09反序列化漏洞
反序列化漏洞:使用了编译型语言,为什么还是会被注入?
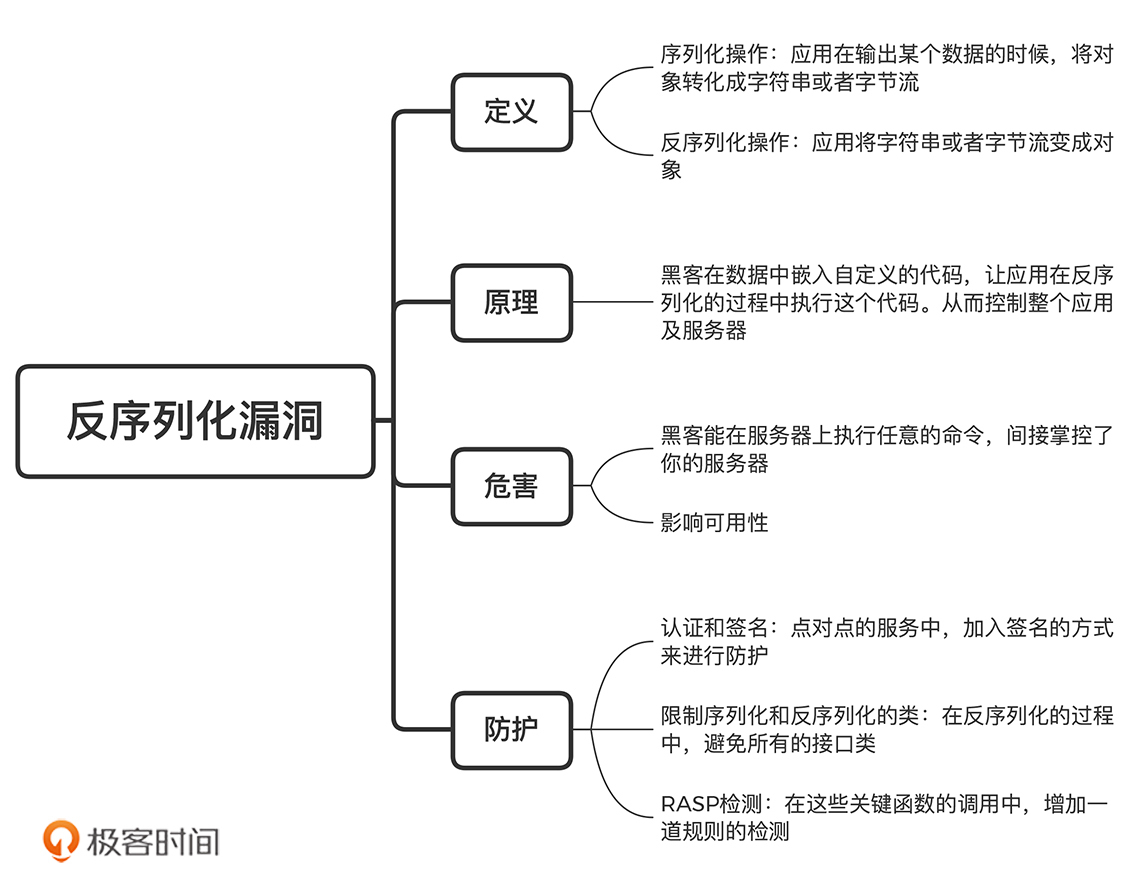
反序列化漏洞是如何产生的?
应用在输出某个数据的时候,将对象转化成字符串或者字节流,这就是序列化操作。
什么是反序列化?
应用将字符串或者字节流变成对象
Java 中的 Serializable 接口(或者 Python 中的 pickle)可以把应用中的对象转化为二进制的字节流,把字节流再还原为对象;还有 XML 和 JSON 这些跨平台的协议,可以把对象转化为带格式的文本,把文本再还原为对象。
在把数据转化成对象的过程中。在这个过程中,应用需要根据数据的内容,去调用特定的方法。而黑客正是利用这个逻辑,在数据中嵌入自定义的代码(比如执行某个系统命令)。应用对数据进行反序列化的时候,会执行这段代码,从而使得黑客能够控制整个应用及服务器。这就是反序列化漏洞攻击的过程。
- 黑客构造一个恶意的调用链(专业术语为 POP,Property Oriented Programming),并将其序列化成数据,然后发送给应用;
- 应用接收数据。大部分应用都有接收外部输入的地方,比如各种 HTTP 接口。而这个输入的数据就有可能是序列化数据;
- 应用进行反序列操作。收到数据后,应用尝试将数据构造成对象;
- 应用在反序列化过程中,会调用黑客构造的调用链,使得应用会执行黑客的任意命令。
反序列化的过程其实就是一个数据到对象的过程。在这个过程中,应用必须根据数据源去调用一些默认方法(比如构造函数和 Getter/Setter)。
黑客可以控制反序列化过程中,应用要调用的接口实现类的默认方法。通过对不同接口类的默认方法进行组合,黑客就可以控制反序列化的调用过程,实现执行任意命令的功能。
黑客可以通过构建一个体积很小的数据,增加应用在反序列化过程中需要调用的方法数,以此来耗尽 CPU 资源,达到影响服务器可用性的目的。
如何进行反序列化漏洞防护 ?
认证、限制类和 RASP 检测。
- 认证和签名
对存储的数据进行签名,以此对调用来源进行身份校验。只要黑客获取不到密钥信息,它就无法向进行反序列化的服务接口发送数据,也就无从发起反序列化攻击了。
- 限制序列化和反序列化的类
在反序列化漏洞中,黑客需要构建调用链,而调用链是基于类的默认方法来构造的。然而,大部分类的默认方法逻辑很少,无法串联成完整调用链。因此,在调用链中通常会涉及非常规的类,比如,刚才那个 demo 中的 InvokerTransformer。我相信 99.99% 的人都不会去序列化这个类。因此,我们可以通过构建黑名单的方式,来检测反序列化过程中调用链的异常。
只要你在反序列化的过程中,避免了所有的接口类(包括类成员中的接口、泛型等),黑客其实就没有办法控制应用反序列化过程中所使用的类,也就没有办法构造出调用链,自然也就无法利用反序列化漏洞了。
- RASP 检测
RASP是最好的检测反序列化攻击的方式
如果使用认证和限制类这样的方式来检测,就需要一个一个去覆盖可能出现的漏洞点,非常耗费时间和精力。而 RASP 则不同,它通过 hook 的方式,直接将整个应用都监控了起来。因此,能够做到覆盖面更广、代码改动更少。
RASP 的检测规则都不高效,因此,它会给应用带来一定的性能损耗,不适合在高并发的场景中使用。但是,在应用不受严格性能约束的情况下,我还是推荐使用 RASP。
总结
对于反序列化漏洞的防御,我们主要考虑两个方面:认证和检测。对于面向内部的接口和服务,我们可以采取认证的方式,杜绝它们被黑客利用的可能。另外,我们也需要对反序列化数据中的调用链进行黑白名单检测。成熟的第三方序列化插件都已经包含了这个功能,暂时可以不需要考虑。最后,如果没有过多的性能考量,我们可以通过 RASP 的方式,来进行一个更全面的检测和防护。