
nlp入门系列笔记——阿里天池新闻文本新手赛
本系列是针对于DataWhale学习小组的笔记,从一个对统计学和机器学习理论基础薄弱的初学者角度出发,在小组学习资料的基础上,由浅入深地对知识进行总结和整理,今后有了新的理解可能还会不断完善。由于水平实在有限,不免产生谬误,欢迎读者多多批评指正。如需要转载请与博主联系,谢谢
比赛核心思路
赛题内容解读
-
训练集的样本格式为一列文本加一列标签,其中文本内容以字符为单位进行了匿名处理,因此看到的是一串被空格分隔的数字字符串。标签一列是单独的一组数字用于标识文本类型,其对应关系如下:'科技': 0, '股票': 1, '体育': 2, '娱乐': 3, '时政': 4, '社会': 5, '教育': 6, '财经': 7, '家居': 8, '游戏': 9, '房产': 10, '时尚': 11, '彩票': 12, '星座': 13。训练集样本整体结构如下图所示,由于内容太多,只显示部分行和列。

ps:第一列为dataframe读取后的索引,请忽略。 -
比赛不限制使用任何外部数据和模型。
-
评测标准为类别f1_score的均值,选手提交结果与实际测试集的类别进行对比,结果越大越好。计算公式如下:
ps:这里的f1_score值是precision和recall调和平均值,precision和recall被称为准确率(查准率)和召回率(查全率)。与二分类问题一样,在多分类问题中,将样本根据其真实类别与学习器所预测类别的组合划分为真正例(true positive,TP)、假正例(false positive,FP)、真反例(true negative,TN)、假反例(false negative,FN)四种情形,表示如下:
| 真实类别1 | 真实类别2 | 真实类别3 | …… | |
|---|---|---|---|---|
| 预测类别1 | 30 | 20 | 10 | |
| 预测类别2 | 50 | 60 | 10 | |
| 预测类别3 | 20 | 20 | 80 | |
| 此时以类别2为例: | ||||
| 类别2-TP:标签为类别2, 预测为类别2 = 60 | ||||
| 类别2-FN: 标签为类别2, 预测不是类别2 = 20+20 = 40 | ||||
| 类别2-FP: 标签不为类别2, 预测为类别2 = 50 + 10 = 60 | ||||
| 类别2-TN: 标签不为类别2, 预测也不是类别2 = 30+10+20+80 = 140 | ||||
| 类别2-precision = TP/(TP+FP) = 0.5 | ||||
| 类别2-recall = TP/(TP+FN) = 0.6 | ||||
| 也可以直接利用sklearn模块进行计算: |
from sklearn.metrics import f1_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
f1_score(y_true, y_pred, average='macro')
- 提交预测结果的格式需要与sample_submit.csv中的格式一致。
官方比赛思路
- TF-IDF + 机器学习分类器
TF(Term Frequency,词频)表示一个给定词语\(t_i\)在一篇给定文档\(d_j\)中出现的频率。此值越高则认为该词汇对本文越重要(越有代表性)。如下式所示:
IDF(Inverse Document Frequency,逆向文件频率)表示一个给定词语t在数据集任意一篇文档中出现的可能性大小。此值越高则认为该词汇越罕见(只在特定类型文章中出现),因此区分能力越强。
二者的乘积即为TF-IDF值,该值可用于评估某字词对于某一个或一类文档的的重要程度。
用TF-IDF提取特征后,可以利用机器学习模型做分类,常用的方法有LR、SVM或XGBoost等。
-
FastText
-
WordVec + 深度学习分类器
-
Bert词向量
数据特征分析
- 读取数据集文件
import pandas as pd
from matplotlib import pyplot as plt
from collections import Counter
train_df = pd.read_csv('D:\\人工智能资料\\数据比赛\\天池新闻文本\\train_set\\train_set.csv', sep='\t', nrows=100) #文件路径根据实际写;sep是列分隔依据,在这里就是制表符'\t';先取前100行nrows=100,全读取可去掉
train_df.head() #读取DataFrame类型数据的前五行,注意左侧第一列为索引

- 句子长度分析
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
