JavaEE面试题目(一)(servlet、Spring)
TCP和UDP的区别?
相同点:
UDP协议和TCP协议都是传输层协议。
不同点:
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接.
2. TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;
UDP尽最大努力交付,即不保证可靠交付
3. TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4. 每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信。
5. TCP首部开销20字节;UDP的首部开销小,只有8个字节
6. TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
Servlet的生命周期
Servlet是运行在服务器端,以多线程的方式处理客户端请求的小程序。是sun公司提供的一套规范(规范的实现是接口)。
(1) servlet对象默认是在用户第一次访问的时候创建的,并且只创建一次,创建的时候调用init()方法。(也可以在servlet配置里面第三行加上
1 这样会在服务器启动的时候servlet对象就创建)
(2) 请求交给service()方法,由service()方法调用doGet或doPost方法或其他的方法。
(3) 服务器关闭的时候servlet对象被销毁,把工程从tomcat服务器中移除,对象也会销毁,销毁时会调用destroy方法。但是销毁是调用的finalized()方法进行销毁的。
servlet创建的方法
(1)最早是implements实现servlet接口,实现接口的重写方法太多,有的不一样需要
(2)后来extends GenericServlet(抽象类)类,实现service方法,不能区分请求的方式,是get请求还是post请求
(3)现在extends HttpServlet(抽象类)(javax 下的包,是上一个的子类)。
说一下servlet的体系结构?
所有的servlet都必须实现核心的接口是就javax.servlet.Servlet。每一个Servlet都必须直接或间接的实现这个接口,或者是继承javax.servlet,GenericServlet或者javax.servlet.http.HttpServlet。最后,Servlet使用多线程可以并行的为多个请求服务。
Session和Cookie的区别和联系;说明在自己项目中的使用
Session和cookie都是会话(Seesion)跟踪技术。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。但是Session的实现依赖于Cookie,sessionId(session的唯一标识需要存放在客户端)
cookie 和session 的区别:
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、所以个人建议:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中,比如购物车
购物车最好使用cookie,但是cookie是可以在客户端禁用的,这时候我们要使用cookie+数据库的方式实现,当从cookie中不能取出数据时,就从数据库获取。
转发和重定向的联系和区别
- 转发:服务器端的跳转,路径不会发生改变(针对的是servlet),是服务器内部的处理,一次请求,请求对象不会变
- 重定向:客户端的跳转,路径会发生改变,将要请求的路径和302重定向的状态码发给客户端浏览器,客户端浏览器将再次向服务器发出请求,不是同个请求,两次请求。
