大数据Hadoop之——Spark Streaming原理
一、概述
Spark Streaming是对核心Spark API的一个扩展,它能够实现对实时数据流的流式处理,并具有很好的可扩展性、高吞吐量和容错性。Spark Streaming支持从多种数据源提取数据,如:Kafka、Flume、Twitter、ZeroMQ、Kinesis以及TCP套接字,并且可以提供一些高级API来表达复杂的处理算法,如:map、reduce、join和window等。最后,Spark Streaming支持将处理完的数据推送到文件系统、数据库或者实时仪表盘中展示。实际上,你完全可以将Spark的机器学习(machine learning) 和 图计算(graph processing)的算法应用于Spark Streaming的数据流当中。

二、Spark Streaming基本原理
1)官方文档对Spark Streaming的原理解读
Spark Streaming从实时数据流接入数据,再将其划分为一个个小批量供后续Spark engine处理,所以实际上,Spark Streaming是按一个个小批量来处理数据流的。下图展示了Spark Streaming的内部工作原理:
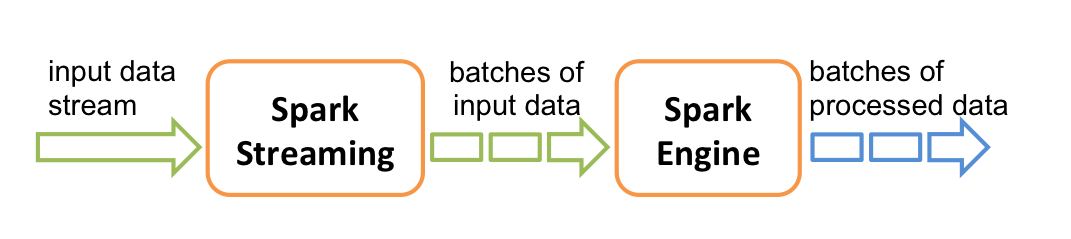
Spark Streaming为这种持续的数据流提供了的一个高级抽象,即:discretized stream(离散数据流)或者叫DStream。DStream既可以从输入数据源创建得来,如:Kafka、Flume或者Kinesis,也可以从其他DStream经一些算子操作得到。其实在内部,一个DStream就是包含了一系列RDDs。
2)框架执行流程
下面将从更细粒度架构角度看Spark Streaming的执行原理,这里先回顾一下Spark框架执行流程。
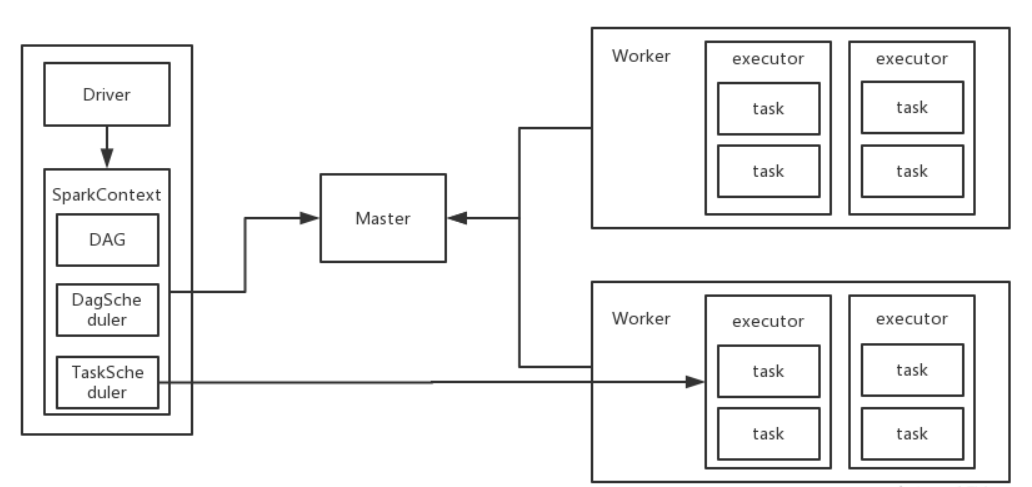
Spark计算平台有两个重要角色,Driver和executor,不论是Standlone模式还是Yarn模式,都是Driver充当Application的master角色,负责任务执行计划生成和任务分发及调度;executor充当worker角色,负责实际执行任务的task,计算的结果返回Driver。
下图是Driver和Ececutor的执行流程。

Driver负责生成逻辑查询计划、物理查询计划和把任务派发给executor,executor接受任务后进行处理,离线计算也是按这个流程进行。
- DAGScheduler:负责将Task拆分成不同Stage的具有依赖关系(包含RDD的依赖关系)的多批任务,然后提交给TaskScheduler进行具体处理。
