
软件工程 wc.exe 代码统计作业分享
1. Github 项目地址
https://github.com/EdwardLiu-Aurora/WordCount
-
基本要求
-
扩展功能
-
高级功能
2. PSP 表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 5 |
| · Estimate | · 估计这个任务需要多少时间 | 600 | 730 |
| Development | 开发 | 480 | 610 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 10 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 120 | 240 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 120 | 120 |
| · Test Report | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 605 | 735 |
3. 解题思路描述
(1) 返回文件的字符数
定义:返回文件中除去的字符总数(中文字符分离出来计算)
思路:使用 Java 按行读取文件,每个行就是一个 String 对象。
使用 String.length() 来统计该行的字符数,并且按照 Character 的值范围判断是否为中文字。使用两个 int 变量来计算总的字符数以及总的中文字符数。
(2) 返回文件的词汇数
定义:不包含中文字符,只包含 0-9,a-z,A-Z 和 _ 的连续字段称为词汇
思路:查看 Java 根据以上规则,编写符合的正则表达式,使用正则表达式进行按行累加单词数。
(3) 返回文件的行数
定义:返回文件中总行数(根据换行符决定)
思路:根据 Java 按行读取文件,设定计数器。
(4) 递归处理目录下符合条件的文件
定义:该目录及子目录下的文件全部分析,附带用户需要的数据
思路:使用一个函数,将该目录下的所有符合条件的文件路径转成一个 ArrayList 对象并且返回到 Main 函数,由 Main 函数继续处理。
(5) 返回更复杂的数据
代码行:除了格式控制符号(如 "{}" "()" ";" 等)之外,包含多余一个字符的代码;
思路:设置一个 Set 里面存储了所有的格式控制字符,如果检测到字符不在 Set 内,则判断为代码行(要注意的跟注释行冲突的情况:
1. 当该行有 // 和 /* 时,观察哪一个在前面
2. 当该行在 /* */ 注释内时,则不属于代码行;
3. 当该行是 /* 注释行第一行或者末尾一行的时候,要注意检测 /* 前 或 */ 后 的字符;
4. 当该行仅包含 // 时,检查 // 前的符号
注释行:包括注释的行号,无论本行是不是代码行;即包含 // 或在 /* */ 范围内的行;
思路:按行读取,按照 // 或者 /* */ 区分情况
空行:全是空格或者格式控制字符的行;
思路:按照 正则表达式 和 String.indexOf() 函数进行匹配处理
(6) 文件通配符
定义:可以按照 * 代表任意 0 ~ 多个 字符以及 ? 代表 1 个任意字符进行匹配
思路:先将 ? 和 * 替换为特定的正则表达式表示,然后将 . 替换为正则表达式表示,然后进行每一个路径中的正则匹配。
4. 设计实现过程
包的说明
- bean:存放将要返回的复合类型
- service: 存放具体业务的函数实现
- com.edwardliu_aurora:Main 函数的具体实现
类的说明
- CharCount:
- allCharCount 所有字符总数
- chnCharCount 所有中字总数
- LineCount:
- blankLineCount 空白行数统计
- codeLineCount 代码行数统计
- commentLineCount 注释行数统计
- BasicStatistic:
- public CharCount getCharCount(String filePath) 返回字数统计
- public long getWordCount(String filePath) 返回词数统计
- public long getLineCount(String filePath) 返回行数统计
- ExtraStatistic:
- public LineCount getDetailLineCount(String filePath) 获取详细的行数信息
- Utils:
- public static Charset charsetRecognize(String filePath) 识别文本的编码类型(仅支持 GBK 和 UTF-8)
- public static ArrayList
getFilesPath(String folderPath,String filePattern) 返回某目录下的所有符合 filePattern 通配符的文件路径
- Main:
- 主要负责输入输出以及以上函数的合理调用
5. 代码说明
- CharCount:
- allCharCount 所有字符总数
- chnCharCount 所有中字总数
package bean;
/*
记录总字符数和中文字符数的类
*/
public class CharCount {
// 全体字符数目
long allCharCount = 0;
// 中文字符数目
long chnCharCount = 0;
public CharCount(long allCharCount, long chnCharCount) {
this.allCharCount = allCharCount;
this.chnCharCount = chnCharCount;
}
public long getAllCharCount() {
return allCharCount;
}
public void setAllCharCount(long allCharCount) {
this.allCharCount = allCharCount;
}
public long getChnCharCount() {
return chnCharCount;
}
public void setChnCharCount(long chnCharCount) {