JSP的工作原理
混合了Java代码和HTML代码运行在服务器端的脚本
JSP的运行模型(工作流程)
用户第一次访问JSP页面的时候,服务器会将JSP文件转换成.java文件,之后编译成字节码文件,加载到JVM,如果JSP文件不做修改,那么上述的步骤不会再来一遍,如果JSP文件发生改变,会重新生成java文件,和新编译成字节码文件,加载到JVM。
MVC模式及其优缺点
使用MVC模式完成分页功能的基本思路是什么
1)页面提交页码(第几页)到Servlet中
2)Servlet接收到页码后,将页码传递给分页工具类(PageBean)
3)Servlet中调用Service层传入PageBean对象
4)Service层调用DAO层传入PageBean对象
5)Servlet中得到查询出来的数据,并setAttribute保存
6)在页面中得到(getAttribute)数据,遍历输出
拦截器和过滤器的区别
都是AOP编程思想,都能实现权限检查,日志记录等
- 拦截器是基于java的反射机制的,而过滤器是基于函数回调。
- 拦截器不依赖与servlet容器,过滤器依赖与servlet容器。
- 拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用。
- 拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问。
- 在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次。
拦截器可以获取IOC容器中的各个bean,而过滤器就不行,这点很重要,在拦截器里注入一个service,可以调用业务逻辑。
Spring的IOC(简单介绍概念,重要的说明,你怎么理解的)
IOC(inverse of control):控制反转 ,将对象创建的控制权交给IOC容器,应用对象时,再从容器中获得。还有一个更确切的名字叫做DI(dependency injection)依赖注入,创建对象时根据对象之间的依赖关系根据配置自动注入依赖对象。
(1) 作用
创建对象并且维护对象间依赖的关系
(2) 实现原理
反射
(3) 依赖注入的三种方式:
- 构造方法注入:即被注入对象可以通过在其构造方法中声明依赖对象的参数列表,让外部(通常是IOC容器)知道它需要哪些依赖对象,然后IOC容器会检查被注入对象的构造方法。
- setter方法注入:即当前对象只需要为其依赖对象所对应的属性添加setter方法,IOC容器通过此setter方法将相应的依赖对象设置到被注入对象的方式即setter方法注入。
- 接口注入:接口注入有点复杂,被注入对象如果想要IOC容器为其注入依赖对象,就必须实现某个接口,这个接口提供一个方法,用来为被注入对象注入依赖对象,IOC容器通过接口方法将依赖对象注入到被注入对象中去。相对于前两种注入方式,接口注入比繁琐和死板,被注入对象就必须专声明和实现另外的接口。
(4) 注解的方式。
@ Repository 用于创建持久层对象(dao层)
@Service 用于创建service层对象
@Controller 用于创建控制层对象
@Component 用于创建普通对象
@Scope("prototype") 设置是否是单例对象 单例singleton 非单例prototype
@Lazy(value=true) 设置是否启用懒加载
注入成员属性的注解
@Autowired(byName+byType)
@Resource
默认情况下,IOC容器中创建的对象都是单列对象
bean标签上添加scope=”prototype”设置非单例对象。
Spring的AOP原理,及其关键名词概念(简单介绍概念,重要的说明,你怎么理解的)