# 创造新特征列text_len,方法是利用lambda函数计算text列中每行元素的数组长度,数组由元素字符串按空格切分获得
print(train_df['text_len'].describe())
# 获得text_len列的统计变量

可以看到大部分句子长度都在2000以内,为了更直观地观察句子长度分布,我们可以做成统计图:
_ = plt.hist(train_df['text_len'], bins=200) #这里需要matplotlib.pyplot模块
plt.xlabel('Text char count')
plt.title("Histogram of char count")
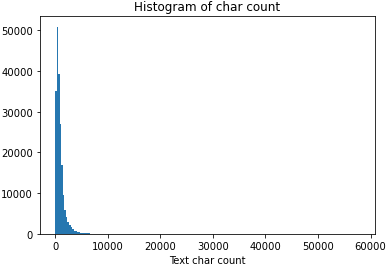
- 新闻类别分布
接下来可以看一下数据集中样本的标签类型分布:
train_df['label'].value_counts().plot(kind='bar') # .value_counts()返回一个Series数组,显示原数组中每类值出现的次数
plt.title('News class count')
plt.xlabel("category")
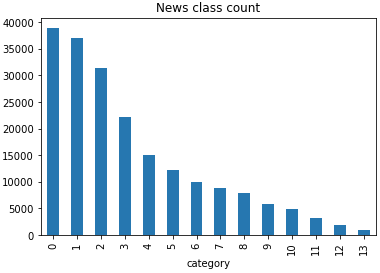
可以从中看出类别的高低分布就是按照序号顺序排列的~最多的文本类型是科技类。
紧接着来看文本内容中出现的字符的分布特征,尽管加密后我们不能得到字符本身的含义,但还是可以获得字符总数及分布的特点:
all_lines = ' '.join(list(train_df['text'])) # 读取所有文本内容,以空格连接各文本生成一个长字符串
word_count = Counter(all_lines.split(" ")) # 按空格切分字符并存入Counter
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print(len(word_count))
print(word_count[0])
print(word_count[-1])
'''
Printout:
6869
('3750', 7482224)
('3133', 1)
'''
此外还可以根据字符在不同文本中出现的频率,推断其是否可能为标点符号,如'3750'、'900'及'648'等在几乎所有文本中出现,很可能是标点符号。
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True) # reverse = True 即降序排列
print(word_count[0])
print(word_count[1])
print(word_count[2])
'''
Printout:
('3750', 197997)
('900', 197653)
('648', 191975)
'''
word_keys = [word_count[i][0] for i in range(len(word_count[:10]))]
word_nums = [word_count[i][1] for i in range(len(word_count[:10]))]
plt.bar(word_keys,word_nums)
plt.title('Top 10 Text char')
plt.xlabel("char No.")
plt.ylabel('counts')
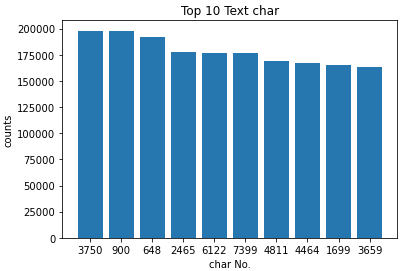
从图中可以看到,出现频率前10的字符均在至少150000个文本中出现,说明这些字符即使不是标点符号,也很可能是无区分度的常用连接词等,我们一般将其称为停用词,而不对其进行分析。
基于机器学习的解决方案
文本表示方法
在运用机器学习或深度学习模型处理自然语言文本时,面临的第一个问题就是如何将复杂而不规则的词句以模型能够接受的规则化的向量形式输入进去。词向量在某种意义上可以被理解为词汇的特征向量,把词汇映射为向量的技术被称为文本表示,或者叫做词嵌入。利用不同的方式对原始文本进行转换可能在复杂度和效果上都有区别。通常来讲,文本表示方法可以分为离散式表示(One-Hot、Bag Of Word、TF-IDF等)和分布式表示(N-gram、Word2Vec等)两类。
- 最简单的One-Hot编码又被称为“独热编码”或“哑编码”。它相当于用一个很长的向量给语料库中所有词汇做了一个索引,然后任何一个词都可以表示成这样一个向量,其在对应自己所处的索引位置为1,其他位置为0(可以想象应该是一个非常稀疏的向量)。
class OneHotEncoder(object):
def __init__(self, corpus=[]):
