Spark开源REST服务——Apache Livy(Spark 客户端)
一、概述
Livy是一个提供Rest接口和spark集群交互的服务。它可以提交Spark Job或者Spark一段代码,同步或者异步的返回结果;也提供Sparkcontext的管理,通过Restful接口或RPC客户端库。Livy也简化了与Spark与应用服务的交互,这允许通过web/mobile与Spark的使用交互。
- 提交Scala、Python或是R代码片段到远端的Spark集群上执行;
- 提交Java、Scala、Python所编写的Spark作业到远端的Spark集群上执行;
- 提交批处理应用在集群中运行;
- 长时间运行的SparkContext,允许多个spark job和多个client使用;
- 在多个spark job和客户端之间共享RDD和Dataframe;
- 多个sparkcontext可以简单的管理,并运行在集群中而不是Livy Server,以此获取更好的容错性和并行度;
- 作业可以通过重新编译的jar、片段代码、或Java/Scala的客户端API提交。
从Livy所提供的基本功能可以看到Livy涵盖了原生Spark所提供的两种处理交互方式(交互式会话和批处理会话)。与原生Spark不同的是,所有操作都是通过REST的方式提交到Livy服务端上,再由Livy服务端发送到不同的Spark集群上去执行。说到这里我们首先来了解一下Livy的架构。
官网:https://livy.incubator.apache.org/
GitHub地址:https://github.com/apache/incubator-livy
关于Spark的介绍,可以参考我之前的文章:大数据Hadoop之——计算引擎Spark
二、Apache Livy模块介绍
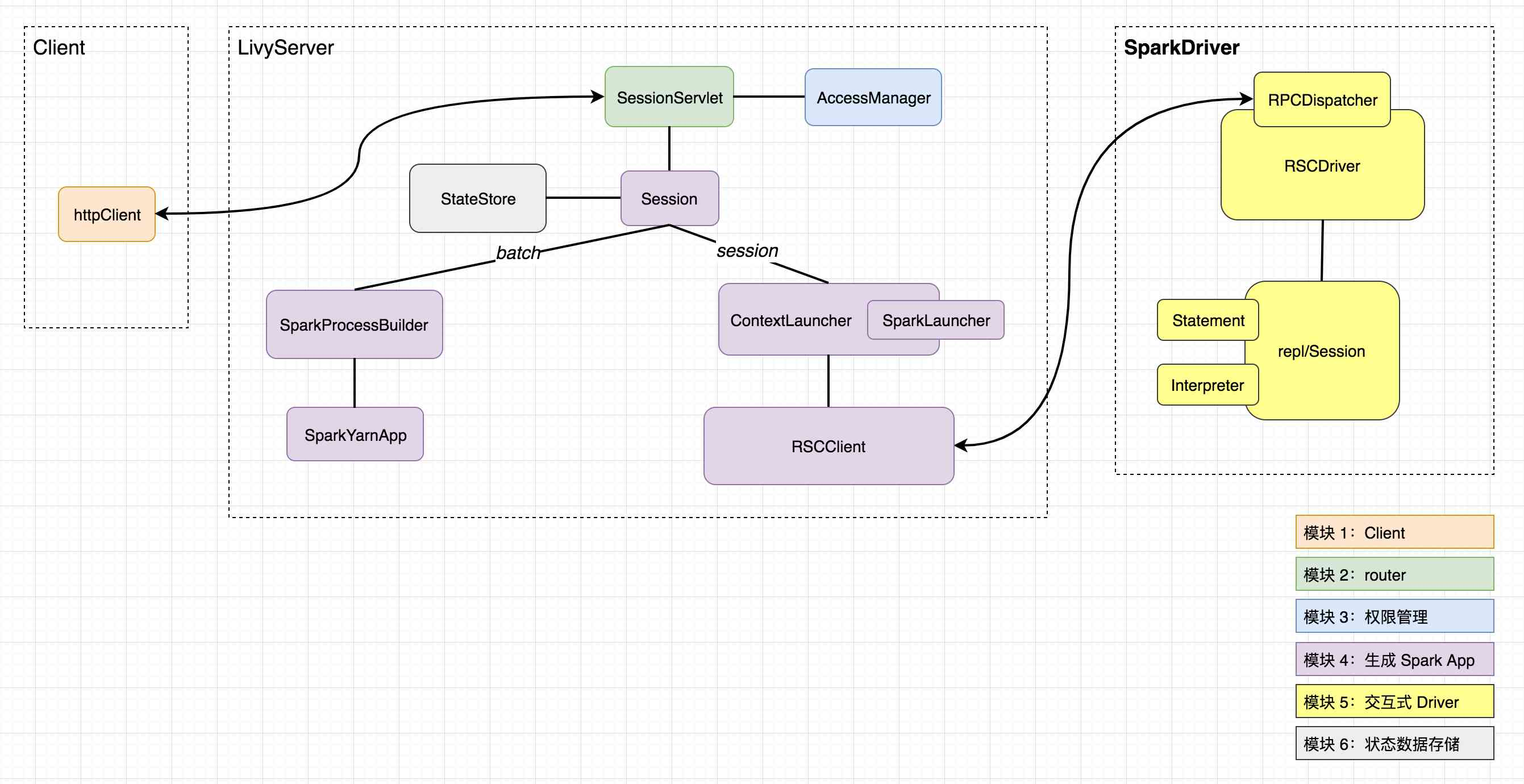
1)Client
Client 并不算 livy 的模块,也很简单,在此略过;
2)router
我们知道,livy server 提供的 api 是 rest api,Client 发送的请求也是针对各个资源(uri)的增删改查。router 的核心职责是管理好要把对什么资源的什么操作指派给哪个类的哪个函数来处理,该模块核心类是
SessionServlet,继承于ScalatraServlet,有两个子类:InteractiveSessionServlet及BatchSessionServlet,分别用来路由对 session 及 batch 相关的请求;
3)权限管理
权限由 AccessManager 类管理,维护了几种不同级别的 user:
- superUser
- modifyUser
- viewUser
- allowedUser
以及不用级别的 acl(访问控制列表): - viewAcls:superUsers ++ modifyUsers ++ viewUsers,对应查看权限
- modifyAcls:superUsers ++ modifyUsers,对应修改权限(包括 kill 权限)
- superAcls:superUsers,有所有权限
- allowedAcls:superUsers ++ modifyUsers ++ viewUsers ++ allowedUsers,表示 acl 的全集
在目前的实现中,livy 的权限管理尚不支持插件化且只有 AccessManager 一种实现,若要定义自己的权限管理,需要直接修改源码。
4)生成 Spark App
对于 session 和 batch 的任务,生成 Spark App 的逻辑及最终生成的 Spark App 都是不同的。先来说说相对简单的生成
session的 Spark App 涉及的主要类:
ContextLauncher——用于启动一个新的 Spark App(通过 SparkLauncher)以及获取如何连接到其 driver 的信息(地址、clientId 及秘钥)。RSCClient——与 Spark Driver 建立连接,向其发送创建、查看状态结果日志、修改statement、job 等请求并获取响应。
接下来是生成 batch 的 Spark App 涉及的主要类:
SparkProcessBuilder——用于从 livyConf 中提取出运行一个 Spark App 所需的一切,包括 mainClass、executableFile、deployMode、conf、master、queue、env 及 driver 和 executors 的资源配置等等;并最终生成一条启动 Spark App 的 spark-submit 命令。SparkYarnApp——用来运行 SparkProcessBuilder 生成的启动命令,并监控管理启动运行起来的 Spark App,包括获取状态、日志、诊断信息、kill 等(目前 livy 只支持 local 和 yarn 两种模式,local 暂不进行介绍)。
5)交互式 Driver
需要注意的是,该模块仅对于 session 任务有,batch 并没有。 该模块中,最核心的类是
RSCDriver,其继承与 RpcDispatcher,RpcDispatcher 接收来自 RSCClient 发送的 rpc 请求,根据请求的类型调用 RSCDriver 相应的方法去处理请求中包含的具体信息,对于最核心的执行代码片段(statement)请求,调用 repl/Session 去处理,repl/Session 最终会根据不同的 session kind 调用不同的 Interpreter 进行真正的代码执行,目前共有 Spark、Scala、Python、R 对应的 Interpreter。
6)状态数据存储
核心类是
StateStore,状态数据的存储都是以 key-value 形式,目前有基于文件系统和 Zookeeper 的实现。另外,SessionStore 继承了该类提供高阶 Api 来进行 sessions 的存储和恢复。
三、Apache Livy架构
1)Livy架构
Livy是一个典型的REST服务架构,它一方面接受并解析用户的REST请求,转换成相应的操作;另一方面它管理着用户所启动的所有Spark集群。具体架构如下图:
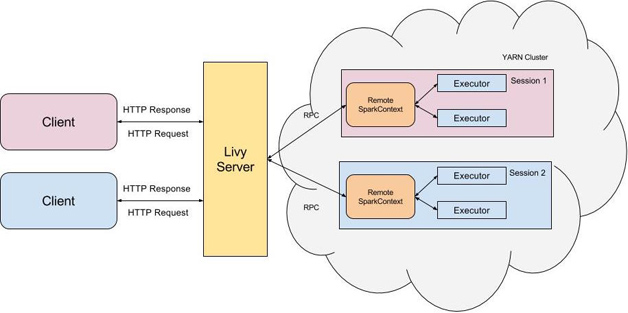
用户可以以REST请求的方式通过Livy启动一个新的Spark集群,Livy将每一个启动的Spark集群称之为一个会话(session),一个会话是由一个完整的Spark集群所构成的,并且通过RPC协议在Spark集群和Livy服务端之间进行通信。根据处理交互方式的不同,Livy将会话分成了两种类型:
-
交互式会话(interactive session)——这与Spark中的交互式处理相同,交互式会话在其启动后可以接收用户所提交的代码片段,在远端的Spark集群上编译并执行;
-
批处理会话(batch session)——用户可以通过Livy以批处理的方式启动Spark应用,这样的一个方式在Livy中称之为批处理会话,这与Spark中的批处理是相同的。
2)Livy执行作业流程
下面这幅图片是Livy的基本原理,客户端提交任务到Livy server后,Livy server启动相应的session,然后提交作业到Yarn集群,当Yarn拉起ApplicationMaster进程后启动SparkContext,并连接到Livy Server进行通信。后续执行的代码会通过Livy server发送到Application进程执行。
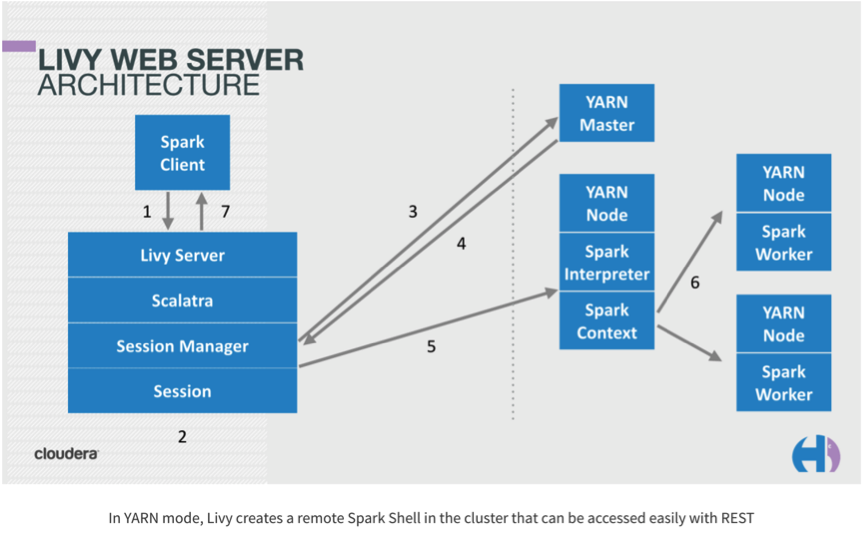
下面是源码级别的详细的执行流程:
- live-server启动,启动BatchSessionManager, InteractiveSessionManager。
- 初始化WebServer,通过ServletContextListener启动InteractiveSessionServlet和BatchSessionServlet。
- 通过http调用SessionServlet的createSession接口,创建session并注册到sessionManager,InteractiveSession和BatchSession会创建SparkYarnApp,SparkYarnApp负责启动Spark作业,并维护yarnclient,获取作业信息、状态或kill作业。
- BatchSession是以jar包的方式提交作业,运行结束后session作业就结束。
- InteractiveSession会启动com.cloudera.livy.repl.ReplDriver,ReplDriver继承RSCDriver,初始化期间会通过RPC连接到livy-server,并启动RpcServer;其次会初始化Interpreter(支持PythonInterpreter,SparkInterpreter,SparkRInterpreter)。接收来自livy-server,并启动RpcServer;其次会初始化Interpreter(支持PythonInterpreter,SparkInterpreter,SparkRInterpreter)。接收来自livy-server的信息(代码),然后通过Interpreter执行,livy-server通过RPC请求作业结果。
四、环境部署
Hadoop环境部署可参考我之前的文章:大数据Hadoop原理介绍+安装+实战操作(HDFS+YARN+MapReduce)
1)下载
Livy下载地址:https://livy.apache.org/download
Livy官方文档:https://livy.apache.org/get-started/
Spark下载地址:http://spark.apache.org/downloads.html
### livy 下载
#cd /opt/bigdata
#wget https://dlcdn.apache.org/incubator/livy/0.7.1-incubating/apache-livy-0.7.1-incubating-bin.zip --no-check-certificate
# 解压
#yum -y install unzip
# unzip apache-livy-0.7.1-incubating-bin.zip
### spark 下载
cd /opt/bigdata
wget https://dlcdn.apache.org/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz --no-check-certificate
tar -xf spark-3.3.0-bin-hadoop3.tgz
为了支持Spark 3.x版本,需要重新编译,其实它对应的是livy 0.8的snapshot版本。
https://stackoverflow.com/questions/67085984/how-to-rebuild-apache-livy-with-scala-2-12
# 下载
git clone https://github.com/apache/incubator-livy.git && cd incubator-livy
修改配置
<profile>
<id>spark-3.3</id>
<activation>
<property>
<name>spark-3.3</name>
</property>
</activation>
<properties>