Aspect Oriented Programing面向切面编程。
AOP采取横向抽取机制,取代了传统纵向继承体系重复性代码
(性能监视,事务管理,安全检查、缓存,日志)
使用了纯java实现,不需要专门的编译过程和类加载器,在运行期间通过代理方式向目标类织入增强代码。
(1) 原理
通过代理的方式
JDK动态代理:针对接口生成子类
CGLIB代理:针对目标类生成子类
MySQL的读写分离,利用mycat中间件 + AOP技术实现读写分离,采用AO拦截业务层逻辑的方法,判断方法的前缀是写操作还是读操作,在读数据源和写数据源之间进行切换。
在Spring 2.0.1中引入了AbstractRoutingDataSource, 该类充当了DataSource的路由中介, 能有在运行时, 根据某种key值来动态切换到真正的DataSource上。
SpringMVC运行原理(项目中用它优势是什么,从项目组实际工作来说明)
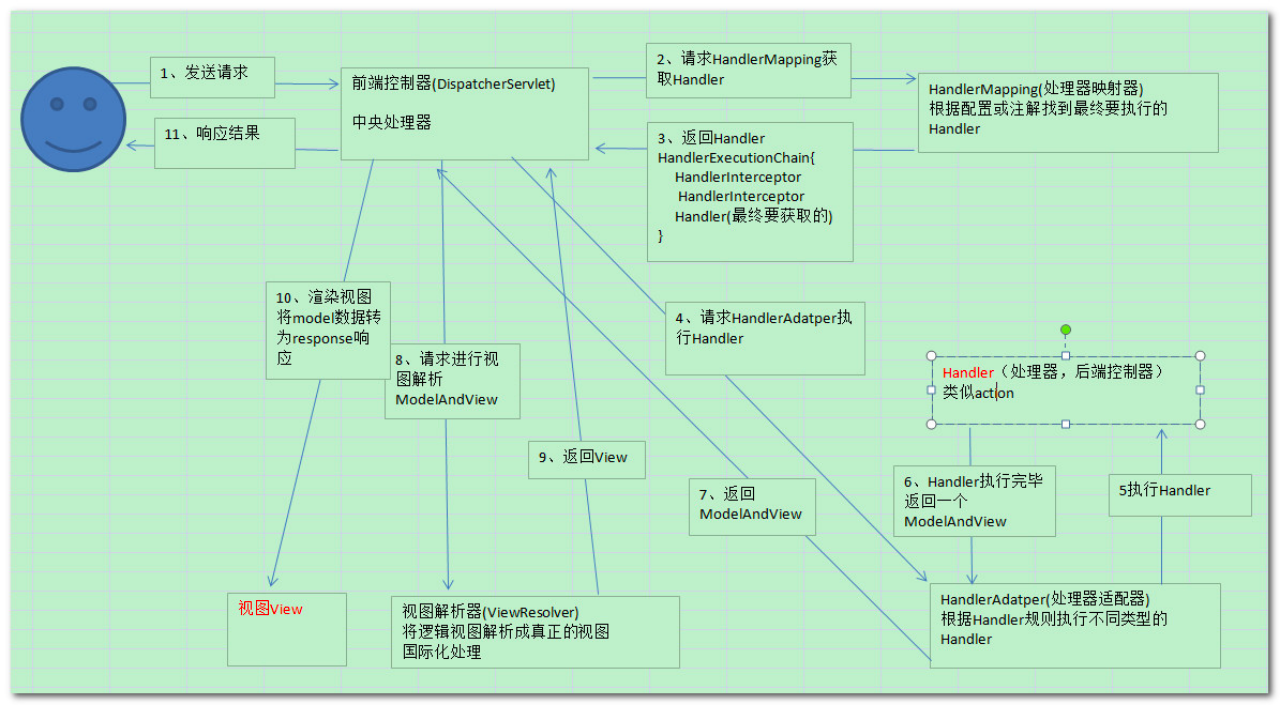
(1)用户向服务器发送请求,请求被Spring前端控制Servlet(DispatcherServlet)捕获。(捕获)
(2)DispatcherServlet对请求URL进行解析,得到请求资源标志符(uri),然后根据该URI,调用handlerMapping,获得该handler配置的所有相关对象(包括handler对象以及handler对象对应的拦截器),最后以handlerExcutionChain对象的形式返回。(查找Handler)
(3)DispatcherServlet 根据获得的Handler,选择合适的HandlerAdapter,提取request中的数据模型,填充入Handler入参,开始执行Handler,Handler执行完成后,向DispatcherServlet返回一个ModelAndView对象。(执行handler)
(4)DipatcherServlet根据返回的ModelAndView,选择一个合适的ViewResolver(必须已经注入到Spring容器中的ViewResolver)(选择ViewResolver)
(5)通过ViewResolver结合Model和View,来渲染视图,DispatcherServlet将渲染的结果返回客户端。(渲染返回)
SpringMVC中的拦截器作用?举例说明,项目中的使用场景和作用
SpringMVC中的拦截器也是相当重要的,它的主要作用是拦截用户的请求并进行相应的预处理和后处理,通常的还有如下作用:日志记录、权限检查、性能监控、通用行为
Spring MVC中的拦截器请求是通过HandlerInterceptor来实现的:
(1)要定义的Interceptor类要实现了Spring的HandlerInterceptor接口
(2)要定义的Interceptor类继承实现了HandlerInterceptor接口的类(比如HandlerInterceptorAdapter类)
HandlerInterceptor有三个方法:
preHandle在请求处理之前进行调用
postHandle在请求处理之后调用
afterCompletion在整个请求结束之后调用
1、异常处理概述
在J2EE项目的开发中,每个异常都单独处理,系统的代码耦合度高,工作量大:
(1)使用Spring MVC提供的简单异常处理器SimpleMappingExceptionResover
(2)实现Spring的异常处理接口HandlerExceptionResolver自定义的异常处理器
(3)使用@ExceptionHandler注解实现异常处理
参考:https://www.cnblogs.com/liufei2/p/13765947.html
Memcache 与 Redis 的区别都有哪些?
