大数据Hadoop之——计算引擎Spark
一、概述
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。官方地址
1)Spark特点
- 高效性:不同于MapReduce将中间计算结果放入磁盘中,Spark采用内存存储中间计算结果,减少了迭代运算的磁盘IO,并通过并行计算DAG图的优化,减少了不同任务之间的依赖,降低了延迟等待时间。内存计算下,Spark 比 MapReduce 快100倍。
- 通用性:Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。
- 易用性:不同于MapReduce仅支持Map和Reduce两种编程算子,Spark提供了超过80种不同的Transformation和Action算子,如map,reduce,filter,groupByKey,sortByKey,foreach等,并且采用函数式编程风格,实现相同的功能需要的代码量极大缩小。
- 兼容性:Spark能够跟很多开源工程兼容使用。如Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且Spark可以读取多种数据源,如HDFS、HBase、MySQL等。
- 容错性高:Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
- 适用场景广泛:大数据分析统计,实时数据处理,图计算及机器学习。
2)Spark适用场景
- 复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时。
- 基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间。
- 基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间。
二、Spark核心组件
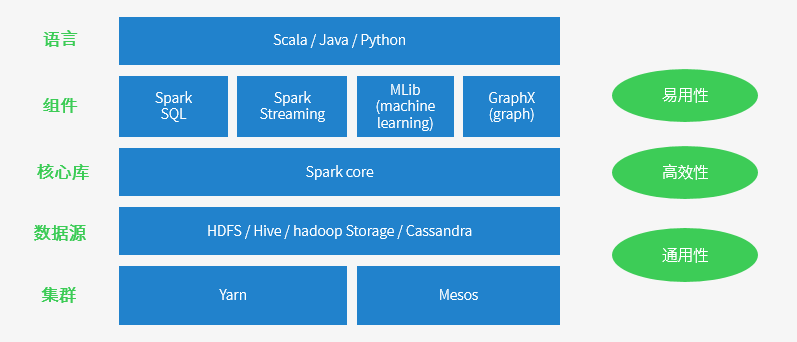
- Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。Spark提供的sql形式的对接Hive、JDBC、HBase等各种数据渠道的API,用Java开发人员的思想来讲就是面向接口、解耦合,ORMapping、Spring Cloud Stream等都是类似的思想。
- Spark Streaming:基于SparkCore实现的可扩展、高吞吐、高可靠性的实时数据流处理。支持从Kafka、Flume等数据源处理后存储到HDFS、DataBase、Dashboard中。对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
三、Spark专业术语详解
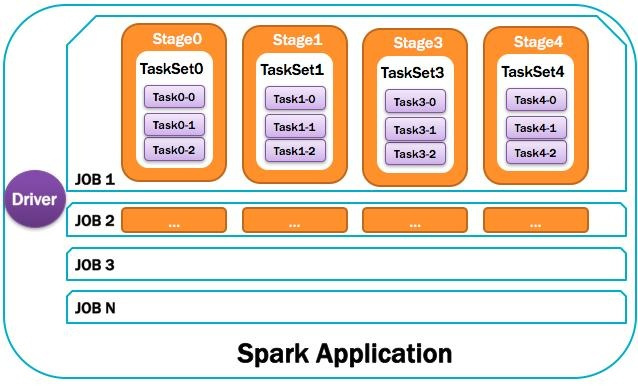
1)Application:Spark应用程序
指的是用户编写的Spark应用程序,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码。Spark应用程序,由一个或多个作业JOB组成,如下图所示:

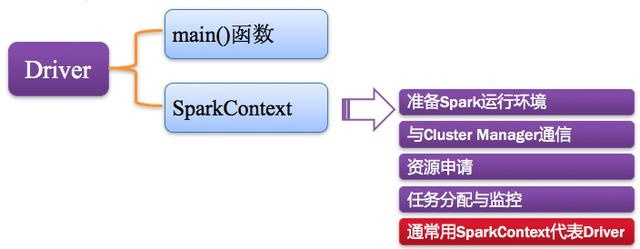
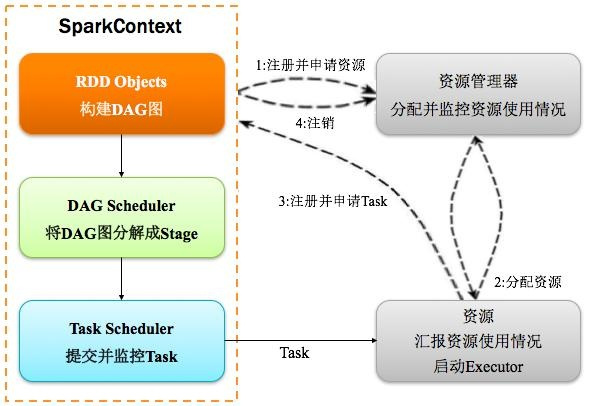
2)Driver:驱动程序
Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常SparkContext代表Driver,如下图所示:
3)Cluster Manager:资源管理器
指的是在集群上获取资源的外部服务,常用的有:Standalone,Spark原生的资源管理器,由Master负责资源的分配;Haddop Yarn,由Yarn中的ResearchManager负责资源的分配;Messos,由Messos中的Messos Master负责资源管理。
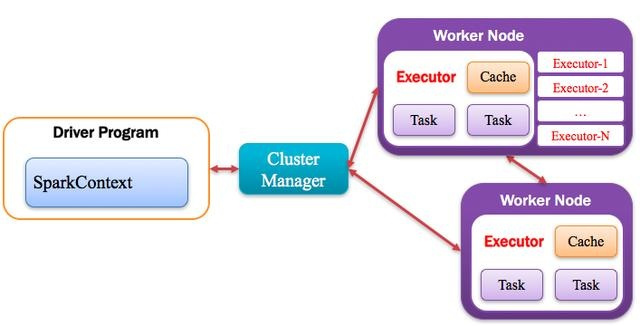
4)Executor:执行器
Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor,如下图所示:
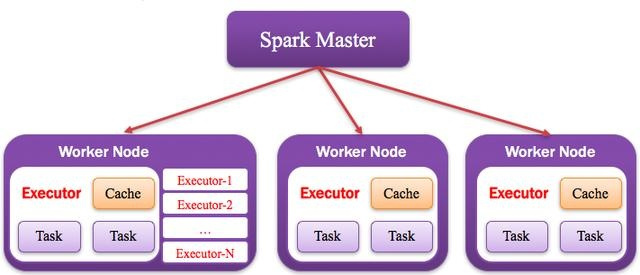
5)Worker:计算节点
集群中任何可以运行Application代码的节点,类似于Yarn中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点,在Spark on Messos模式中指的就是Messos Slave节点,如下图所示:
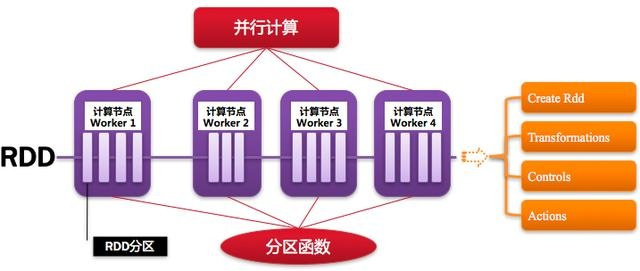
6)RDD:弹性分布式数据集
Resillient Distributed Dataset,Spark的基本计算单元,可以通过一系列算子进行操作(主要有Transformation和Action操作),如下图所示:
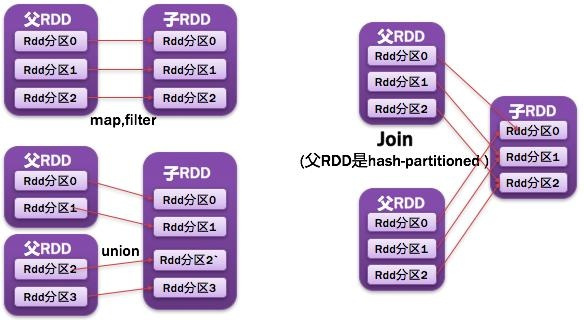
7)窄依赖
父RDD每一个分区最多被一个子RDD的分区所用;表现为一个父RDD的分区对应于一个子RDD的分区,或两个父RDD的分区对应于一个子RDD 的分区。如图所示:
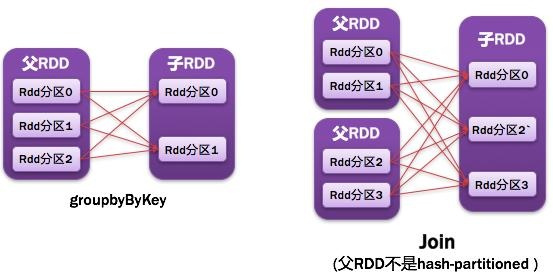
8)宽依赖
父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区。如图所示:
- 常见的窄依赖有:map、filter、union、mapPartitions、mapValues、join(父RDD是hash-partitioned :如果JoinAPI之前被调用的RDD API是宽依赖(存在shuffle), 而且两个join的RDD的分区数量一致,join结果的rdd分区数量也一样,这个时候join api是窄依赖)。
- 常见的宽依赖有groupByKey、partitionBy、reduceByKey、join(父RDD不是hash-partitioned :除此之外的,rdd 的join api是宽依赖)。
9)DAG:有向无环图
Directed Acycle graph,反应RDD之间的依赖关系,如图所示:

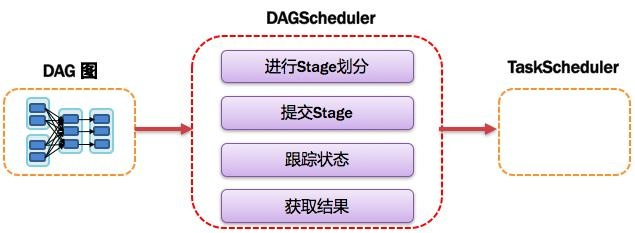
10)DAGScheduler:有向无环图调度器
