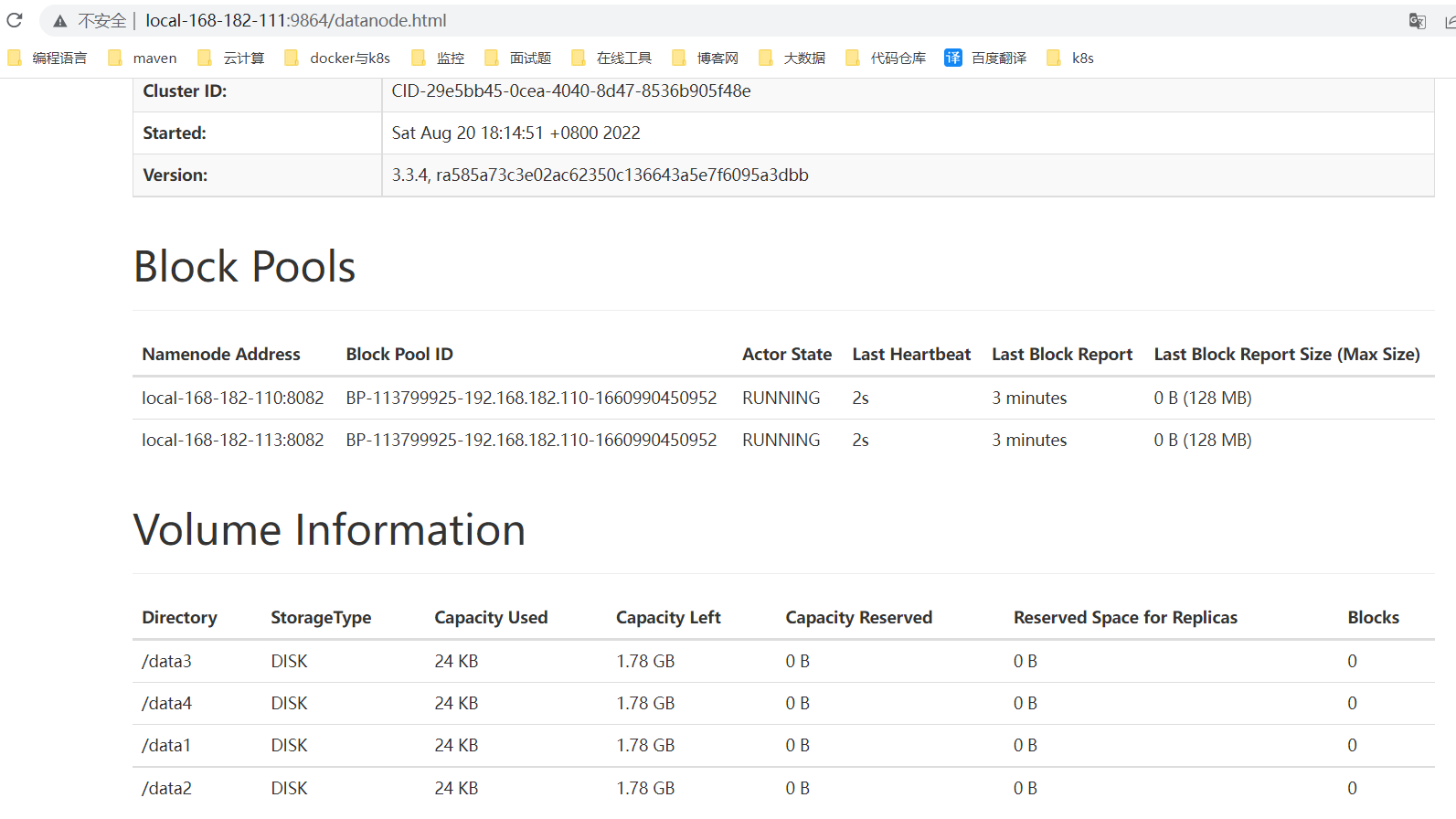
【温馨提示】发现少了一个节点,这是因为namenode与datanode混部,导致磁盘被占的原因。虽然也有一些解决方案,但不是很好,所以建议最好namenode和datanode不要混部。
三、Hadoop HDFS 数据平衡原理
在HDFS中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的
dfs.datanode.data.dir参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。
当我们往HDFS上写入新的数据块,DataNode 将会使用volume选择策略来为这个块选择存储的地方。目前Hadoop支持两种volume选择策略:round-robin 和 available space,我们可以通过dfs.datanode.fsdataset.volume.choosing.policy 参数来设置。
数据平衡过程由于平衡算法的原因造成它是一个迭代的、周而复始的过程。每一次迭代的最终目的是让高负载的机器能够降低数据负载,所以数据平衡会最大程度上地使用网络带宽。下图 数据平衡流程交互图显示了数据平衡服务内部的交互情况,包括 NameNode 和 DataNode。
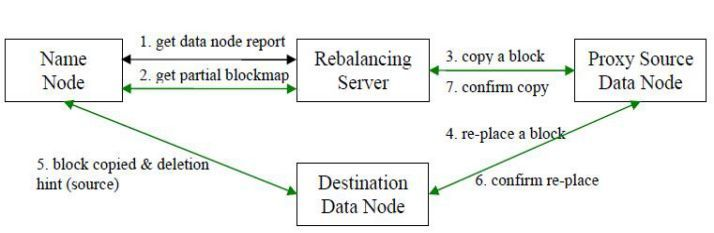
- 数据平衡服务首先要求 NameNode 生成 DataNode 数据分布分析报告。
- 选择所有的 DataNode 机器后,要求 NameNode 汇总数据分布的具体情况。
- 确定具体数据块迁移路线图,保证网络内最短路径,并且确保原始数据块被删除。
- 实际开始数据块迁移任务。
- 数据迁移任务完成后,通过 NameNode 可以删除原始数据块。
- NameNode 在确保满足数据块最低副本条件下选择一块数据块删除。
- NameNode 通知数据平衡服务任务全部完成。
HDFS 数据在各个数据节点间可能保存的格式不一致。当存放新的数据块 (一个文件包含多个数据块) 时,NameNode 在选择数据节点作为其存储地点前需要考虑以下几点因素:
- 当数据节点正在写入一个数据块时,会自动在本节点内保存一个副本。
- 跨节点备份数据块。
- 相同节点内的备份数据块可以节约网络消耗。
- HDFS 数据均匀分布在整个集群的数据节点上。
四、Hadoop HDFS 数据平衡实战操作
格式:
hdfs balancer -help
Usage: java Balancer
[-policy <policy>] the balancing policy: datanode or blockpool
[-threshold <threshold>] Percentage of disk capacity
[-exclude [-f <hosts-file> | comma-sperated list of hosts]] Excludes the specified datanodes.
[-include [-f <hosts-file> | comma-sperated list of hosts]] Includes only the specified datanodes.
参数详解:
-threshold:某datanode的使用率和整个集群使用率的百分比差值阈值,达到这个阈值就启动hdfs balancer,取值从1到100,不宜太小,因为在平衡过程中也有数据写入,太小无法达到平衡,默认值:10-policy:分为blockpool和datanode,前者是block pool级别的平衡后者是datanode级别的平衡,BlockPool 策略平衡了块池级别和 DataNode 级别的存储。BlockPool 策略仅适用于 Federated HDFS 服务-exclude:不为空,则不在这些机器上进行平衡-include:不为空,则仅在这些机器上进行平衡-idleiterations:最大迭代次数
参数调整:
dfs.datanode.balance.bandwidthPerSec= 31457280 ,指定DataNode用于balancer的带宽为30MB,这个示情况而定,如果交换机性能好点的,完全可以设定为50MB,单位是Byte,如果机器的网卡和交换机的带宽有限,可以适当降低该速度,默认是1048576(1MB),hdfs dfsadmin-setBalancerBandwidth 52428800可以通过命令设置-threshold:默认设置为10,参数取值范围0-100,参数含义:判断集群是否平衡的目标参数,每一个 datanode 存储使用率和集群总存储使用率的差值都应该小于这个阀值 ,理论上,该参数设置的越小,整个集群就越平衡,但是在线上环境中,hadoop集群在进行balance时,还在并发的进行数据的写入和删除,所以有可能无法到达设定的平衡参数值dfs.datanode.balance.max.concurrent.moves= 50,指定DataNode上同时用于balance待移动block的最大线程个数dfs.balancer.moverThreads:用于执行block移动的线程池大小,默认1000dfs.balancer.max-size-to-move:每次balance进行迭代的过程最大移动数据量,默认10737418240(10GB)dfs.balancer.getBlocks.size:获取block的数量,默认2147483648(2GB)dfs.balancer.getBlocks.minblock-size:用来平衡的最小block大小,默认10485760(10MB)dfs.datanode.max.transfer.threads:建议为16384),指定用于在DataNode间传输block数据的最大线程数。
简单使用:
# 启动数据平衡,默认阈值为 10%
hdfs balancer
# 默认相差值为10% 带宽速率为10M/s,过程信息会直接打印在客户端 ctrl+c即可中止
hdfs balancer -Ddfs.balancer.block-move.timeout=600000
#可以手动设置相差值 一般相差值越小 需要平衡的时间就越长,//设置为20% 这个参数本身就是百分比 不用带%
hdfs balancer -threshold 20
#如果怕影响业务可以动态设置一下带宽再执行上述命令,1M/s
hdfs dfsadmin -setBalancerBandwidth 1048576
#或者直接带参运行,带宽为1M/s
hdfs balancer -Ddfs.datanode.balance.bandwidthPerSec=1048576 -Ddfs.balancer.block-move.timeout=600000
Hadoop HDFS多目录磁盘扩展配置与数据平衡的介绍与实战操作 就先到这里,有疑问的小伙伴欢迎在评论区留言哦,后续文章更丰富,请小伙伴耐心等待哦~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号