- TaskScheduler:负责实际每个具体Task的物理调度执行。
下面看Spark Streaming实时计算的执行流程:
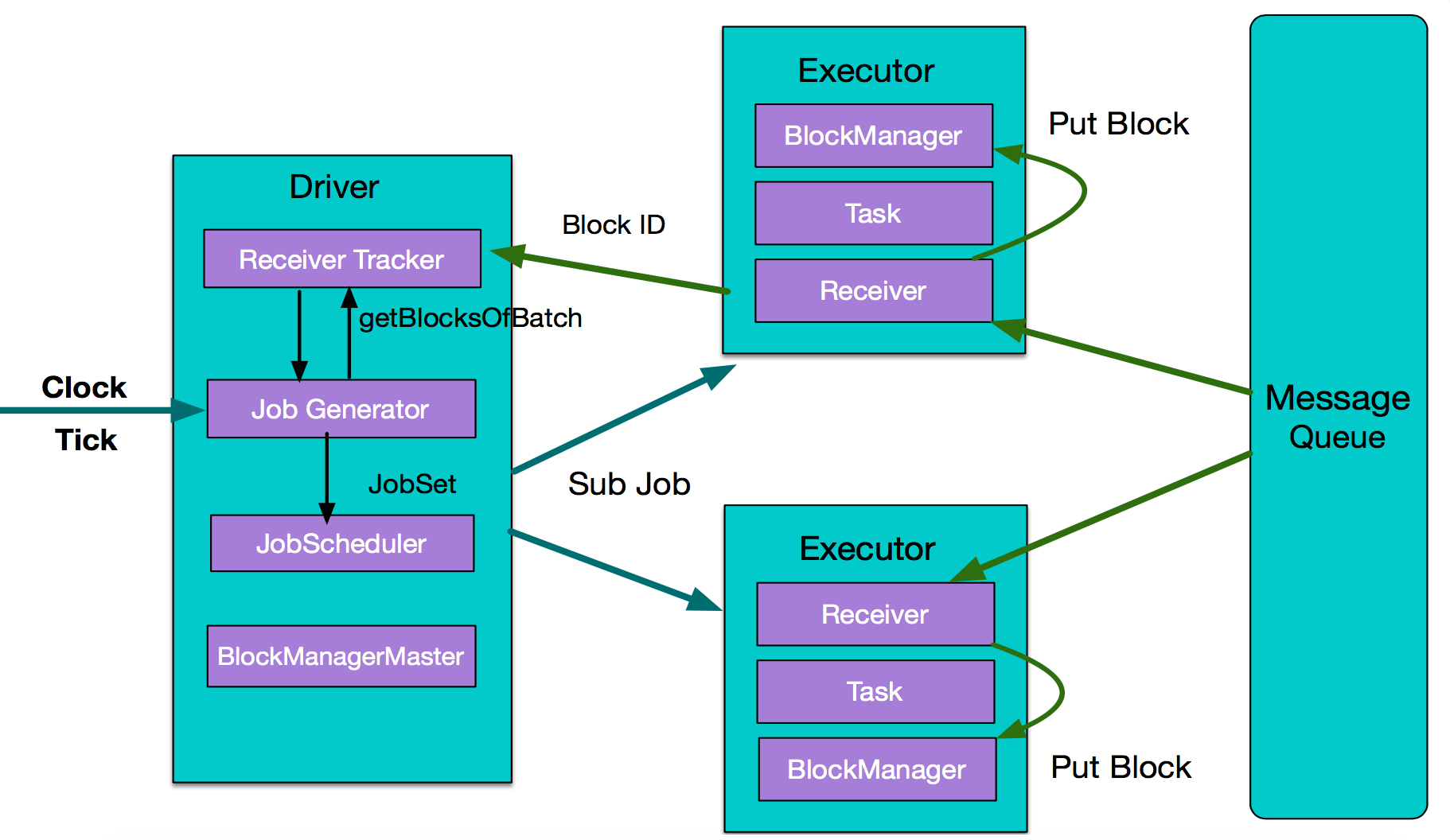
- 从整体上看,实时计算与离线计算一样,主要组件是Driver和Executor的。不同的是多了数据采集和数据按时间分片过程,数据采集依赖外部数据源,这里用MessageQueue表示,数据分片则依靠内部一个时钟Clock,按batch interval来定时对数据分片,然后把每一个batch interval内的数据提交处理。
- Executor从MessageQueue获取数据并交给BlockManager管理,然后把元数据信息BlockID返给driver的Receiver Tracker,driver端的Job Jenerator对一个batch的数据生成JobSet,最后把作业执行计划传递给executor处理。
三、Spark Streaming核心API
SparkStreaming完整的API包括StreamingContext、DStream输入、DStream上的各种操作和动作、DStream输出、窗口操作等。
1)StreamingContext
为了初始化Spark Streaming程序,必须创建一个StreamingContext对象,该对象是Spark Streaming所有流操作的主要入口。一个StreamingContext对象可以用SparkConf对象创建:
import org.apache.spark.*;
import org.apache.spark.api.java.function.*;
import org.apache.spark.streaming.*;
import org.apache.spark.streaming.api.java.*;
import scala.Tuple2;
// Create a local StreamingContext with two working thread and batch interval of 1 second
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
2)DStream输入
DStream输入表示从数据源获取的原始数据流。每个输入流DStream和一个接收器(receiver)对象相关联,这个Receiver从源中获取数据,并将数据存入内存中用于处理。
Spark Streaming有两类数据源:
- 基本源(basic source):在StreamingContext API中直接可用的源头,例如文件系统、套接字连接、Akka的actor等。
- 高级源(advanced source):包括 Kafka、Flume、Kinesis、Tiwtter等,他们需要通过额外的类来使用。
3)DStream的转换
和RDD类似,transformation用来对输入DStreams的数据进行转换、修改等各种操作,当然,DStream也支持很多在Spark RDD的transformation算子。
| 转换操作(transformation) | 含义(Meaning) |
|---|---|
| map(func) | 利用函数func处理原DStream的每个元素,返回一个新的DStream. |
| flatMap(func) | 与map相似,但是每个输入项可用被映射0个或多个输出项 |
| filter(func) | 返回一个新的DStream,它仅包含源DStream中满足函数func的项 |
| repartition(numPartitions) | 通过创建更多或更少的的partition改变这个DStream的并行级别(level ofparallelism) |
| union(otherStream) | 返回一个新的DStream,它包含源DStream和otherStream的联合元素 |
| count() | 通过计算源DStream中每个RDD的元素数量,返回一个包含单元素RDD的新DStream |
| reduce(func) | 利用函数func聚集源DStream中每个RDD的元素,返回一个包含单元素RDD的新的DStream。函数应该是相关联的,以使计算可以并行化 |
| countByValue() | 这个算子应用于元素类型为K的DStream上,返回一个(Kjong)前的新DStreamo每个键的值是在原DStream的每个RDD的频率 |
| reduceByKey(func, [numTasks]) | 当在一个由(K,V)对组成的DStream上调用这个算子,返回一个新的由(K,V)对组成的DStream,每一个key的值均有给定的reduce函数聚集起来。注意:在默认情况下,这个算子利用了 Spark默认的并发任务数去分组。可以用numTasks参数设置不同的任务数 |
| join(otherStream, [numTasks]) | 当应用于两个DStream(一个包含(K,V)对,一个包含(K,W)对,返回一个包含(K,(V,W))对的新的 DStream |
| cogroup(otherStream, [numTasks]) | 当应用于两个DStream(一个包含(K,V)对,一个包含(K,W)对,返回一个包含(K,Seq[VJSeq[WN 的元组 |