'''
有时为了提高之后向量读取时的速度,也会根据词频高低对词汇索引进行排序(这里忽略)
代码参考https://cloud.tencent.com/developer/article/1529481
'''
words = []
for sentence in corpus:
for item in sentence.split():
if item not in words:
words.append(item)
self.dicts = set(words)
# 创建词和索引的映射
self.wd2idx = {}
self.idx2wd = {}
for index, word in enumerate(words):
self.wd2idx[word] = index
self.idx2wd[index + 1] = word
'''
例如输入corpus=[''我爱北京天安门'',''天安门上太阳升'']
则字符与索引间映射为{''我'':1,''爱'':2,''北'':3,''京'':4,''天'':5,''安'':6,''门'':7,''上'':8,''太'':9,''阳'':10,''升'':11}
则''我''和''门''字的One-Hot编码分别为:
[1,0,0,0,0,0,0,0,0,0,0]
[0,0,0,0,0,0,1,0,0,0,0]
'''
- Bag of Words(Count Vectors)又被称为词袋模型。理解这种编码方式的核心在于明白它其实是在对文本进行编码,而不是对某个字或词进行编码。每个文本经过编码后会获得一个长度相当于语料库中所有词汇总数的向量,该向量中每一个元素代表了该元素索引所指向的词汇在整个文本中出现的次数。要注意这种编码方法未必可以很好地表示词汇在文本中的重要性,因为除了关键词外,一些停用词也可能高频出现。
此模型可直接利用sklearn模块中的CountVectorizer方法来实现:
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
vectorizer.fit_transform(corpus).toarray()
- N-gram作为一种判别式模型,其基本假设就是一个词出现的概率仅与在它之前出现的n个词有关(马尔可夫假设)。一般我们只令n=2或3,即一个词出现受其前一个或两个词影响。如下式所示,n=2时:
其具体编码方式与词袋模型类似,只不过会将相邻的n个词组成新的词组存入语料库中,并在编码向量中计数。(这一部分理解的还不太透彻,需要再学习讨论一下)
'''
编码索引如
{''我'':1,''爱'':2,''北'':3,''京'':4,''天'':5,''安'':6,''门'':7,''我爱'':8,''爱北'':9,''北京'':10,''京天'':11,''天安'':12,''安门'':13}
'''
- TF-IDF又称词频-逆文档频率,它解决了词袋模型无法区分常用词和专有名词对文本重要性之间存在差别的问题。任一词汇TF-IDF值具体的计算方法在前面比赛思路部分已经写过了,即:
应用机器学习算法
我们利用上述各类编码方法对文本进行处理,然后代入机器学习模型进行分类,同时从数据中划分出一部分作为验证集对训练好的模型进行评价。
- Count Vectors(词袋模型) + RidgeClassifier(岭回归)
岭回归即在普通线性回归模型经验风险(损失函数)的基础上加入一个L2正则项,在使其最小化的过程中对模型参数进行约束,避免过拟合。该模型主要针对自变量之间存在多重共线性或者自变量个数多于样本量的情况。
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import f1_score
train_df = pd.read_csv('D:\\人工智能资料\\数据比赛\\天池新闻文本\\train_set\\train_set.csv', sep='\t',nrows=15000) #仅读取15000个样本
vectorizer = CountVectorizer(max_features=3000)
train_test = vectorizer.fit_transform(train_df['text']) # 统计每个词出现的次数,将文本转换为词频矩阵
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000]) # 划分前10000个点为训练集,后5000个为验证集
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
'''
Printout:
0.7409790153992153
'''
