Logstash读取Kafka数据写入HDFS详解
准备工具
# 先看看linux上的IP配置:cat /etc/hosts
192.168.27.129 hadoop001
192.168.27.129 localhost
先安装zookeeper
修改Kafka的配置文件,首先进入安装路径conf目录,并将zoo_sample.cfg文件修改为zoo.cfg,并对核心参数进行配置
# 我的配置
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/zookeeper-3.6.2/data
dataLogDir=/usr/local/zookeeper-3.6.2/log
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
zookeeper启动起来使用jps查看一下进程
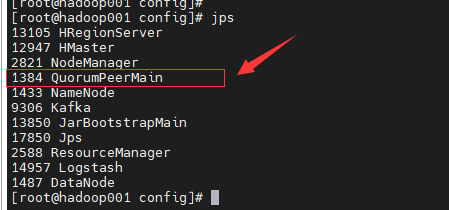
安装hadoop
cd /usr/local/hadoop-2.7.2/etc/hadoop
# 把下面配置加上
vim core-site.xml
<property>
<name>fs.defaultFS</name>
<!-- 这里填的是你自己的ip,端口默认-->
<value>hdfs://hadoop001:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 这里填的是你自定义的hadoop工作的目录,端口默认-->
<value>/usr/local/hadoop-2.7.2/data/tmp</value>
</property>
修改 hadoop-env.sh文件
# 将下面的注释打开,并换成自己的jdk目录
export JAVA_HOME=/usr/local/jdk1.8.0_144
修改hdfs-site.xml文件,加上下面的内容
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
然后启动namenode和dataNode
# 启动前需要格式化一下
bin/hdfs namenode -format
cd /usr/local/hadoop-2.7.2/sbin
./hadoop-daemon.sh start namenode
./hadoop-daemon.sh start datanode
启动完成之后,jps看下

