字符编码
储备知识点:
1.计算机系统分为三层:
应用程序
操作系统
计算机硬件
2.运行python程序的三个步骤
1.先启动python解析器
2.再将python文件当作普通的文本文件读入内容
3.解释执行读入内存的代码,开始识别语法
字符编码
1.什么是字符编码
字符编码表:人类的字符<--------->数字
a ------ 00
b ------ 01
c ------ 10
d ------ 11
2**7-1=127==>2^7
1Bytes=8bit(bit)
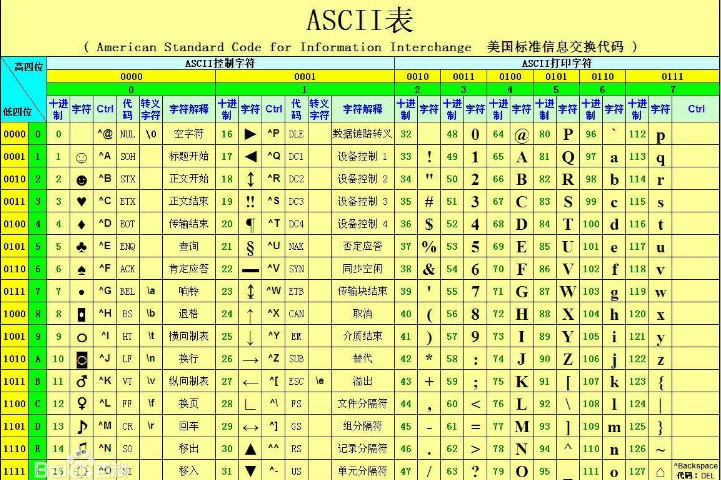
ASCII码:只能识别英文字符,1个英文字符=9bit
用8个二进制bit(比特位)位表示一个英文字符
GBK:能识别汉字与英文,1个汉字=16bit,1个英文字符=8bit
日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里
解决乱码的唯一法则:当初用什么乱码存的就用哪个编码取 存取编码必须一致 不一致肯定会出现乱码问题
内存断电就没了 数据存储在硬盘中
万国码unicode编码 能够识别万国字符 1字符=2Byte=16bit 也有个别的不是两个Byte
UTF-8(可变长,全称Unicode Transformation Format),对英文字符只用1Bytes表示,对中文字符用3Bytes,对其他生僻字用更多的Bytes去存
是Unicode转换之后的结果
2**16-1=65535个字符
Unicode数字可以对应万国的数字列:GBK ASCII Shift-JIS二进制数字
Unicode:能够识别万国字符:1字符=2 Byte=16bit
两大特点:
1.能够兼容万国字符
2.与各个国家的字符编码都有映射关系
往内存中写都是Unicode往硬盘中读是utf-8
utf-8:是Unicode转换格式,一个英文字符=1Bytes
一个汉字=3个Bytes
重点:
1.编码与解码:
字符--------->Unicode的二进制--------->GBK格式的二进制 GBK格式的二进制-----解码->字符
2.解决乱码的核心法则:当初用什么格式编码的就用哪个编码进行解码
3.python解释器默认的字符编码
在前面加#coding:gbk 解决以gbk保存时候出现乱码的格式 在文件首行写:#coding:让python解释器读文件的时候使用
print('hello')
python2用的ASCII码
python3用UTF-8编码
针对python2解释器中定义字符串应该:
x=u'上'#在python2解释器定义变量前加一个u转换为字Unicode编码保存 python3无效
在python3中
x='上' #'上'存成了unicode
unicode--------encode------->gbk
res=x.encode('gbk') #res是gbk格式的二进制称之为bytes类型
gbk(bytes类型)-------decode------->unicode
y=res.decode('gbk') #y就是unicode
关于字符编码的操作:
1. 编写python文件,首行应该加文件头:#coding:文件存时用的编码
2. 用python2写程序,定义字符串应该加前缀u,如x=u'上'
3. python3中的字符串都是unicode编码的,python3的字符串encode之后可以得到bytes类型
2.为何字符要编码
人类与计算机打交道用都是人类的字符,而计算机无法识别人类的字符,只能识别二进制,所以必须将人类的字符编码成计算机能识别的二进制数字
3.如何用字符编码
unicode------编码---------->gbk
x='上'
res=x.encode('gbk')
print(res,type(res))
gbk----------解码---------->unicode
y=res.decode('gbk')
print(y)
字符编码表