- TF-IDF(词频-逆文档频率)+ RandomForestClassifier(随机森林)
随机森林本质上是许多以不同方式过拟合的决策树的集合,该模型作为Bagging算法的一种,通过对这些决策树集合的结果取平均值来降低过拟合,以获得更优的预测效果。
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score
train_df = pd.read_csv('D:\\人工智能资料\\数据比赛\\天池新闻文本\\train_set\\train_set.csv', sep='\t',nrows=15000)
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=3000) # 计算TF-IDF时会考虑n=1,n=2,n=3时的n-gram值
train_test = tfidf.fit_transform(train_df['text'])
clf = RandomForestClassifier(n_estimators=25) # n_estimators为决策树的数目,越大模型越精确,但时间和空间成本响应提升
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
# 此处average参数为'macro'代表分布计算每个类别的F1,然后做平均;'micro'代表通过先计算总体的TP,FN和FP的数量,再计算F1
'''
Printout:
0.7493231199101001
这里如果TF-IDF模型参数设置为ngram_range=(1,2), max_features=3000,则f1=0.7579166097185955;若设置为ngram_range=(1,3), max_features=4000,则f1=0.7612799211535053
若直接将模型换为TF-IDF和RidgeClassifier则可将分数提升至0.87以上
'''
基于深度学习的解决方案
深度学习与传统机器学习不同,它往往直接依靠复杂的神经网络进行拟合,而不需要进行分阶段的数据处理或特征工程,因此可以提供端到端地解决方案。深度学习方法在面对规模庞大数据集时的表现更佳,因此今年来成为备受研究者热捧的研究方向。
深度学习中的文本表示方法
上一章中介绍了几种机器学习常用的文本表示方法,即One-Hot编码、词袋模型、N-gram和TF-IDF。这些方法都从不同角度实现了对词汇或文本的编码,但也存在一些问题,比如转换后得到的向量维度很高,且没有考虑词汇之间的关系等。与之相比,深度学习的文本表示方法往往可以将输入映射到低维空间,常用的方法有FastText、Word2Vec和Bert等。
- FastText
FastText是一种高效的文本分类算法,它的基本框架与Word2Vec相似,都包含输入层、隐藏层和输出层。它的输入是编码后的文本词汇及从字符层面上进行组合的N-gram向量,将这些向量叠加后对各元素取均值则得到表示该文本的向量。然后FastText算法将利用分层softmax实现对文本的多分类。
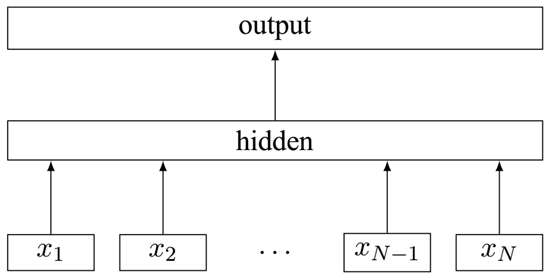
利用keras实现的简单FastText算法:
# -*- coding: utf-8 -*-
from keras.models import Sequential
from keras.layers import Embedding
from keras.layers import GlobalAveragePooling1D
from keras.layers import Dense
VOCAB_SIZE = 2000
EMBEDDING_DIM = 100
MAX_WORDS = 500
CLASS_NUM = 5
def build_fastText():
model = Sequential()
model.add(Embedding(VOCAB_SIZE, EMBEDDING_DIM, input_length=MAX_WORDS))
model.add(GlobalAveragePooling1D())
model.add(Dense(CLASS_NUM, activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='SGD',metrics=['accuracy'])
return model
if __name__ == '__main__':
model = build_fastText()
print(model.summary())
更简便的方法是直接利用开源的fasttext模块进行文本分类:
import pandas as pd