<spark.scala-2.13.version>3.3.0</spark.scala-2.13.version>
<spark.scala-2.11.version>2.4.5</spark.scala-2.11.version>
<spark.version>${spark.scala-2.11.version}</spark.version>
<netty.spark-2.12.version>4.1.47.Final</netty.spark-2.12.version>
<netty.spark-2.11.version>4.1.47.Final</netty.spark-2.11.version>
<netty.version>${netty.spark-2.11.version}</netty.version>
<java.version>1.8</java.version>
<py4j.version>0.10.9</py4j.version>
<json4s.spark-2.11.version>3.5.3</json4s.spark-2.11.version>
<json4s.spark-2.12.version>3.6.6</json4s.spark-2.12.version>
<json4s.version>${json4s.spark-2.11.version}</json4s.version>
<spark.bin.download.url>
https://dlcdn.apache.org/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz
</spark.bin.download.url>
<spark.bin.name>spark-3.3.0-bin-hadoop3</spark.bin.name>
</properties>
</profile>
<!-- 注释一些运行livy无需的模块 -->
<module>api</module>
<module>assembly</module>
<module>client-common</module>
<module>client-http</module>
<module>core</module>
<module>core/scala-2.11</module>
<module>core/scala-2.12</module>
<!--<module>coverage</module>-->
<!--<module>examples</module>-->
<!--<module>python-api</module>-->
<module>repl</module>
<module>repl/scala-2.11</module>
<module>repl/scala-2.12</module>
<module>rsc</module>
<module>scala</module>
<module>scala-api</module>
<module>scala-api/scala-2.11</module>
<module>scala-api/scala-2.12</module>
<module>server</module>
<module>test-lib</module>
<!--<module>integration-test</module>-->
开始编译
# spark3.3.0
mvn clean package -B -V -e \
-Pspark-3.3.0 \
-Pthriftserver \
-DskipTests \
-DskipITs \
-Dmaven.javadoc.skip=true
解压包
cp assembly/target/apache-livy-0.8.0-incubating-SNAPSHOT-bin.zip .