然后本地访问:http://hadoop001:50070/dfshealth.html#tab-overview
就可以看到下面的内容
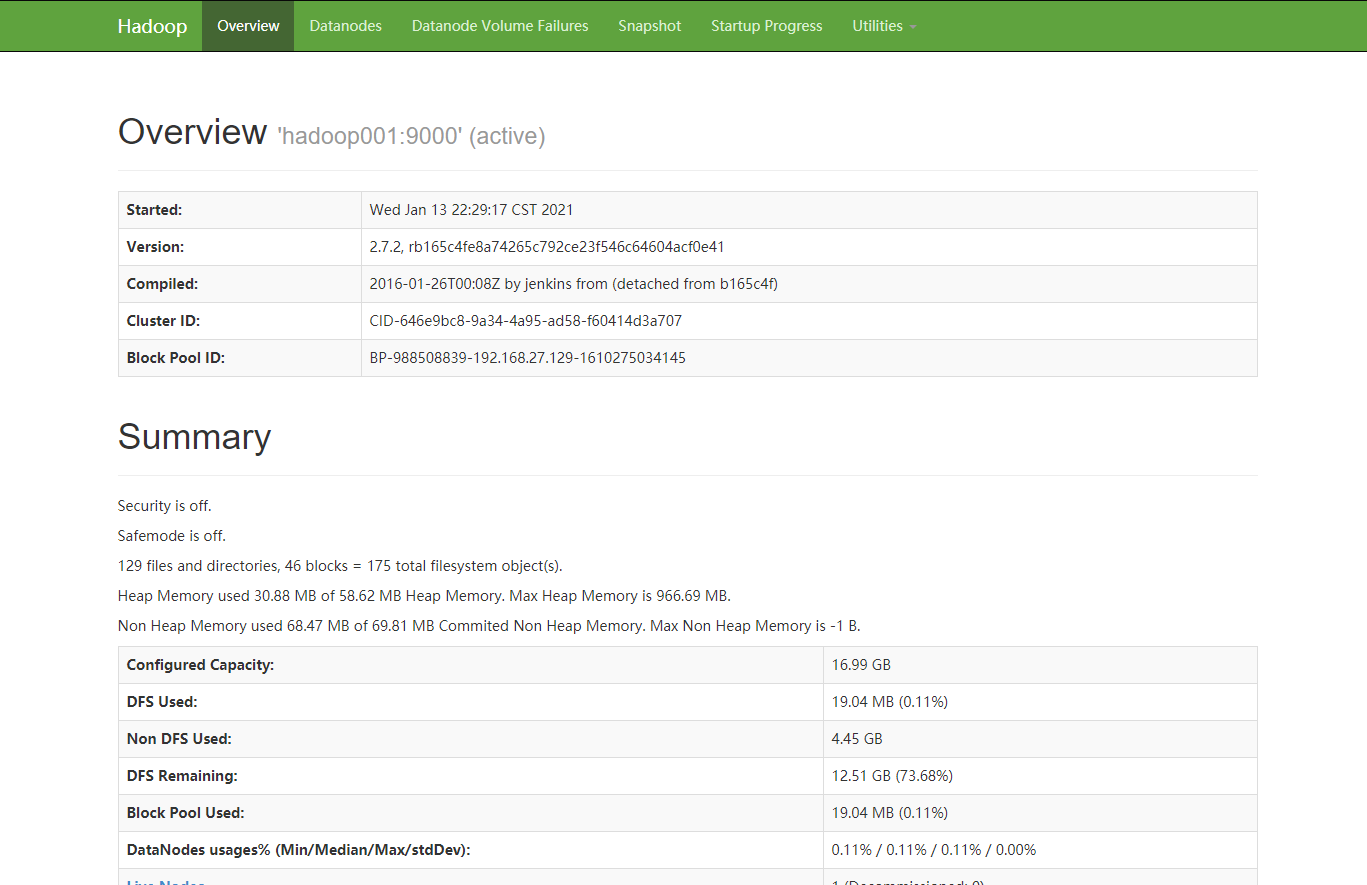
注意:因为是在本地访问的,所以本地的hosts文件需要加上下面的内容
# 192的ip就是我的linux上的ip
192.168.27.129 hadoop001
继续修改配置文件
配置:mapred-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0_144
[root@hadoop001 hadoop]# vim mapred-site.xml
[root@hadoop001 hadoop]# pwd
/usr/local/hadoop-2.7.2/etc/hadoop
(对mapred-site.xml.template重新命名为) mapred-site.xml文件加上下面内容
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
修改yarn-site.xml文件,加上下面的内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
</property>
启动集群
(a)启动前必须保证NameNode和DataNode已经启动
(b)启动ResourceManager
[root@hadoop001 hadoop]# sbin/yarn-daemon.sh start resourcemanager
(c)启动NodeManager
[root@hadoop001 hadoop]# sbin/yarn-daemon.sh start nodemanager
启动成功之后,查看jps
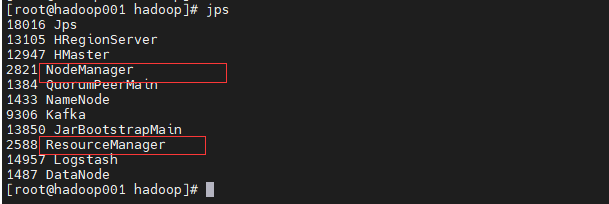
本地访问:http://hadoop001:8088/cluster
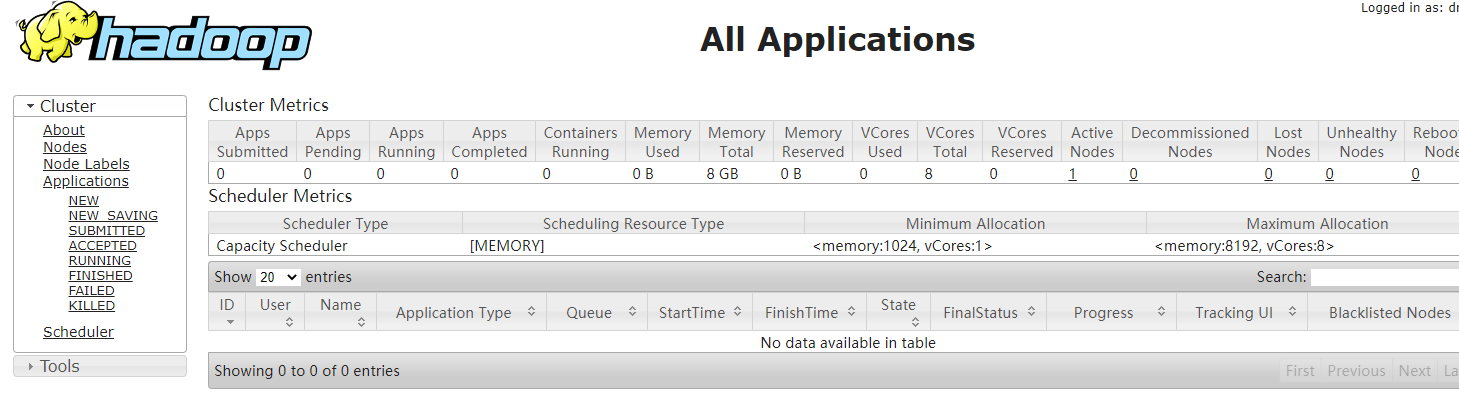
安装logstash
# cd /usr/local/logstash-7.6.2/
# ./bin/logstash-plugin install logstash-output-webhdfs
插件安装
插件安装比较简单,直接使用内置命令即可
在config目录下面新建配置文件record_logstash_hdfs.conf