from sklearn.metrics import f1_score
# 转换为Fast Text需要的格式
train_df = pd.read_csv('D:\\人工智能资料\\数据比赛\\天池新闻文本\\train_set\\train_set.csv', sep='\t', nrows=15000)
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text','label_ft']].iloc[:-5000].to_csv('train.csv', index=None, header=None, sep='\t')
import fasttext
model = fasttext.train_supervised('train.csv', lr=1.0, word Ngrams=2,
verbose=2, min Count=1, epoch=25, loss="hs")
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[-5000:]['text']]
print(f1_score(train_df['label'].values[-5000:].astype(str), val_pred, average='macro'))
'''
Printout:
0.82
'''
注意在TF-IDF和FastText模型中有一些参数需要我们确定,参数的不同可能对模型最终效果有较大的影响。首先我们应当熟悉模型的原理,了解各个参数的含义,在此基础上确定参数的大致范围。如果希望进一步优化参数值,则需要利用验证集对模型的效果进行评价,然后反推参数的最优取值。十折交叉验证就是一种常用的方法:将数据集分成十份,轮流将其中9份做训练1份做验证,10次的结果的均值作为对算法精度的估计。(以下代码借鉴自参考资料7)
import pandas as pd
def cross_10folds(data,folds,jiange,start_index,end_index):
df_test=data[start_index*jiange:end_index*jiange]
df_test_index=list(df_test.index)
df_test_flag=data.index.isin(df_test_index) #都转换为list来判定成员资格
diff_flag = [not f for f in df_test_flag] # 不是df_test_flag里面的索引的索引记为df_train_index的索引集合
df_train= data[diff_flag]
return df_train,df_test
columns1=['label','text']
data=pd.read_csv('D:\\人工智能资料\\数据比赛\\天池新闻文本\\train_set\\train_set.csv', sep='\t', nrows=15000)
data.columns=columns1
folds=10
jiange=int(data.shape[0]/folds)
#10次10折交叉验证的代码
for i in range(1,11):
data=data.sample(frac = 1) #随机打乱样本
for i in range(1,folds+1):
df_train,df_test=cross_10folds(data,folds,jiange,i-1,i)
df_train.to_csv('..\\train_'+str(i)+'.csv',index=True,header=True)
df_test.to_csv('..\\test_'+str(i)+'.csv',index=True,header=True)
- word2vec
word2vec是词向量转换中最常用的方法之一,它的主要优势在于能将不同词汇表示为定长的向量并且很好地表达词汇间存在的相似和关联关系。word2vec方法可以分为两种模型,即跳字模型(skip-gram,SG)和连续词袋模型(continuous bag of words,CBOW)。
Skip-gram模型的基本原理是给定某个input word然后预测其上下文中出现的词汇。这里我们先设定一个参数skip_window来确定词汇临近的上下文中有几个词被考虑到,如skip_window=1则表示当前词汇前后各一个词为模型生成对象。在这里我们假设各背景词间相互独立,则在中心词input word出现时,几个背景词同时出现的概率等于他们分别出现的条件概率的乘积。