unzip apache-livy-0.8.0-incubating-SNAPSHOT-bin.zip
这里也提供上面编译好的部署包,有需要的小伙伴可以自行下载:
链接:https://pan.baidu.com/s/1pPCbe0lUJ6ji8rvQYsVw9A?pwd=qn7i
提取码:qn7i
2)配置
- 环境变量设置
vi /etc/profile
export LIVY_HOME=/opt/bigdata/livy-spark/incubator-livy/apache-livy-0.8.0-incubating-SNAPSHOT-bin
export PATH=$LIVY_HOME/bin:$PATH
export SPARK_HOME=/opt/bigdata/spark-3.3.0-bin-hadoop3
export PATH=$SPARK_HOME/bin:$PATH
source /etc/profile
- 修改配置文件
$LIVY_HOME/conf/livy.conf
cp $LIVY_HOME/conf/livy.conf.template $LIVY_HOME/conf/livy.conf
cat >$LIVY_HOME/conf/livy.conf<<EOF
livy.spark.master = yarn
livy.spark.deploy-mode = cluster
livy.environment = production
livy.impersonation.enabled = true
livy.server.csrf_protection.enabled = false
livy.server.port = 8998
livy.server.session.timeout = 3600000
livy.server.recovery.mode = recovery
livy.server.recovery.state-store = filesystem
livy.server.recovery.state-store.url = /tmp/livy
livy.repl.enable-hive-context = true
EOF
- 修改配置文件
$LIVY_HOME/conf/livy-env.sh
cp $LIVY_HOME/conf/livy-env.sh.template $LIVY_HOME/conf/livy-env.sh
mkdir $LIVY_HOME/logs $LIVY_HOME/pid-dir
cat >$LIVY_HOME/conf/livy-env.sh<<EOF
export JAVA_HOME=/opt/jdk1.8.0_212
export HADOOP_HOME=/opt/bigdata/hadoop/hadoop-3.3.4
export HADOOP_CONF_DIR=/opt/bigdata/hadoop/hadoop-3.3.4/etc/hadoop