基于DAG划分Stage 并以TaskSet的形势提交Stage给TaskScheduler;负责将作业拆分成不同阶段的具有依赖关系的多批任务;最重要的任务之一就是:计算作业和任务的依赖关系,制定调度逻辑。在SparkContext初始化的过程中被实例化,一个SparkContext对应创建一个DAGScheduler。如图所示:
11)TaskScheduler:任务调度器
将Taskset提交给worker(集群)运行并回报结果;负责每个具体任务的实际物理调度。如图所示:
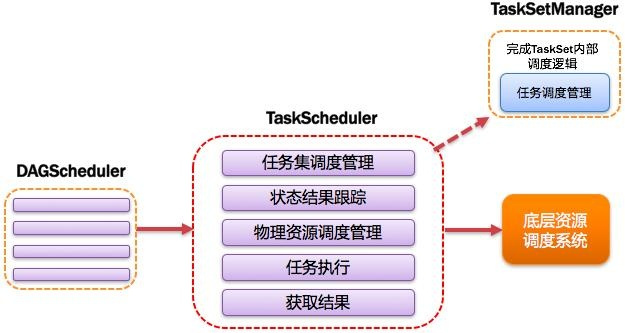
12)Job:作业
由一个或多个调度阶段所组成的一次计算作业;包含多个Task组成的并行计算,往往由Spark Action催生,一个JOB包含多个RDD及作用于相应RDD上的各种Operation。如图所示:
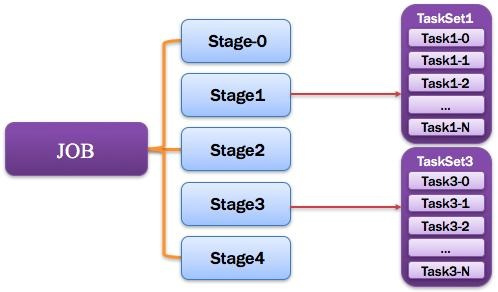
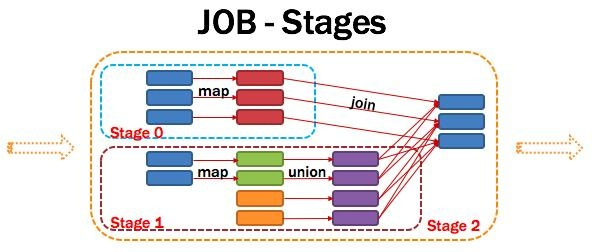
13)Stage:调度阶段
一个任务集对应的调度阶段;每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段;Stage分成两种类型ShuffleMapStage、ResultStage。如图所示:
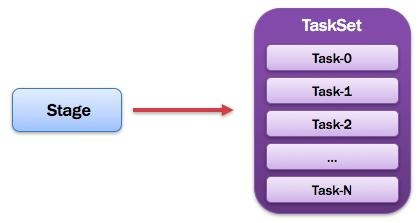
14)TaskSet:任务集
由一组关联的,但相互之间没有Shuffle依赖关系的任务所组成的任务集。如图所示:
15)Task:任务
被送到某个Executor上的工作任务;单个分区数据集上的最小处理流程单元。如图所示:
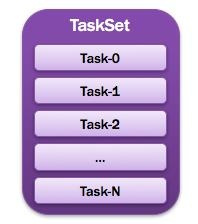
总体如图所示:
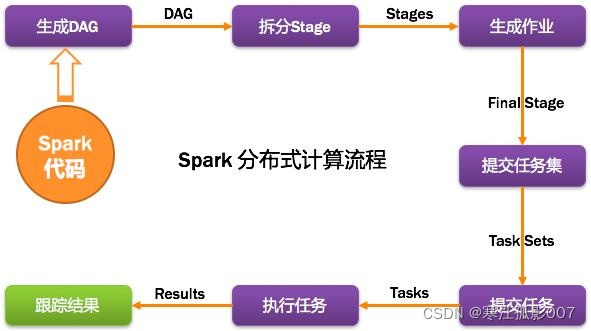
四、Spark运行基本流程

计算流程:
七,Spark支持的资源管理器
Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了,Spark支持资源管理器包含: Standalone(Spark)、On Mesos、On YARN、Or On K8S,当然还有local模式。
| 模式 | 含义 |
|---|---|
| local | 在本地运行,只有一个工作进程,无并行计算能力 |
| local[K] | 在本地运行,有 K 个工作进程,通常设置 K 为机器的CPU 核心数量 |
| local[*] | 在本地运行,工作进程数量等于机器的 CPU 核心数量。 |
| spark://HOST:PORT | 以 Standalone 模式运行,这是 Spark 自身提供的集群运行模式,默认端口号: 7077 |
| mesos://HOST:PORT | 在 Mesos 集群上运行,Driver 进程和 Worker 进程运行在 Mesos 集群上,部署模式必须使用固定值:--deploy-mode cluster |
| yarn | 在yarn集群上运行,依赖于hadoop集群,yarn资源调度框架,将应用提交给yarn,在ApplactionMaster(相当于Stand alone模式中的Master)中运行driver,在集群上调度资源,开启excutor执行任务。 |
| k8s | 在k8s集群上运行 |
七、Spark环境搭建(Spark on Yarn)
1)下载
Spark下载地址:http://spark.apache.org/downloads.html

这里需要注意版本,我的hadoop版本是3.3.1,这里spark就下载最新版本的3.2.0,而Spark3.2.0依赖的Scala的2.13,所以后面用到Scala编程时注意Scala的版本。
$ cd /opt/bigdata/hadoop/software
# 下载
$ wget https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz
# 解压
$ tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /opt/bigdata/hadoop/server/
