DW吃瓜课程——机器学习理论知识笔记(三)
本篇是针对经典教材《机器学习》及DataWhale小组出版的配套工具书《机器学习公式详解》的学习笔记,主要以查缺补漏为主,因此对于一些自己已经熟悉的概念和内容不再进行整理。由于水平实在有限,不免产生谬误,欢迎读者多多批评指正。
第四章 决策树
基本概念
决策树一般包含根结点、内部结点和叶结点,其中前两者对应于某个属性/特征测试,而叶结点则对应决策结果(类别)。样本集自根结点输入后,会根据当前每个结点的属性预测结果分配到相应的子节点中。
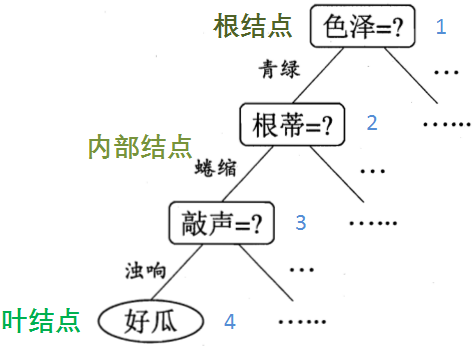
构建树的思路
决策树模型训练的本质就是选择合适的划分属性并以最优的方式将代表属性测试的结点组成一个树结构,训练的目标是得到一棵对未知样本划分效果好的决策树。

决策树利用递归的方法完成构建,其基本流程如上图所示。当满足图中的三种情况时,我们将当前结点标为叶结点,并使递归返回,其中第一类情况意味着利用当前的属性划分已得到了一种单一类别的样本,则此叶结点标记为当前样本的类型(注意叶结点代表一种类型,而其他结点代表的是划分属性);第二类情况说明剩下的属性已对区分当前样本没有效果,因此叶结点的类别直接选为其所含样本中占比最多的类别;第三类情况说明当前的属性组合下没有对应的样本,此时将叶结点类别设定为其父结点所含样本最多的类别。当这些情况都没有出现时,当前节点就不是叶结点,我们会根据划分原则选择当前的最优划分属性,并对其属性的每个取值分支(也就是一个子树)再次调用判断函数(递归推进),直至所有结点都判断完毕。
划分属性的选择
(未完待续)
参考资料:
- 《机器学习》 周志华 著
- 《机器学习公式详解》 谢文睿 秦州 著
- https://www.bilibili.com/video/BV1Mh411e7VU?p=1 《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集

 浙公网安备 33010602011771号
浙公网安备 33010602011771号