| transform(func) | 通过对源DStream的每个RDD应用RDD-to-RDD函数,创建一个新的DStreamo这个可以在DStream中的任何RDD操作中使用 |
| updateStateByKey(func) | 利用给定的函数更新DStream状态,返回一个新“state”的DStream |
4)DStream的输出
和RDD类似,Spark Streaming允许将DStream转换后的结果发送到数据库、文件系统等外部系统中。目前,定义了Spark Streaming的输出操作:
| 转换操作(transformation) | 含义(Meaning) |
|---|---|
| print() | 在运行流应用程序的驱动程序节点上打印数据流中每批数据的前十个元素。这对于开发和调试非常有用。Python API在Python API中称为pprint()。 |
| saveAsTextFiles(prefix, [suffix]) | 将此数据流的内容另存为文本文件。每个批处理间隔的文件名基于前缀和后缀生成:“prefix-TIME_IN_MS[.suffix]”。 |
| saveAsObjectFiles(prefix, [suffix]) | 将此数据流的内容另存为序列化Java对象的SequenceFile。每个批处理间隔的文件名基于前缀和后缀生成:“prefix-TIME_IN_MS[.suffix]”。Python API这在Python API中不可用。 |
| saveAsHadoopFiles(prefix, [suffix]) | 将此数据流的内容另存为Hadoop文件。每个批处理间隔的文件名基于前缀和后缀生成:“prefix-TIME_IN_MS[.suffix]”。Python API这在Python API中不可用。 |
| foreachRDD(func) | 对从流生成的每个RDD应用函数func的最通用的输出运算符。此函数应将每个RDD中的数据推送到外部系统,例如将RDD保存到文件中,或通过网络将其写入数据库。请注意,函数func是在运行流应用程序的驱动程序进程中执行的,其中通常包含RDD操作,这些操作将强制计算流RDD。 |
5)窗口操作
Spark Streaming 还提供窗口计算,允许您在数据的滑动窗口上应用转换。下图说明了这个滑动窗口:

如图所示,每次窗口滑过一个源 DStream 时,落入窗口内的源 RDD 被组合并操作以产生窗口化 DStream 的 RDD。在这种特定情况下,该操作应用于最后 3 个时间单位的数据,并滑动 2 个时间单位。这说明任何窗口操作都需要指定两个参数。