- 存储方式:Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。 Redis有部份存在硬盘上,redis可以持久化其数据。
- 数据支持类型:memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型 ,提供list,set,zset,hash等数据结构的存储
- 使用底层模型不同:它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。
Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求
4、value 值大小不同:Redis 最大可以达到 1gb;memcache 只有 1mb。
5、速度:redis的速度比memcached快很多。(redis写8万/s,读11万/s)
6、Redis支持数据的备份,即master-slave模式的数据备份 。
7、架构层次:Redis 支持主从模式应用,memcache 支持分布式。
Memcached本身并不支持分布式,因此只能在客户端通过像一致性哈希这样的分布式算法来实现Memcached的分布式存储。
相较于Memcached只能采用客户端实现分布式存储,Redis更偏向于在服务器端构建分布式存储。
Redis更多场景是作为Memcached的替代者来使用,当需要除key-value之外的更多数据类型支持或存储的数据不能被剔除时,
使用Redis更合适。如果只做缓存的话,Memcached已经足够应付绝大部分的需求,Redis 的出现只是提供了一个更加好的选择。
总的来说,根据使用者自身的需求去选择才是最合适的。
redis的持久化
Redis是内存数据库,如果不将内存中的数据库状态保存到磁盘中,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以redis提供了持久化功能!
两种方式RDB和AOF。默认是RDB
RDB
RDB:在指定的时间间隔将内存中的数据集体写入到磁盘中,也就是行话说的snpshot快照,它恢复时是将快照文件直接读到内存里。
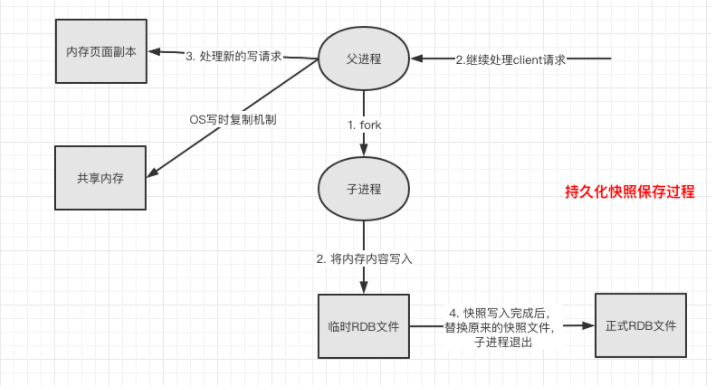
Redis会单独创建一个fork子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程结束了,再用这个临时文件替换上次持久化好的文件。整合过程,主进程不进行任何的IO操作,这就确保了极高的性能,如果需要进行大规模的恢复,且对数据的完整性不是非常敏感,那RDB方式要比AOF方式更加高效。RDB的缺点时最后一次持久化后的数据可能会丢失,默认就是RDB,一般情况下,不需要修改这个配置!
RDB保存的文件是:dump.rdb
触发机制
- save的规则满足的情况下,会自动触发rdb规则。
- 执行flushdb或flushall命令,也会触发我们的rdb机制
- 退出redis
优点:
- 适合大规模的数据恢复!
- 对数据的完整性要求不高!
缺点:
- 需要一定的时间间隔进程操作!如果redis意外宕机,这个最后一次修改数据就没有了!
- fork进程的时候,会占用一定的内存空间!!