this.chnCharCount = chnCharCount;
}
}
- LineCount:
- blankLineCount 空白行数统计
- codeLineCount 代码行数统计
- commentLineCount 注释行数统计
package bean;
// 记录详细行数的类
public class LineCount {
// 空行
int blankLineCount = 0;
// 代码行
int codeLineCount = 0;
// 注释行
int commentLineCount = 0;
public LineCount(int blankLineCount, int codeLineCount, int commentLineCount) {
this.blankLineCount = blankLineCount;
this.codeLineCount = codeLineCount;
this.commentLineCount = commentLineCount;
}
public int getBlankLineCount() {
return blankLineCount;
}
public void setBlankLineCount(int blankLineCount) {
this.blankLineCount = blankLineCount;
}
public int getCodeLineCount() {
return codeLineCount;
}
public void setCodeLineCount(int codeLineCount) {
this.codeLineCount = codeLineCount;
}
public int getCommentLineCount() {
return commentLineCount;
}
public void setCommentLineCount(int commentLineCount) {
this.commentLineCount = commentLineCount;
}
}
- BasicStatistic:
- public CharCount getCharCount(String filePath) 返回字数统计
// 返回文件字符数的函数
public CharCount getCharCount(String filePath){
// 全体字符数变量和中文字符数变量
long allCharCount = 0, chnCharCount = 0;
// 新建 nio 文件路径对象
Path path = Paths.get(filePath);
// 为了避免文本太大,这里采用惰性的 Stream<String> 对象
// 注意文件的编码只能为 UTF_8 类型,不然会出现不可知的错误
Stream<String> lines = null;
try {
// 按行读取文件并转化成流
lines = Files.lines(path, Utils.charsetRecognize(filePath));
// 使用 lambda 表达式和 nio 进行归并统计字符数
allCharCount = lines.parallel().reduce(0,
(total, line) -> total + line.length(),
(total1, total2) -> total1 + total2);
lines.close();
// 按行读取文件并转化成流
lines = Files.lines(path, Utils.charsetRecognize(filePath));
// 使用 lambda 表达式和 nio 进行归并统计中文字数
chnCharCount = lines.parallel().reduce(0,
(total, line) ->
{
int res=0;
for(int i=0;i<line.length();i++)
if(line.charAt(i) >= 19968 && line.charAt(i) <= 40869)
res++;
return res + total;
},
(total1, total2) -> total1 + total2
);
lines.close();
}
catch (IOException e){
e.printStackTrace();
System.out.println("文件不存在或无法访问");
if(lines != null) lines.close();
return null;
}
return new CharCount(allCharCount, chnCharCount);
};
- public long getWordCount(String filePath) 返回词数统计
// 返回文件的词汇数
public long getWordCount(String filePath){
long wordCount = 0;
// 为了避免文本太大,这里采用惰性的 Stream<String> 对象
// 注意文件的编码只能为 UTF_8 类型,不然会出现不可知的错误
Stream<String> lines = null;
// 新建 nio 文件路径对象
Path path = Paths.get(filePath);
try {
// 按行读取文件并转化成流
lines = Files.lines(path, Utils.charsetRecognize(filePath));
Pattern pattern = Pattern.compile("\\w+");
// 使用 lambda 表达式和 nio 进行归并统计词汇数
wordCount = lines.parallel().reduce(0,
(total, line) ->
{
int count = 0;
Matcher matcher = pattern.matcher(line);
while(matcher.find()){
count++;
}
return total + count;
},
(total1, total2) -> total1 + total2
);
lines.close();
}
catch (IOException e){
e.printStackTrace();
System.out.println("文件不存在或无法访问");