在此模型中每个词会被表示为两个n维向量,分别为该词汇作为中心词和背景词时的向量\(v_i\in R^d\)和\(u_i\in R^d\),但在自然语言处理应用中我们一般只选择skip-gram模型的中心词向量作为表征向量使用。设中心词在one-hot编码的语料库中索引为c,而其临近的某个背景词在语料库中索引为o,则给定中心词生成该背景词的条件概率可以通过对向量内积做softmax运算得到:
模型建立起来之后,利用样本文档计算获得的背景词条件概率就可以对模型的准确性进行验证,此时我们可以通过极大似然估计的方法来学习模型参数,也就是我们需要的两个词向量\(v_i\in R^d\)和\(u_i\in R^d\)。设长度为T的文本序列中某个中心词出现的顺序为t,背景窗口大小为m,则skip-gram模型的似然函数为给定任一中心词生成所有背景词的概率:
极大似然估计中需要最小化的损失函数为:
将我们的条件概率模型代入上式后求出梯度,可以发现梯度值与中心词向量和背景词向量有关,因此可利用已有的文本使用随机梯度下降等方法对模型进行训练,从而对语料库中的所有词汇获得我们需要编码的词向量。下图为skip-gram训练所用的网络结构:
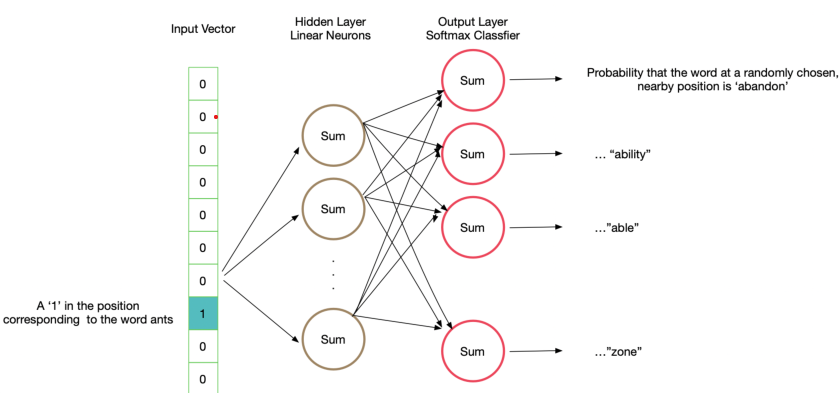
CBOW模型与skip-gram模型类似,它的思路是基于文本中某位置前后的背景词来生成该位置上的中心词,因此其条件概率变为:
其推导过程不再赘述。与skip-gram不同的是,虽然CBOW模型也会生成两个向量,但我们一般只用其背景词向量作为实际应用中词汇的表征向量。
在实际问题处理中我们的语料库中词汇总数往往很大,因此需要构建一个庞大的神经网络,在利用softmax计算条件概率时复杂度会很高。为了解决这一问题,通常采用的办法有以下几种:
- 将常见的单词组合或词组当作单个"word"处理。
- 利用二次采样丢弃一些词汇来减少训练样本的个数。
我们会假设在一个背景窗口中,相比于与较高频的背景词同时出现,一个中心词与较低频的背景词同时出现会对训练词嵌入模型更有益。因此二次采样中数据集里的每个被索引词w_i都有一定概率被丢弃,其概率可写作:
其中\(f(w_i)\)是该词汇出现个数与总词数之比,t为阈值,当\(f(w_i)\)比t大时词汇有可能被丢弃,且越高频的词被丢弃的机会越大。
- 负采样"negative sampling"通过缩小训练单个样本所更新的权重数量来降低计算复杂度。当我们训练神经网络时,每个样本会对应一个输入(中心词)和输出(背景词),这相当于输出神经元中只有一个输出为1,其余未出现的词汇输出均为0。这些未出现的词汇被称为"negative words"。在负采样时,我们仅选择小部分"negative words"与中心词一起进行权重更新(论文作者指出对于小数据集5-20个negative words或大数据集2-5个negative words即可),出现频次越高的单词越容易被选为negative words,出现频次为\(P(w_i)\)的词汇\(w_i\)被选中的概率为:
- 分层softmax(Hierarchical Softmax)是另一种近似训练方法,它利用霍夫曼树的根节点到叶节点的路径来构造损失函数,可将训练中每一步的梯度计算复杂度降低到语料库大小的对数级别。(关于后两种方法以后有时间再充推导充实一下)
利用gensim模块实现word2vec:
from gensim.models.word2vec import Word2Vec
model = Word2Vec(sentences, workers=num_workers, size=num_features)
神经网络建模方法
- TextCNN
TextCNN是一种利用卷积神经网络处理文本分类问题的方法。它将文本视为一维的图像,利用计算机视觉中常用的卷积网络进行处理,如下图所示:
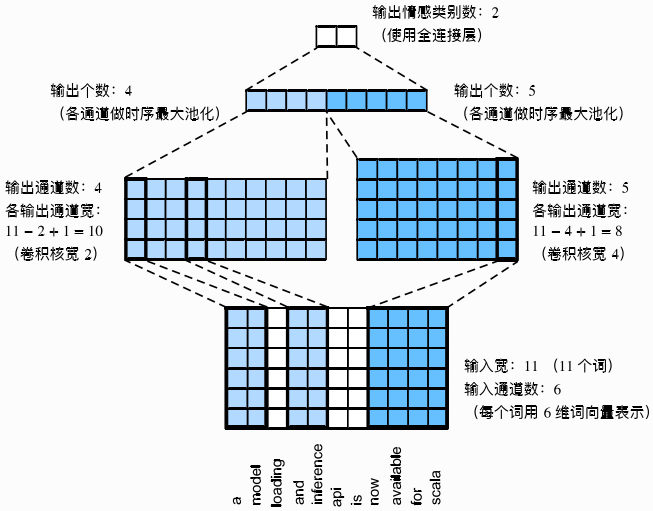
其主要操作步骤如下:
- 利用多个一维卷积核分别对文本进行一维的互相关运算,从中抽取文本的特征及词汇间的相关性。
- 对输出的所有通道分别做时序最大池化(各通道的输出为该通道所有时间步中最大的数值)。
- 通过全连接层将连接后的向量转化为类别标签的输出。
# 模型搭建
self.filter_sizes = [2, 3, 4] # n-gram window
self.out_channel = 100
self.convs = nn.Module List([nn.Conv2d(1, self.out_channel, (filter_size, input_size), bias=True)
for filter_size in self.filter_sizes])
# 前向传播
pooled_outputs = []
for i in range(len(self.filter_sizes)):
filter_height = sent_len - self.filter_sizes[i] + 1