input {
kafka {
bootstrap_servers => "hadoop001:9092"
topics => ["yiyang"]
codec => "json"
}
}
filter {
}
output {
webhdfs {
host => "hadoop001"
port => 50070
user => "root"
path => "/user/yiyang/record_traffic_hdfs-%{+yyyy-MM-dd}.log"
codec => "json"
}
stdout { codec => rubydebug }
}
logstash配置文件分为三部分:input、filter、output
input指定源在哪里,我们是从kafka取数据,这里就写kafka集群的配置信息,配置解释:
bootstrap_servers:指定kafka集群的地址
topics:需要读取的topic名字
codec:指定下数据的格式,我们写入的时候直接是json格式的,这里也配置json方便后续处理
filter可以对input输入的内容进行过滤或处理,例如格式化,添加字段,删除字段等等
这里我们主要是为了解决生成HDFS文件时因时区不对差8小时导致的文件名不对的问题,后边有详细解释
output指定处理过的日志输出到哪里,可以是ES或者是HDFS等等,可以同时配置多个,webhdfs主要配置解释:
host:为hadoop集群namenode节点名称
user:为启动hdfs的用户名,不然没有权限写入数据
path:指定存储到HDFS上的文件路径,这里我们每日创建目录,并按小时存放文件
stdout:打开主要是方便调试,启动logstash时会在控制台打印详细的日志信息并格式化方便查找问题,正式环境建议关闭
webhdfs还有一些其他的参数例如compression,flush_size,standby_host,standby_port等可查看官方文档了解详细用法
启动logstash
# bin/logstash -f config/record_logstash_hdfs.conf
复制代码
启动完成之后,然后往kafka里面发送数据
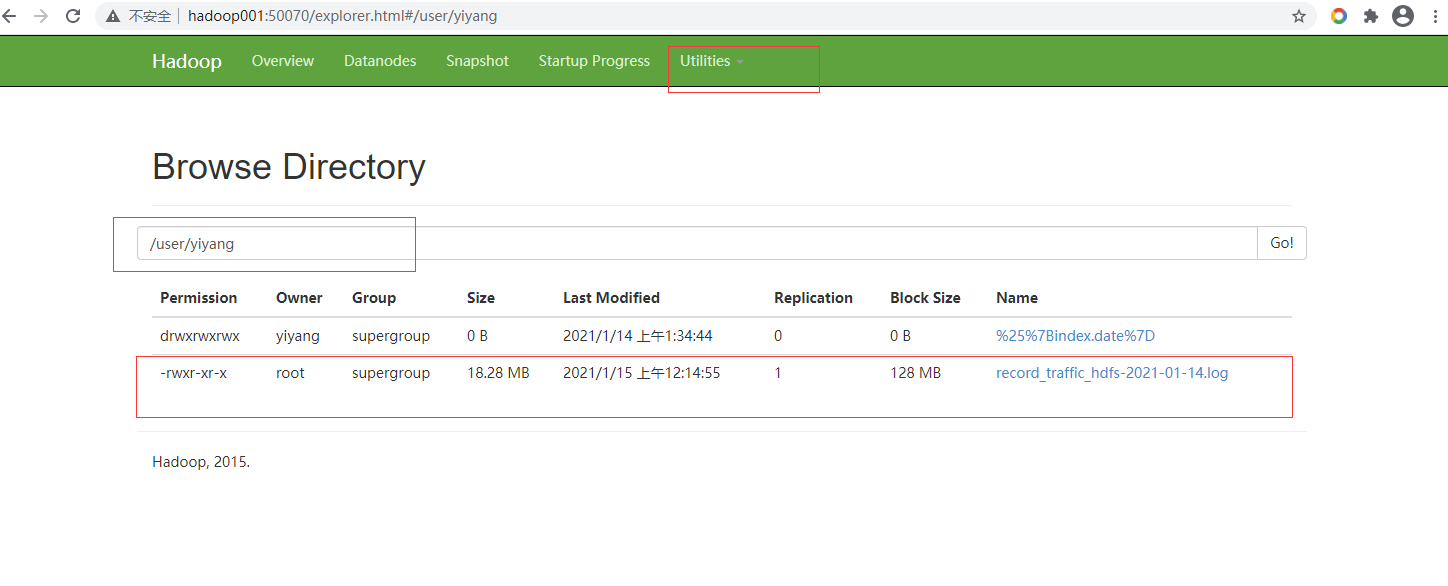
此时查看HDFS页面,就可以看到文件了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号