- windowLength:窗口的持续时间(图中 3)。
- slideInterval :执行窗口操作的间隔(图中为 2)。
一些常见的窗口操作如下。所有这些操作都采用上述两个参数 - windowLength和slideInterval。
| 转换操作(transformation) | 含义(Meaning) |
|---|---|
| window(windowLength, slideInterval) | 返回一个新的 DStream,它是根据源 DStream 的窗口批次计算的。 |
| countByWindow(windowLength, slideInterval) | 返回流中元素的滑动窗口计数。 |
| reduceByWindow(func, windowLength, slideInterval) | 返回一个新的单元素流,它是通过使用func在滑动间隔内聚合流中的元素而创建的。该函数应该是关联的和可交换的,以便它可以被正确地并行计算。 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 当在 (K, V) 对的 DStream 上调用时,返回一个新的 (K, V) 对 DStream,其中每个键的值使用给定的 reduce 函数func 在滑动窗口中的批次上聚合。注意:默认情况下,这使用 Spark 的默认并行任务数(本地模式为 2,在集群模式下,数量由 config 属性决定spark.default.parallelism)进行分组。您可以传递一个可选 numTasks参数来设置不同数量的任务。 |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | reduceByKeyAndWindow()其中每个窗口的减少值是使用前一个窗口的减少值递增计算的。这是通过减少进入滑动窗口的新数据,并“逆减少”离开窗口的旧数据来完成的。一个例子是在窗口滑动时“添加”和“减去”键的计数。但是,它只适用于“可逆归约函数”,即那些具有相应“逆归约”函数(作为参数invFunc)的归约函数。跟reduceByKeyAndWindow一样,reduce 任务的数量可通过可选参数进行配置。请注意,必须启用检查点才能使用此操作。 |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | 当在 (K, V) 对的 DStream 上调用时,返回一个新的 (K, Long) 对 DStream,其中每个键的值是其在滑动窗口内的频率。与 in 一样 reduceByKeyAndWindow,reduce 任务的数量可通过可选参数进行配置。 |