2)修改配置文件
# 进入spark配置目录
$ cd /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/conf
# copy 一个模板配置
$ cp spark-env.sh.template spark-env.sh
在spark-env.sh下加入如下配置
# Hadoop 的配置文件目录
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# YARN 的配置文件目录
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# SPARK 的目录
export SPARK_HOME=/opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2
# SPARK 执行文件目录
export PATH=$SPARK_HOME/bin:$PATH
复制/opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2 到其它节点
$ scp -r /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2 hadoop-node2:/opt/bigdata/hadoop/server/
$ scp -r /opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2 hadoop-node3:/opt/bigdata/hadoop/server/
3)配置环境变量
在/etc/profile文件中追加如下内容:
export SPARK_HOME=/opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2
export PATH=$SPARK_HOME/bin:$PATH
source 加载生效
$ source /etc/profile
4)运行SparkPi(圆周率) 测试验证
spark-submit 详细参数说明
| 参数名 | 参数说明 |
|---|---|
| --master | master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local |
| --deploy-mode | 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client |
| --class | 应用程序的主类,仅针对 java 或 scala 应用 |
| --name | 应用程序的名称 |
| --jars | 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下 |
| --packages | 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标 |
| --exclude-packages | 为了避免冲突 而指定不包含的 package |
| --repositories | 远程 repository |
| --conf PROP=VALUE | 指定 spark 配置属性的值, 例如 -conf spark.executor.extraJavaOptions="-XX:MaxPermSize=256m" |
| --properties-file | 加载的配置文件,默认为 conf/spark-defaults.conf |
| --driver-memory | Driver内存,默认 1G |
| --driver-java-options | 传给 driver 的额外的 Java 选项 |
| --driver-library-path | 传给 driver 的额外的库路径 |
| --driver-class-path | 传给 driver 的额外的类路径 |
| --driver-cores | Driver 的核数,默认是1。在 yarn 或者 standalone 下使用 |
| --executor-memory | 每个 executor 的内存,默认是1G |