export SPARK_CONF_DIR=/opt/bigdata/spark-3.3.0-bin-hadoop3/conf
export SPARK_HOME=/opt/bigdata/spark-3.3.0-bin-hadoop3
export LIVY_LOG_DIR=/opt/bigdata/livy-spark/incubator-livy/apache-livy-0.8.0-incubating-SNAPSHOT-bin/logs
export LIVY_PID_DIR=/opt/bigdata/livy-spark/incubator-livy/apache-livy-0.8.0-incubating-SNAPSHOT-bin/pid-dir
export LIVY_SERVER_JAVA_OPTS="-Xmx512m"
EOF
- 修改配置文件
$LIVY_HOME/conf/spark-blacklist.conf
cp $LIVY_HOME/conf/spark-blacklist.conf.template $LIVY_HOME/conf/spark-blacklist.conf
cat >$LIVY_HOME/conf/spark-blacklist.conf<<EOF
spark.master
spark.submit.deployMode
# Disallow overriding the location of Spark cached jars.
spark.yarn.jar
spark.yarn.jars
spark.yarn.archive
# Don't allow users to override the RSC timeout.
livy.rsc.server.idle-timeout
EOF
- 添加Hadoop 配置
$HADOOP_HOME/etc/hadoop/core-site.xml
<property>
<name>hadoop.proxyuser.livy.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.livy.hosts</name>
<value>*</value>
</property>
重启服务
stop-all.sh ; start-all.sh
- HDFS 上面创建livy 的用户目录
hdfs dfs -mkdir -p /user/livy
hdfs dfs -chown livy:supergroup /user/livy
3)启动服务
sh $LIVY_HOME/bin/livy-server start
netstat -tnlp|grep 8998
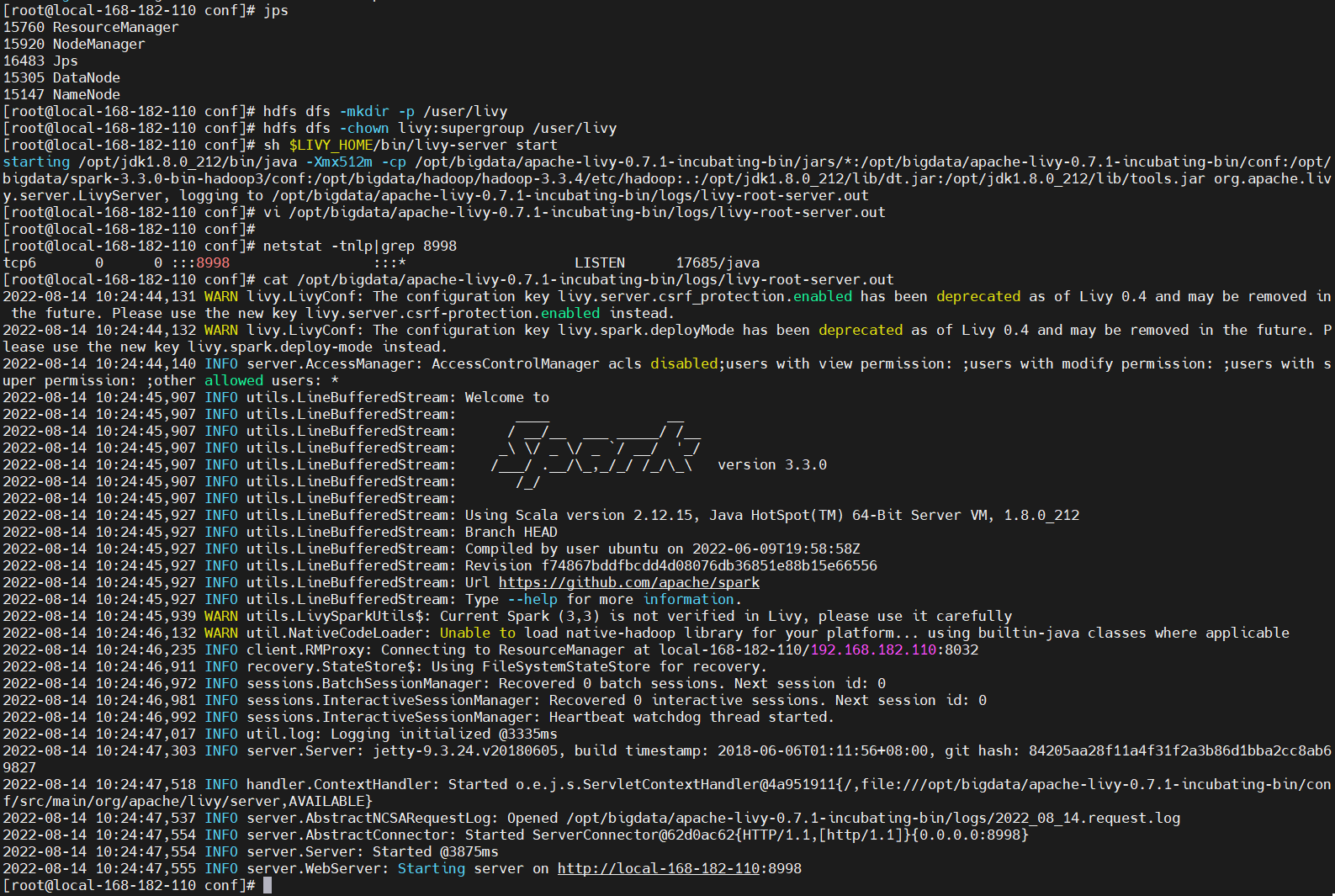
访问Livy web 地址:http://local-168-182-110:8998
五、Livy API 实战操作
rest-api官方文档:https://livy.apache.org/docs/latest/rest-api.html