更多操作详情,请参考官方文档:https://spark.apache.org/docs/latest/streaming-programming-guide.html
四、Spark下一代实时计算框架Structured Streaming
1)简介
从Spark 2.0开始,Spark Streaming引入了一套新的流计算编程模型:Structured Streaming,开发这套API的主要动因是自Spark 2.0之后,以RDD为核心的API逐步升级到Dataset/DataFrame上,而另一方面,以RDD为基础的编程模型对开发人员的要求较高,需要有足够的编程背景才能胜任Spark Streaming的编程工作,而新引入的Structured Streaming模型是把数据流当作一个没有边界的数据表来对待,这样开发人员可以在流上使用Spark SQL进行流处理,这大大降低了流计算的编程门槛。
下图为Structure Streaming逻辑数据结构图:
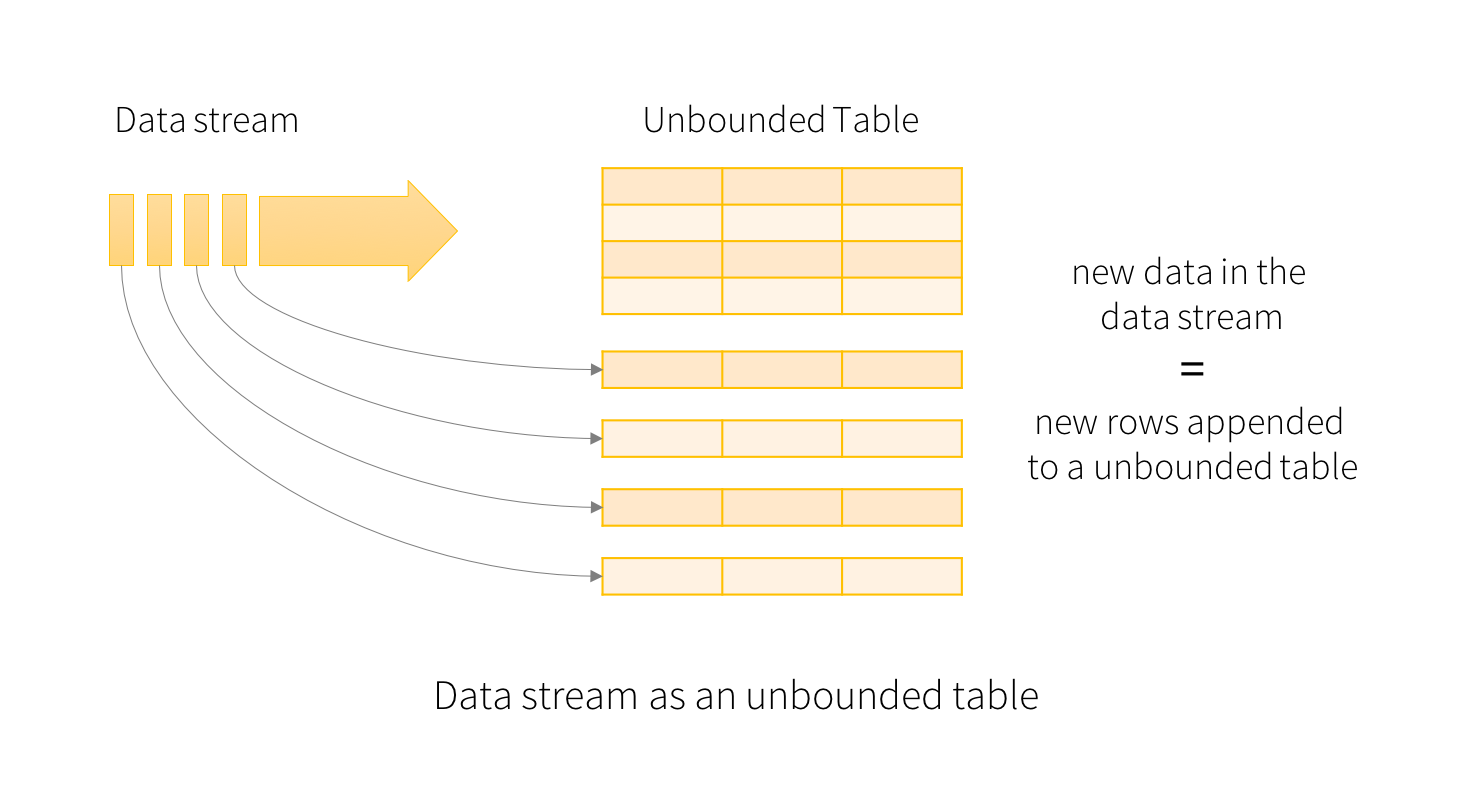
这里以wordcount为例的计算过程如下图:
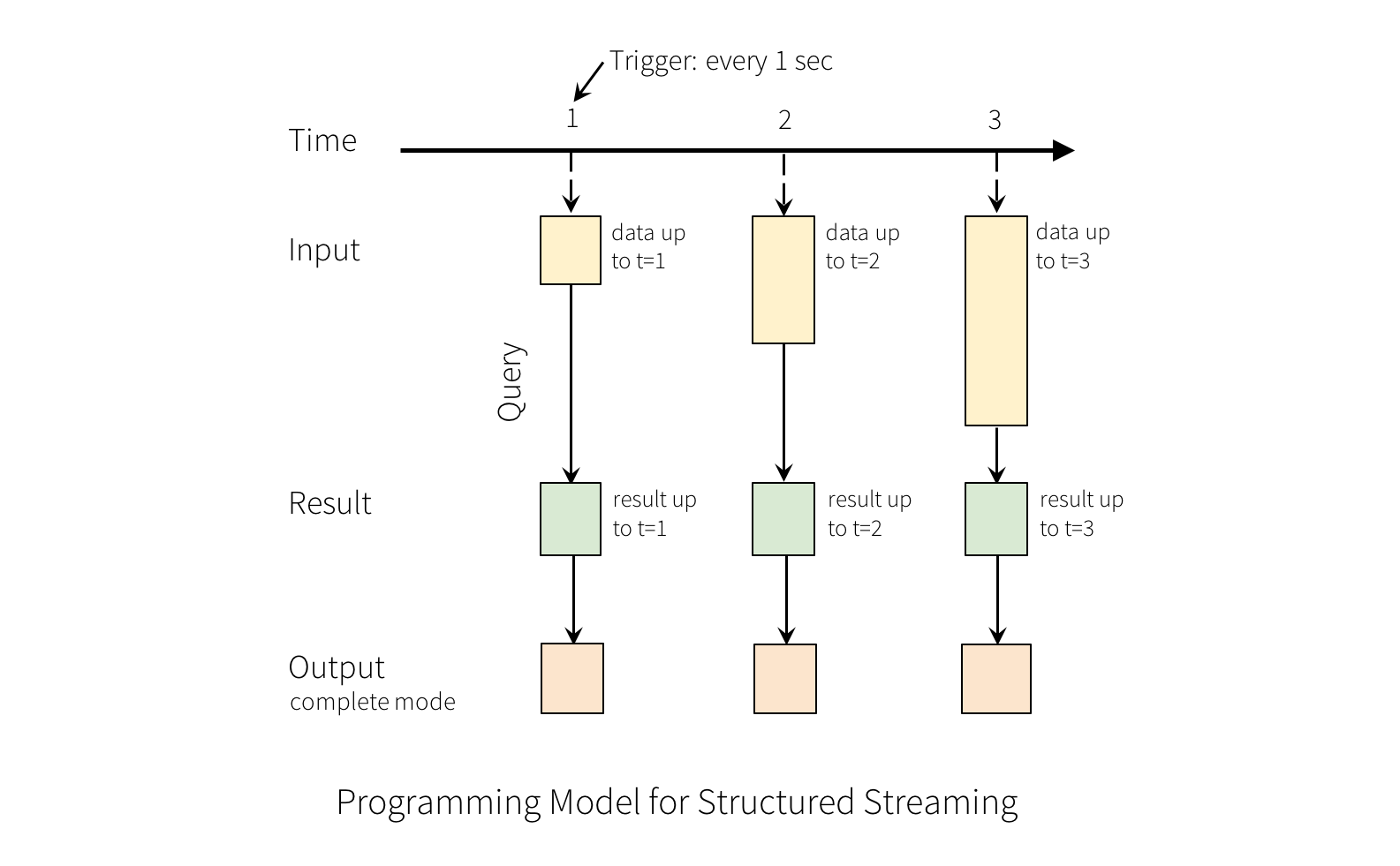
图中Time横轴是时间轴,随着时间,在1、2、3秒分别输入数据,进入wordcount算法计算聚合,输出结果。更对关于Structure Streaming可以参考官网:https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
2) Spark streaming 和 Spark Structured Streaming的对比
| 对比项 | Spark Streaming | Structured Streaming |
|---|---|---|
| 流模型 | Spark Streaming是spark最初的流处理框架,使用了微批的形式来进行流处理,微批终究是批。每一个批处理间隔的为一个批,也就是一个RDD,我们对RDD进行操作就可以源源不断的接收、处理数据。 | Spark 2.X出来的流框架,采用了无界表的概念,流数据相当于往一个表上连续追加行,流上的每一条数据都类似于将一行新数据添加到表中。 |
| 操作对象 | Dtream编程接口是RDD | 使用 DataFrame、DataSet 的编程接口,处理数据时可以使用Spark SQL中提供的方法 |
| 时延 | 接收到数据时间窗口,秒级 | 实时处理数据,毫秒级 |
| 可靠性 | Checkpoint 机制 | Checkpoint 机制 |