AOF(Append Only File)
将我们的所有命令都记录下来,history,恢复的时候就把这个文件全部在执行一遍。
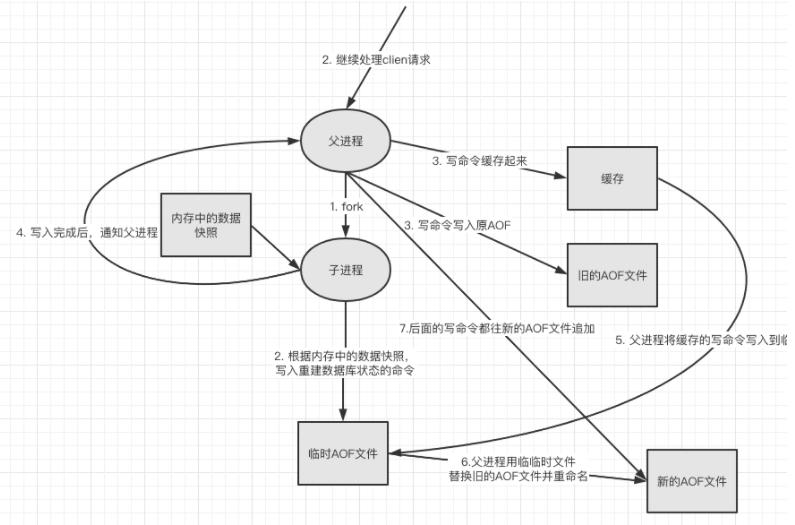
以日志的形式来记录每个写操作,将Redis执行过的所有指定记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
appendonly yes
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"
默认不开启,我们需要手动开启。
重启之后,就会自动有了这个aof文件。
如果aof文件有错位,这个时候redis是启动不起来的。我们需要修复这个文件
redis给我们提供了一个工具redis-check-aof --fix
[root@hadoop001 bin]# redis-check-aof --fix appendonly.aof
0x 62: Expected \r\n, got: 6161
AOF analyzed: size=147, ok_up_to=81, diff=66
This will shrink the AOF from 147 bytes, with 66 bytes, to 81 bytes
Continue? [y/N]: y
Successfully truncated AOF
[root@hadoop001 bin]#
它的修复是,删除出错之后的所有指令
优点和缺点
# appendfsync always # 每次修改都会sync。消耗性能
appendfsync everysec # 每秒执行一次,sync。可能会丢失这1s的数据
# appendfsync no # 不执行sync,这个时候操作系统自己同步数据,数独最快
# rewrite 规则
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature.
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb # 如果aof文件大于64mb,太大了,fork一个新的进程来讲我们的文件进行重写
aof默认就是文件的无限追加,文件回越来越大!
优点:
- 每一次修改都同步,文件的完整性更好。
- 每秒同步一次,kennel回丢失1s的数据。
- 从不同步,效率最高!
缺点:
- 相对于数据文件来说,aof远远大于rdb,恢复的速度也比rdb慢
- AOF运行效率也要比rdb慢,所以我们redis默认的配置就是rdb持久化。
扩展:
1、RDB持久化方式能够在指定的时间间隔内对你的数据进行快照存储。
2、 AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾,Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
3、 只做缓存,如果你希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化操作。
4、 同时开启两种持久化方式
- 在这种情况下,当redis重启的时候,会优先载入AOF文件来恢复原始数据,因为在通常情况下AOF保存的数据要比RDB文件保存的数据要完整。
- RDB数据不实时,同时使用两者的时候,服务器重启也只会找AOF文件,那要不要只使用AOF呢?建议不要,因为RDB更适合用于备份数据库(AOF不断变化不好备份),快速重启,而且不会有AOF可能潜在的Bug,留着作为万一的手段。
5、 性能建议
- 因为RDB文件只用作后备用途,建议只在slave上持久化RDB文件,而且只要15分钟就够了,只保留save 900 1这条规则。
- 如果enable AOF,好处是在最恶劣情况下也只会丢失不超过两秒的数据,启动脚本较简单只load自己的AOF文件就可以了,代价一是带来了持续的IO,二是AOF rewrite的最后将rewirte过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小值是64mb太小,可以设置5G以上,默认超过原大小100%大小重写,可以改到适当的数值。
- 如果disable AOF,仅靠Master-slave replication实现高可用性也可以。能省掉一大笔IO,也减少rewrite时,带来的系统波动。代价是如果master/slave同时倒掉,会丢失十几分钟的数据,启动脚本也要比较两个master/slave中的RDB文件,载入较新的那个,微博就是这种架构。
哨兵模式
自动选举老大的模式
哨兵模式是一种特殊的模式,首先redis提供了哨兵命令,哨兵是一个独立的进程,他会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
然而一个哨兵进程对Redis服务器进行监测,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
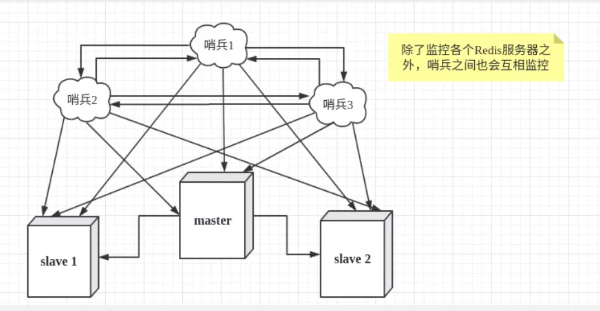
假设主服务器宕机,哨兵1先监测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果时由一个哨兵发起的,进行failover【故障转移】操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称之为客观下线。
哨兵模式
优点:
1、哨兵集群,基于主从复制模式,所有的主从配置优点,它全有
2、主从可以切换,故障可以转移,系统的可用性就会更好
3、哨兵模式就是主从复制的升级,手动到自动,更加健壮!