java-api官方文档:https://livy.apache.org/docs/latest/api/java/index.html
1)创建交互式会话
【温馨提示】修改
livy.spark.deploy-mode = cluster=》livy.spark.deploy-mode = client,因为cluster模式下无法成功运行session,所以standalone模式中,只能采用client模式。
POST /sessions
# 新建Session
curl -XPOST -d '{"kind": "spark"}' -H "Content-Type: application/json" http://local-168-182-110:8998/sessions
#执行结果为:
{
"id":0, -- session id
"name":null,
"appId":null,
"owner":null,
"proxyUser":null,
"state":"starting", -- session 状态
"kind":"spark",
"appInfo":{ -- app 信息
"driverLogUrl":null,
"sparkUiUrl":null
},
"log":[
"stdout: ",
"\nstderr: ",
"\nYARN Diagnostics: "
]
}
使用交互式会话的前提是需要先创建会话。当我们提交请求创建交互式会话时,我们需要指定会话的类型(“kind”),比如“spark”,Livy会根据我们所指定的类型来启动相应的REPL,当前Livy可支持
spark、pyspark或是sparkr三种不同的交互式会话类型以满足不同语言的需求。
提交代码片段测试:
POST /sessions/{sessionId}/statements
curl -XPOST -d '{"code":"sc.makeRDD(List(1,2,3,4)).count"}' -H "Content-Type: application/json" http://local-168-182-110:8998/sessions/0/statements
查询执行结果
GET /sessions/{sessionId}/statements/{statementId}
curl -XPOST -d '{"code":"sc.makeRDD(List(1,2,3,4)).count"}' -H "Content-Type: application/json" http://local-168-182-110:8998/sessions/0/statements/0`
# 输出:
{
"id": 0,
"code": "sc.makeRDD(List(1,2,3,4)).count",
"state": "available",
"output": {
"status": "ok",
"execution_count": 0,
"data": {
"text/plain": "res0: Long = 4\n"
}
},