| Sink | 提供了 foreachRDD()方法,通过自己编程实现将每个批的数据写出 | 提供了一些 sink(Console Sink、File Sink、Kafka Sink等),只要通过option配置就可以使用;对于需要自定义的Sink,提供了ForeachWriter的编程接口,实现相关方法就可以完成 |
| Spark Streaming |
-
Spark Streaming是spark最初的流处理框架,使用了微批的形式来进行流处理。
-
提供了基于RDDs的Dstream API,每个时间间隔内的数据为一个RDD,源源不断对RDD进行处理来实现流计算。
-
Spark Streaming采用微批的处理方法,微批终究是批。每一个批处理间隔的为一个批,也就是一个RDD,我们对RDD进行操作就可以源源不断的接收、处理数据。
Spark Structured Streaming
-
Spark 2.X出来的流框架,采用了无界表的概念,流数据相当于往一个表上不断追加行。
-
基于Spark SQL引擎实现,可以使用大多数Spark SQL的function。
-
Structured Streaming将实时数据当做被连续追加的表。流上的每一条数据都类似于将一行新数据添加到表中。
3)对比其它实时计算框架
为了展示结构化流的独特之处,下表将其与其他几个系统进行了比较。正如我们所讨论的,Structured Streaming 对前缀完整性的强大保证使其等同于批处理作业,并且易于集成到更大的应用程序中。此外,在 Spark 上构建可以与批处理和交互式查询集成。

-
从延迟看:Storm和Flink原生支持流计算,对每条记录处理,毫秒级延迟,是真正的实时计算,对延迟要求较高的应用建议选择这两种。Spark Streaming的延迟是秒级。Flink是目前最火的实时计算引擎,也是公司用的最多的实时计算引擎,出来的晚,但是发展迅猛。
-
从容错看 :Spark Streaming和Flink都支持最高的exactly-once容错级别,Storm会有记录重复计算的可能
-
从吞吐量看 :Spark Streaming是小批处理,故吞吐量会相对更大。
-
从成熟度看: Storm最成熟,Spark其次,Flink处于仍处于发展中,这三个项目都有公司生产使用,但毕竟开源项目,项目越不成熟,往往越要求公司大数据平台研发水平。
-
从整合性看:Storm与SQL、机器学习和图计算的结合复杂性最高;而Spark和Flink都有生态圈内对应的SQL、机器学习和图计算,与这些项目结合更容易。
【参考资料】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号