缺点:
1、 Redis不好在线扩容,集群容量一旦到达上限,在线扩容就十分麻烦!
2、实现哨兵模式的配置其实是很麻烦的,里面有很多选择!
Redis缓存穿透、击穿和雪崩
穿透(查不到)
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决办法:
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免对底层存储系统的查询压力
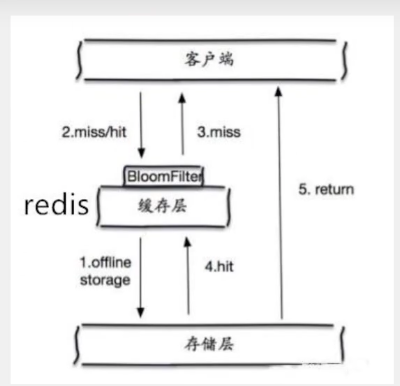
缓存空对象
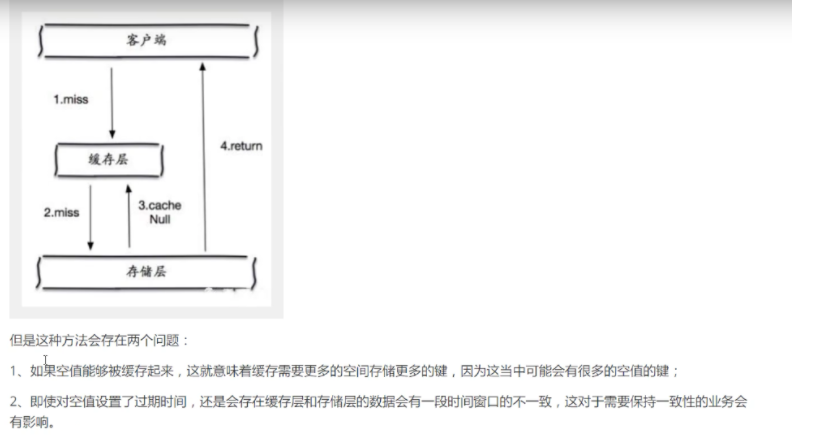
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据降会从缓存中获取,保护了后端数据源;
在网关层限制某一时间区间内相同IP的调用次数,防止恶意用户不断的更换参数请求服务器。
缓存击穿(量太大,缓存过期)
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
设置热点数据永不过期
从缓存层面来说,没有设置过期时间,所以不会出现热点Key过期后产生的问题。
互斥加锁
分布式锁:使用分布式锁,保证对于每个Key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大
缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
redis高可用
这个思想的含义是:既然redis有可能挂了,那我就多增加几台redis,这样一台挂掉之后其他的还是可以正常工作的,其实就是搭建的集群。
降流限级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和鞋缓存,其他线程等待。
数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间尽量均匀。
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
设置热点数据永远不过期。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号