conv = self.convs[i](batch_embed)
hidden = F.relu(conv) # sen_num x out_channel x filter_height x 1
mp = nn.Max Pool2d((filter_height, 1)) # (filter_height, filter_width)
# sen_num x out_channel x 1 x 1 -> sen_num x out_channel
pooled = mp(hidden).reshape(sen_num, self.out_channel)
pooled_outputs.append(pooled)
- TextRNN
RNN模型适合于处理各类序列问题,TextRNN即利用RNN中常用的LSTM模型对文本进行编码处理。具体的步骤是,每个词首先通过嵌入层得到特征向量,然后利用LSTM作为隐藏层对特征序列进行编码,将长短期记忆在最初时间步和最终时间步的隐藏状态相连结作为文本特征的表征,最后将这些编码后的序列输入全连接层进行输出分类。
# 模型搭建
input_size = config.word_dims
self.word_lstm = LSTM(
input_size=input_size,
hidden_size=config.word_hidden_size,
num_layers=config.word_num_layers,
batch_first=True,
bidirectional=True,
dropout_in=config.dropout_input,
dropout_out=config.dropout_hidden,
)
# 前向传播
hiddens, _ = self.word_lstm(batch_embed, batch_masks) # sent_len x sen_num x hidden*2
hiddens.transpose_(1, 0) # sen_num x sent_len x hidden*2
if self.training:
hiddens = drop_sequence_sharedmask(hiddens, self.dropout_mlp)
其他建模方法
- Transformer模型
Transformer模型由Ashish Vasani等人在其论文《Attention Is All You Need》中提出,其模型的架构没有使用传统的网络结构,而是依赖于多头注意力机制(Multi-Head Attension)的结构。整个模型可看作由多个编码器和相同数量的解码器两部分组成
如下图所示:
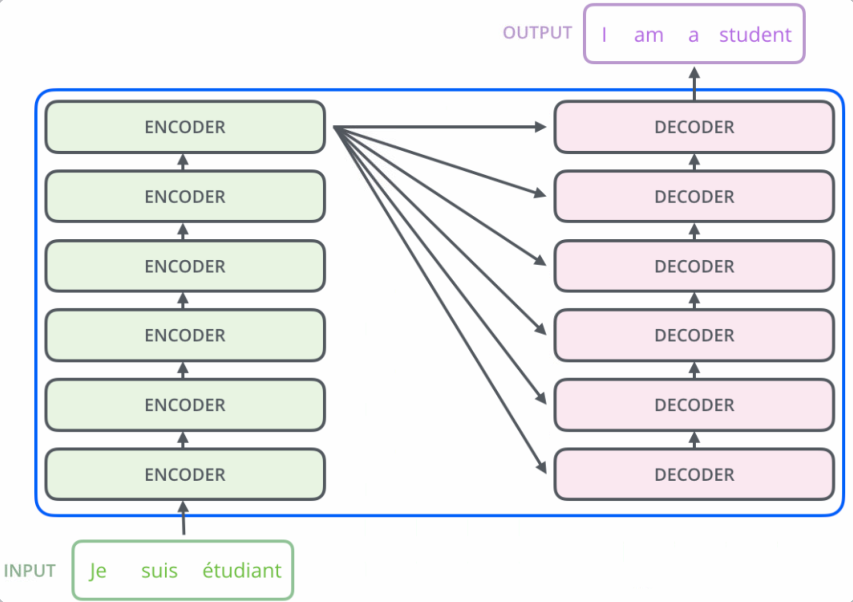
其中每个编码器的结构相同,但参数不共享。编码器的内部由两部分组成,输入的词向量首先到达自注意力(self-attention)层,它有助于为某词汇编码时注意到句子中的其他词汇,之后自注意力层的输出进入一个前馈神经网络,最终输出到下一个编码器。同样,解码器中也包含了自注意力层和前馈网络层。除此之外,这两个层之间还有一个注意力层,用来关注输入句子的相关部分。
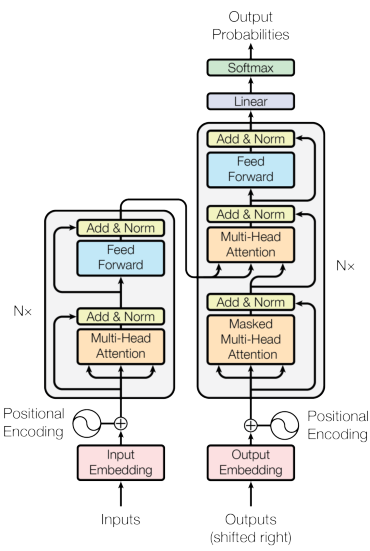
- Bert模型
在自然语言处理领域中,基于预训练的语言模型在多种任务下均有非常出色的表现。近年来最为火热的BERT模型即是一种基于预训练的语言模型。我们都知道神经网络等模型通常依赖于误差反向传播算法对模型参数进行优化,而所谓预训练就是指通过预先的训练使得模型在使用时并不完全从随机初始化的参数开始训练,从而提升训练速度并优化训练效果。
BERT模型可以看作一个基于transformer的多层编码器,通过执行一系列预训练,进而得到深层的上下文表示。其与其他两种预训练模型的结构差异如下图所示:
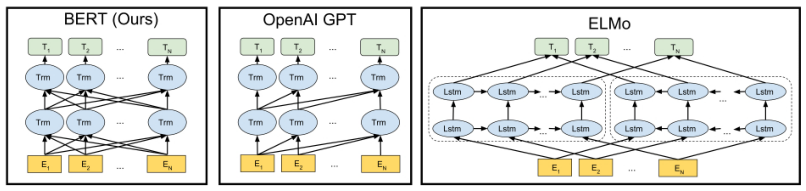
模型结构上,BERT模型对ELMo模型中使用两个单向语言模型拼接的方式进行改进,从而提出了掩码语言模型,使得模型能够自由地编码每个层中来自两个方向的信息。从流程上看,BERT模型则遵循了GPT的预训练-微调两阶段模式。笼统地说,BERT模型就是依靠前期利用已有的海量无标注文本进行一个预训练,使得其网络参数中蕴含了从真实世界文本中提炼出来的词法、句法和语法知识,然后在面对具体问题时,只要对模型进行简单改造即可。
针对本题目的预训练部分(源码来自Datawhale学习小组,这一部分的概念没太搞清楚,对其原理也不太理解,还需要之后继续学习):
class WhitespaceTokenizer(object):
"""WhitespaceTokenizer with vocab."""