if(lines != null) lines.close();
return 0;
}
return wordCount;
}
- public long getLineCount(String filePath) 返回行数统计
// 返回文件的行数
public long getLineCount(String filePath){
long lineCount = 0;
// 为了避免文本太大,这里采用惰性的 Stream<String> 对象
// 注意文件的编码只能为 UTF_8 类型,不然会出现不可知的错误
Stream<String> lines = null;
// 新建 nio 文件路径对象
Path path = Paths.get(filePath);
try {
// 按行读取文件并转化成流
lines = Files.lines(path, Utils.charsetRecognize(filePath));
// 使用 lambda 表达式和 nio 进行归并统计行数
lineCount = lines.parallel().reduce(0,
(total, line) -> total + 1,
(total1, total2) -> total1 + total2);
lines.close();
}
catch (IOException e){
e.printStackTrace();
System.out.println("文件不存在或无法访问");
if(lines != null) lines.close();
return 0;
}
return lineCount;
}
- ExtraStatistic:
- public LineCount getDetailLineCount(String filePath) 获取详细的行数信息
package service;
import bean.LineCount;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Stream;
// 高级统计功能
public class ExtraStatistic {
public LineCount getDetailLineCount(String filePath) {
LineCount lineCount = new LineCount(0,0,0);
// 正则表达式匹配任何非空字符
Pattern pattern = Pattern.compile("\\S");
// 统计空行数
Path path = Paths.get(filePath);
try(Stream<String> lines = Files.lines(path, Utils.charsetRecognize(filePath))){
lineCount.setBlankLineCount(
(int) lines.filter(line -> {
if(line.length() == 0) return true;
int i = 0;
Matcher matcher = pattern.matcher(line);
while(matcher.find()){
i++;
// 如果有超过一个非空白字符,则不为空行
if(i > 1) return false;
}
// 其余为空行
return true;
}).count()
);
}
catch(Exception e){
e.printStackTrace();
System.out.println("文件不存在或无法访问");
return null;
}
// 统计注释行和代码行
try(BufferedReader bufferedReader = new BufferedReader(
new InputStreamReader(
new FileInputStream(filePath),
Utils.charsetRecognize(filePath)
))){
int commentLineCount = 0;
int codeLineCount = 0;
// 按行读取文件
for(String line = bufferedReader.readLine(); line != null; line = bufferedReader.readLine())
{
// 单行注释符号位置
int oneLinePos = line.indexOf("//");
// 多行注释符号位置
int mulLinePos = line.indexOf("/*");
// 如果该行有 //,且 // 在前,则将第一次匹配到的 // 后的内容删去,注释行 +1
if(oneLinePos >= 0 && (mulLinePos < 0 || (mulLinePos >= 0 && oneLinePos < mulLinePos))){
line = line.substring(0,oneLinePos);
commentLineCount++;
// 如果有 >1 个非空字符,则同时也为代码行
Matcher matcher = pattern.matcher(line);
int i = 0;
while(matcher.find()) i++;
if(i > 1) codeLineCount++;
}
// 如果该行只有 /* ,则检查是否同时为代码行。注释行 +1,连续读取直到遇到 */ 行
else if(mulLinePos >= 0){
line = line.substring(0, mulLinePos);
commentLineCount++;
// 如果有 >1 个非空字符,则同时也为代码行
Matcher matcher = pattern.matcher(line);
int i = 0;
while(matcher.find()) i++;
if(i > 1) codeLineCount++;
line = bufferedReader.readLine();
while(line.indexOf("*/") < 0) {
commentLineCount++;
line = bufferedReader.readLine();
}
commentLineCount++;
line = line.substring(line.indexOf("*/")+2);