| --total-executor-cores | 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用 |
| --num-executors | 启动的 executor 数量。默认为2。在 yarn 下使用 |
| --executor-core | 每个 executor 的核数。在yarn或者standalone下使用 |
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1G \
--num-executors 3 \
--executor-memory 1G \
--executor-cores 1 \
/opt/bigdata/hadoop/server/spark-3.2.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.0.jar 100
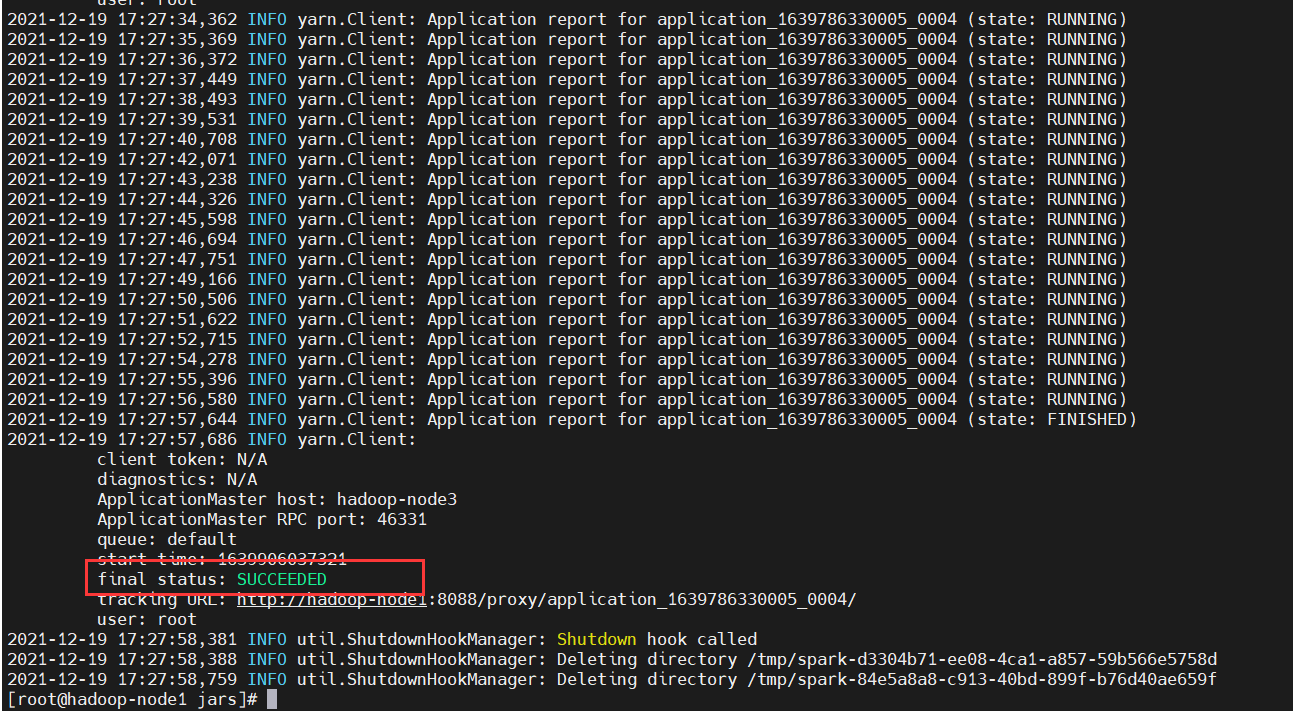
如果看到控制台出现这个,说明运行成功。
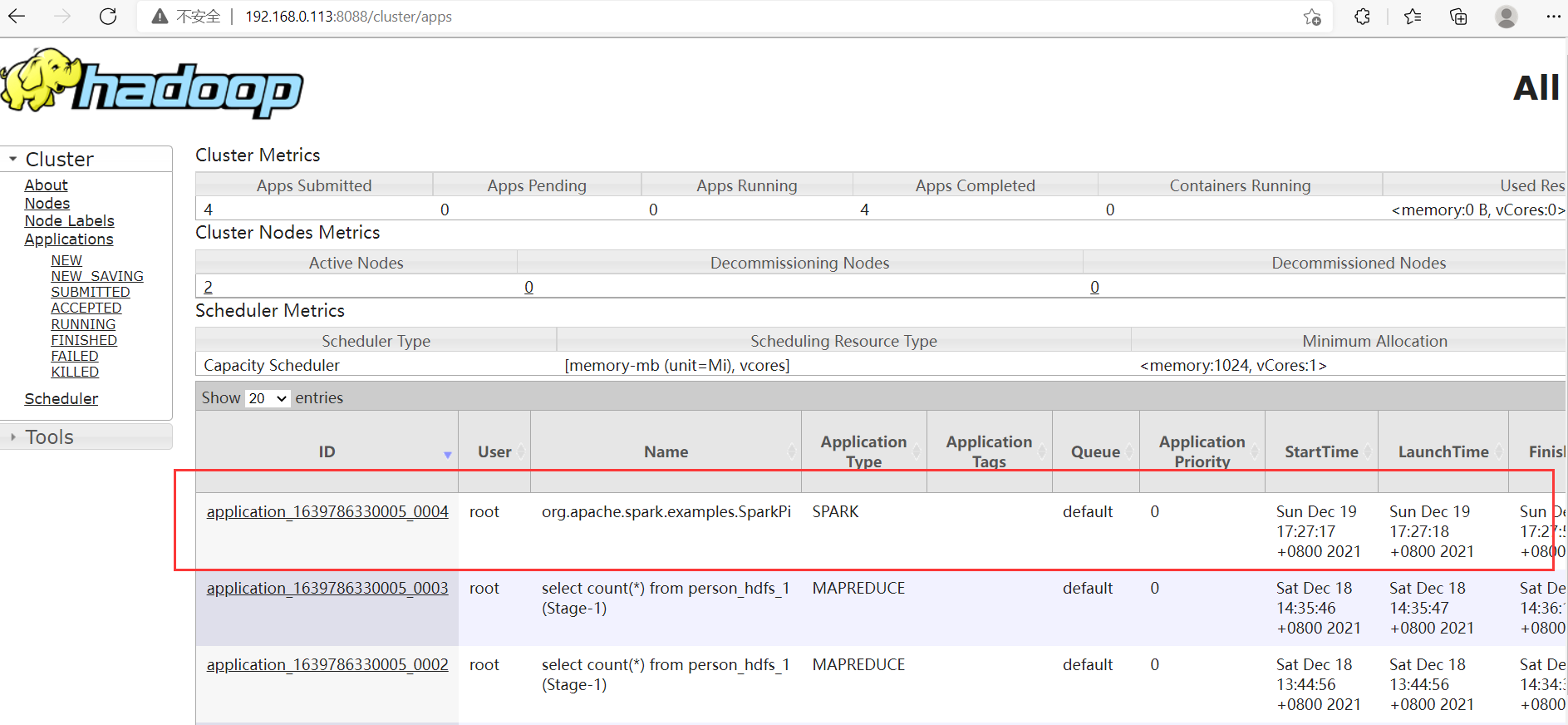
查看yarn任务
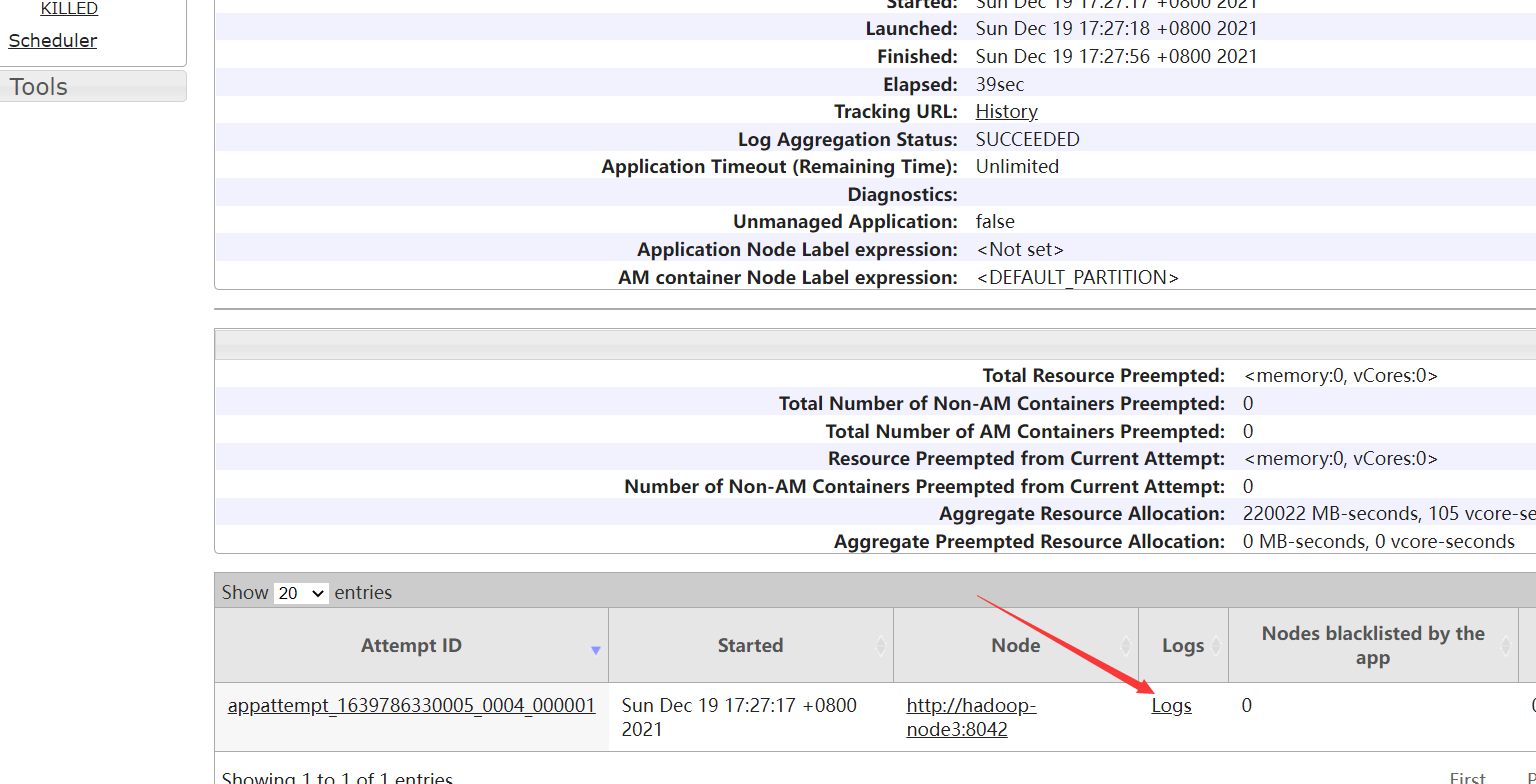
查看任务日志
【注意】默认情况下,Hadoop历史服务historyserver是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器。查看日志依赖于historyserver服务
#启动JobHistoryServer服务
$ mapred --daemon start historyserver
#查看进程
$ jps
#停止JobHistoryServer服务
$ mapred --daemon stop historyserver

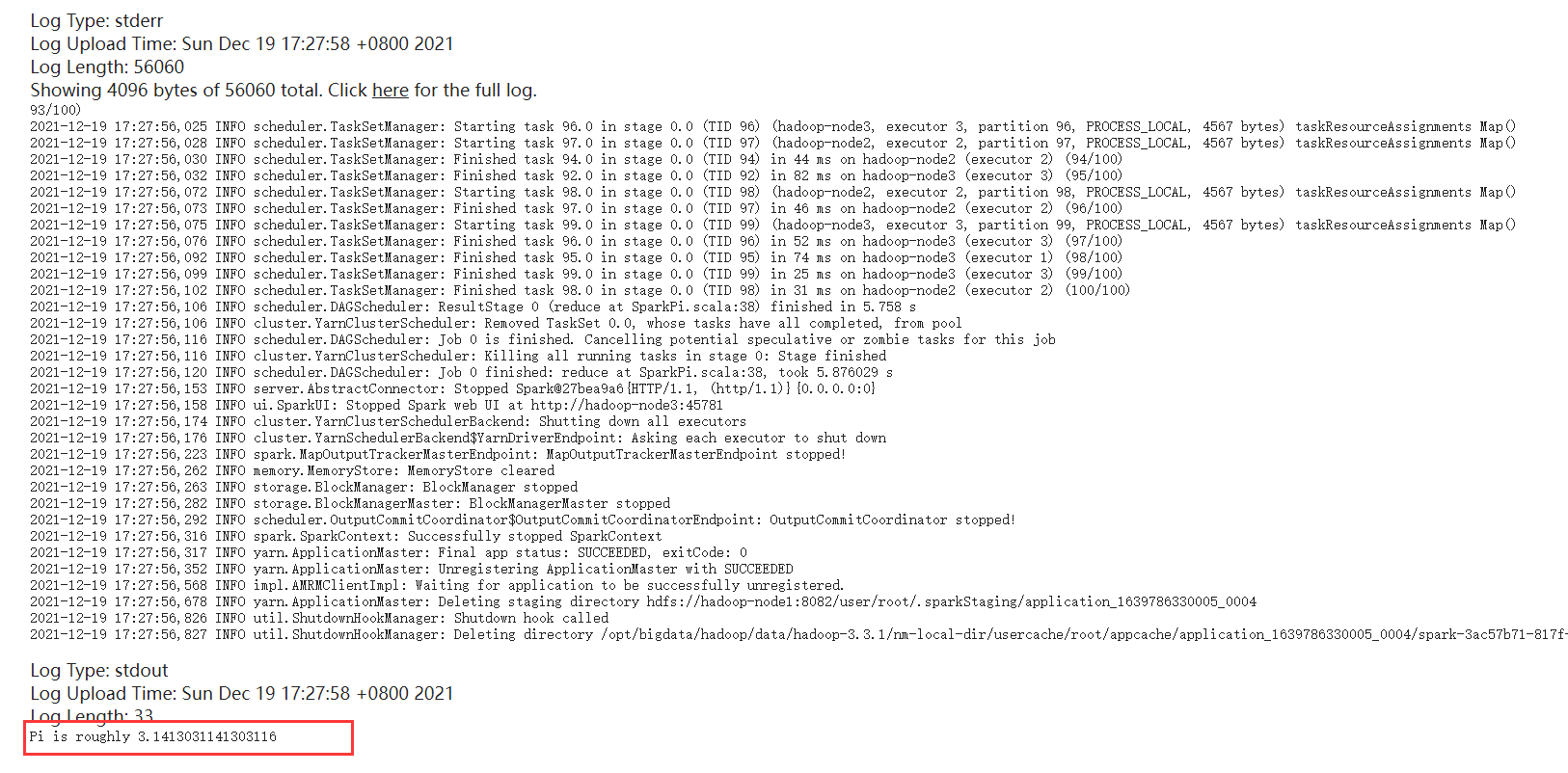
至此已经完成的Spark on Yarn 的环境搭建,并通过测试SparkPi的运行成功了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号