def __init__(self, vocab_file):
self.vocab = load_vocab(vocab_file)
self.inv_vocab = {v: k for k, v in self.vocab.items()}
def tokenize(self, text):
split_tokens = whitespace_tokenize(text)
output_tokens = []
for token in split_tokens:
if token in self.vocab:
output_tokens.append(token)
else:
output_tokens.append("[UNK]")
return output_tokens
def convert_tokens_to_ids(self, tokens):
return convert_by_vocab(self.vocab, tokens)
def convert_ids_to_tokens(self, ids):
return convert_by_vocab(self.inv_vocab, ids)
def create_segments_from_document(document, max_segment_length):
"""Split single document to segments according to max_segment_length."""
assert len(document) == 1
document = document[0]
document_len = len(document)
index = list(range(0, document_len, max_segment_length))
other_len = document_len % max_segment_length
if other_len > max_segment_length / 2:
index.append(document_len)
segments = []
for i in range(len(index) - 1):
segment = document[index[i]: index[i+1]]
segments.append(segment)
return segments
(masked_lm_loss, masked_lm_example_loss, masked_lm_log_probs) = get_masked_lm_output(
bert_config, model.get_sequence_output(), model.get_embedding_table(),
masked_lm_positions, masked_lm_ids, masked_lm_weights)
total_loss = masked_lm_loss
{
"hidden_size": 256,
"hidden_act": "gelu",
"initializer_range": 0.02,
"vocab_size": 5981,
"hidden_dropout_prob": 0.1,
"num_attention_heads": 4,
"type_vocab_size": 2,
"max_position_embeddings": 256,
"num_hidden_layers": 4,
"intermediate_size": 1024,
"attention_probs_dropout_prob": 0.1
}
def convert_tf_checkpoint_to_pytorch(tf_checkpoint_path, bert_config_file, pytorch_dump_path):
# Initialise PyTorch model
config = BertConfig.from_json_file(bert_config_file)
print("Building PyTorch model from configuration: {}".format(str(config)))
model = BertForPreTraining(config)
# Load weights from tf checkpoint
load_tf_weights_in_bert(model, config, tf_checkpoint_path)
# Save pytorch-model
print("Save PyTorch model to {}".format(pytorch_dump_path))
torch.save(model.state_dict(), pytorch_dump_path)
微调部分将输出的最后一层的第一个token也就[CLS]的隐藏向量作为句子表示,然后输入到softmax层进行分类。
sequence_output, pooled_output = \
self.bert(input_ids=input_ids, token_type_ids=token_type_ids)
if self.pooled:
reps = pooled_output
else:
reps = sequence_output[:, 0, :] # sen_num x 256
if self.training:
reps = self.dropout(reps)
参考资料:
- https://tianchi.aliyun.com/notebook-ai/detail?spm=5176.12586969.1002.6.6406111aIKCSLV&postId=118252 天池DataWhale小组学习资料
- https://www.cnblogs.com/pprp/p/11241954.html 【深度学习】Precision 和 Recall 评价指标理解
- https://www.zhihu.com/question/19645541?utm_campaign=rss&utm_medium=rss&utm_source=rss&utm_content=title 知乎:如何解释召回率与精确率?
- https://www.jianshu.com/p/0d7b5c226f39 通俗理解TF-IDF
- https://cloud.tencent.com/developer/article/1529481 文本在计算机中的表示方法总结-@Dendi
- https://www.cnblogs.com/techengin/p/8962024.html sklearn中 F1-micro 与 F1-macro区别和计算原理
- https://zhuanlan.zhihu.com/p/32965521 fastText原理及实践
- https://blog.csdn.net/jp_zhou256/article/details/85248578 10折交叉验证深入理解
- 李沐等. 《动手学深度学习》
- https://blog.csdn.net/longxinchen_ml/article/details/86533005 图解Transformer(完整版)