// 如果有超过一个非空字符,则也为代码行
i = 0;
matcher = pattern.matcher(line);
while(matcher.find()) i++;
if(i > 1) codeLineCount++;
}
// 如果没有注释,则看是否能匹配到 >1 个非空字符
else{
int i = 0;
Matcher matcher = pattern.matcher(line);
while(matcher.find()) i++;
if(i > 1) codeLineCount++;
}
}
lineCount.setCodeLineCount(codeLineCount);
lineCount.setCommentLineCount(commentLineCount);
}
catch(Exception e){
e.printStackTrace();
System.out.println("文件不存在或无法访问");
return null;
}
return lineCount;
}
}
- Utils:
- public static Charset charsetRecognize(String filePath) 识别文本的编码类型(仅支持 GBK 和 UTF-8)
// 文件编码类型简单识别
public static Charset charsetRecognize(String filePath){
try{
File file = new File(filePath);
InputStream in = new java.io.FileInputStream(file);
byte[] b = new byte[3];
in.read(b);
in.close();
if (b[0] == -17 && b[1] == -69 && b[2] == -65)
return Charset.forName("UTF-8");
else{
try (Stream<String> lines = Files.lines(Paths.get(filePath), Charset.forName("UTF-8"))){
lines.count();
return Charset.forName("UTF-8");
}
catch(Exception e){
return Charset.forName("GBK");
}
}
}
catch(Exception e){
e.printStackTrace();
return Charset.forName("UTF-8");
}
}
- public static ArrayList<String> getFilesPath(String folderPath,String filePattern) 返回某目录下的所有符合 filePattern 通配符的文件路径
// 获取一个目录下及其子目录下的所有的文件路径
public static ArrayList<String> getFilesPath(String folderPath,String filePattern){
Pattern pattern = Pattern.compile(filePattern);
ArrayList<String> filePaths = new ArrayList<>();
// 获取路径
File file = new File(folderPath);
// 如果这个路径是文件夹
if(file.isDirectory()) {
// 获取路径下的所有文件
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++) {
// 如果路径下的还是文件夹,则递归获取里面的文件和文件夹
if(files[i].isDirectory()) {
filePaths.addAll(getFilesPath(files[i].getPath(),filePattern));
} else {
Matcher matcher = pattern.matcher(files[i].getPath());
if(matcher.find()) filePaths.add(files[i].getPath());
}
}
} else {
Matcher matcher = pattern.matcher(file.getPath());
if(matcher.find()) filePaths.add(file.getPath());
}
return filePaths;
}
- Main:
- 主要负责输入输出以及以上函数的合理调用
package com.edwardliu_aurora;
import bean.CharCount;
import bean.LineCount;
import service.BasicStatistic;
import service.ExtraStatistic;
import service.Utils;
import java.io.File;
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
boolean charCount = false;
boolean wordCount = false;
boolean lineCount = false;
boolean directory = false;
boolean detailLine = false;
for(int i=0;i<args.length-1;i++){
if(args[i].equals("-c")) charCount = true;
else if(args[i].equals("-w")) wordCount = true;
else if(args[i].equals("-l")) lineCount = true;
else if(args[i].equals("-s")) directory = true;
else if(args[i].equals("-a")) detailLine = true;
}
BasicStatistic basicStatistic = new BasicStatistic();
ExtraStatistic extraStatistic = new ExtraStatistic();