"progress": 1.0
}
2)批处理会话(Batch Session)
在Spark应用中有一大类应用是批处理应用,这些应用在运行期间无须与用户进行交互,最典型的就是Spark Streaming流式应用。用户会将业务逻辑编译打包成jar包,并通过spark-submit启动Spark集群来执行业务逻辑:
# POST http://local-168-182-110:8998/batches
curl -XPOST -d '{"file":"hdfs://local-168-182-110:8082/user/livy/spark-examples_2.12-3.3.0.jar","className":"org.apache.spark.examples.SparkPi","name":"SparkPi"}' -H "Content-Type: application/json" http://local-168-182-110:8998/batches
# 输出:
{
"id":0,
"name":"SparkPi",
"owner":null,
"proxyUser":null,
"state":"starting",
"appId":null,
"appInfo":{
"driverLogUrl":null,
"sparkUiUrl":null
},
"log":[
"stdout: ",
"\nstderr: ",
"\nYARN Diagnostics: "
]
}
登录livy web查看:http://local-168-182-110:8998/
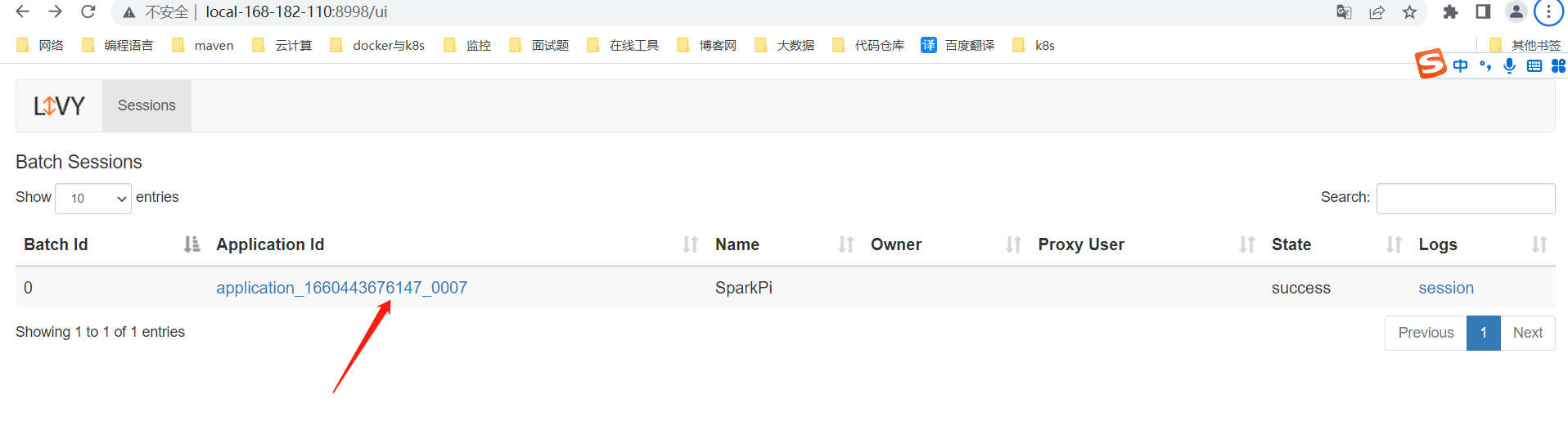
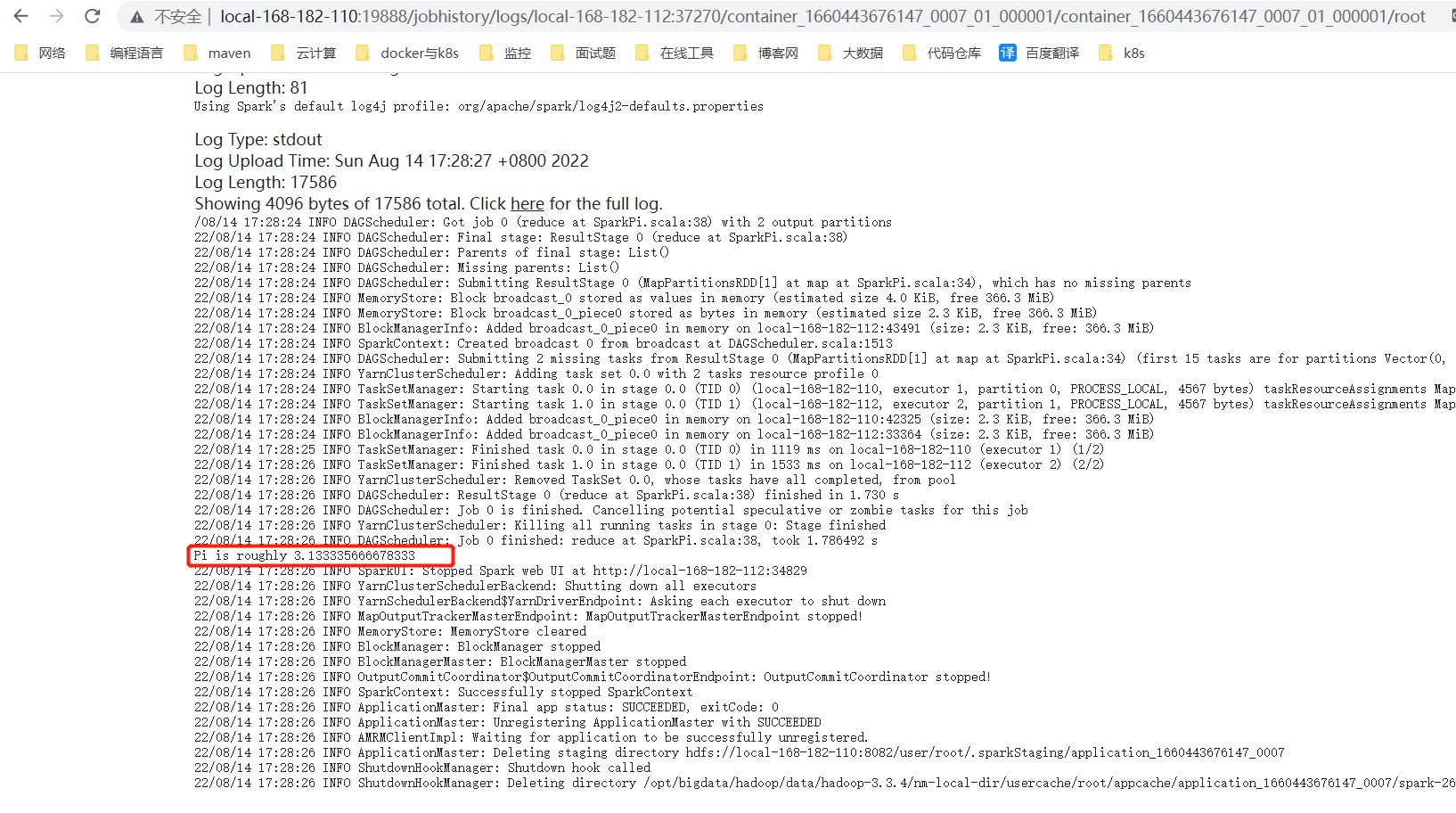
3)查询
curl -X GET http://local-168-182-110:8998/sessions/0
curl -X GET http://local-168-182-110:8998/sessions/0/statements/0
curl -X GET http://local-168-182-110:8998/batches/0
4)删除
# 删除session
curl -X DELETE http://local-168-182-110:8998/sessions/0
# 删除batches
curl -X DELETE http://local-168-182-110:8998/sessions/0
关于更多的livy api操作,可以查看官方文档,如果有什么疑问也欢迎在评论区给我留言~
rest-api官方文档:https://livy.apache.org/docs/latest/rest-api.html
java-api官方文档:https://livy.apache.org/docs/latest/api/java/index.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号