if(directory) {
String filePattern = args[args.length-1];
filePattern = filePattern.
replaceAll("\\?","[^/\\\\:*?<>|]").
replaceAll("\\*","[^/\\\\:*?<>|]*").
replaceAll("\\.","\\\\.");
ArrayList<String> filePaths = Utils.getFilesPath(new File("").getAbsolutePath(), filePattern);
for(String filePath:filePaths) {
System.out.println();
System.out.println("文件: " + filePath);
if(charCount) {
CharCount charCountRes = basicStatistic.getCharCount(filePath);
System.out.println("字符数: " + charCountRes.getAllCharCount() + "\t" + "中字数: " + charCountRes.getChnCharCount());
}
if(wordCount) System.out.println("单词数: " + basicStatistic.getWordCount(filePath));
if(lineCount) System.out.println("总行数: " + basicStatistic.getLineCount(filePath));
if(detailLine) {
LineCount lineCountRes = extraStatistic.getDetailLineCount(filePath);
System.out.println("空白行: " + lineCountRes.getBlankLineCount() + "\t" +
"代码行: " + lineCountRes.getCodeLineCount() + "\t" +
"注释行: " + lineCountRes.getCommentLineCount());
}
}
}
else {
String fileName = args[args.length-1];
File file = new File(fileName);
if(!file.exists()){
System.out.println("您要分析的文件不存在,请输入正确的文件名!");
return;
}
System.out.println("文件名: " + fileName);
if(charCount) {
CharCount charCountRes = basicStatistic.getCharCount(file.getAbsolutePath());
System.out.println("字符数: " + charCountRes.getAllCharCount());
System.out.println("中字数: " + charCountRes.getChnCharCount());
}
if(wordCount) System.out.println("单词数: " + basicStatistic.getWordCount(file.getAbsolutePath()));
if(lineCount) System.out.println("总行数: " + basicStatistic.getLineCount(file.getAbsolutePath()));
if(detailLine) {
LineCount lineCountRes = extraStatistic.getDetailLineCount(file.getAbsolutePath());
System.out.println("空白行: " + lineCountRes.getBlankLineCount());
System.out.println("代码行: " + lineCountRes.getCodeLineCount());
System.out.println("注释行: " + lineCountRes.getCommentLineCount());
}
}
}
}
6. 测试运行
单元测试 (已经在开发过程中进行,在这里就不展示了)
测试文件
- 空文件

- 只有一个字符的文件

- 只有一个词的文件
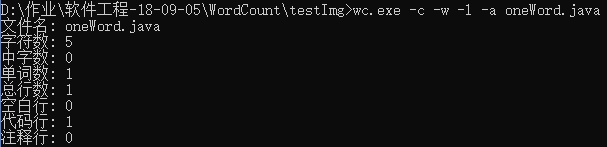
- 只有一行的文件
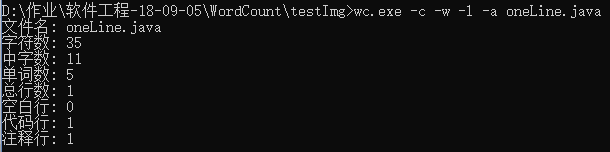
- 一个典型的源文件

基本功能
- 统计特定文件字符数、词汇数、行数
已经在上方图片展示
高级功能
- 统计目录下通配文件基本信息
- 统计目录下通配文件详细信息
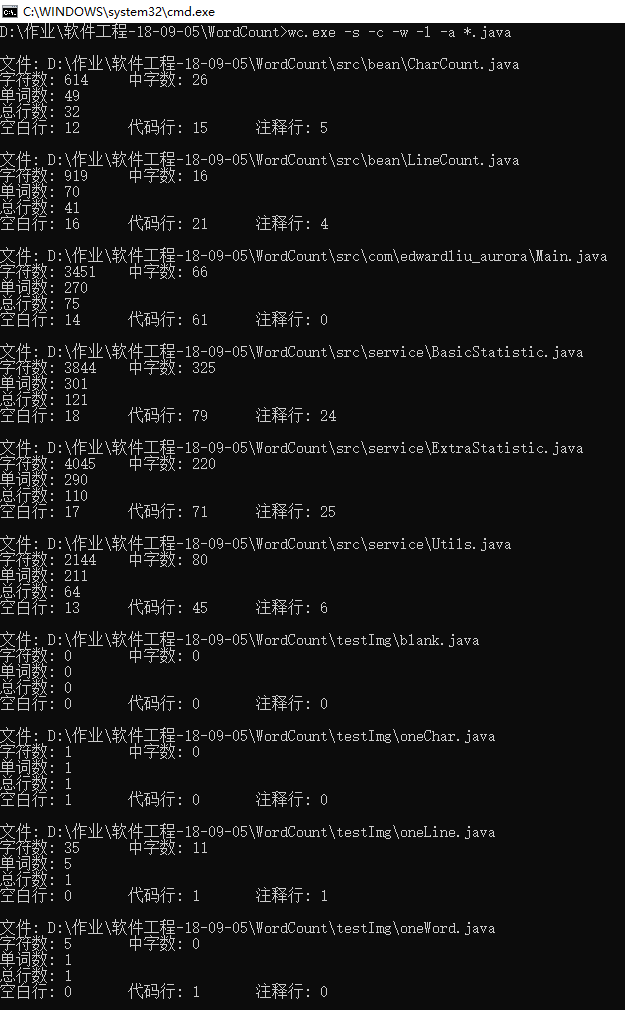
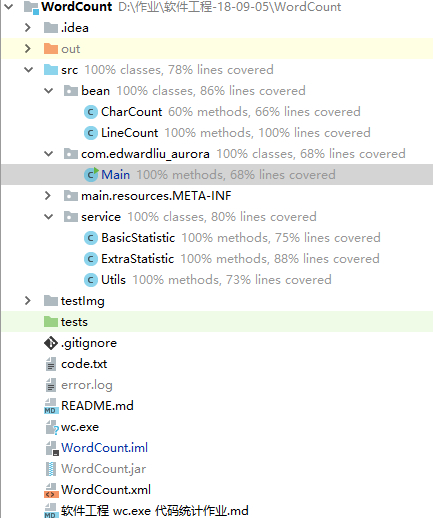
代码覆盖率测试
7. 实际花费时间 (见开头 PSP 表,已填入)
8. 项目小结
-
我在这个项目中使用了 Java 1.8 中才开始支持的 Stream API。好处是可以支持函数式编程,可以很方便地用并行运算对文件进行统计工作。而同时这也带来了一个问题——用户必须使用 JRE 1.8+ 的版本才能运行我的程序。
-
在这个项目中,我在读取文件时发现了一个文件编码的识别问题。文件编码的识别问题本身比较复杂,因为 Windows 下的文本文件,有的带有 BOM 头信息,而有的没有携带 BOM 头信息。 对于有携带 BOM 头信息的,我可以很方便地识别出该文件是否为 UTF-8 编码。然而,有很多文件是没有 BOM 编码的,我只能根据异常来猜测这个文件是什么编码的。所以目前我的编码识别函数只能支持 UTF-8 和 GBK 两种编码,并没有支持其他编码。一旦用户的文本文件是其他编码的,我的程序会出现不可预知的错误。
-
我没有对用户输入的参数进行判断和校验。我只对是否存在这个文件做了简单的校验。一旦用户把命令输入错误了,我的程序将发生无法预料的错误。
-
使用软件工程的方法来进行项目的设计,前期也许会花费很多时间,但是事后在编写的过程中会更加清晰有条理,让整体项目设计变得更加可控。
