Elasticsearch的查询(四)
检索文档
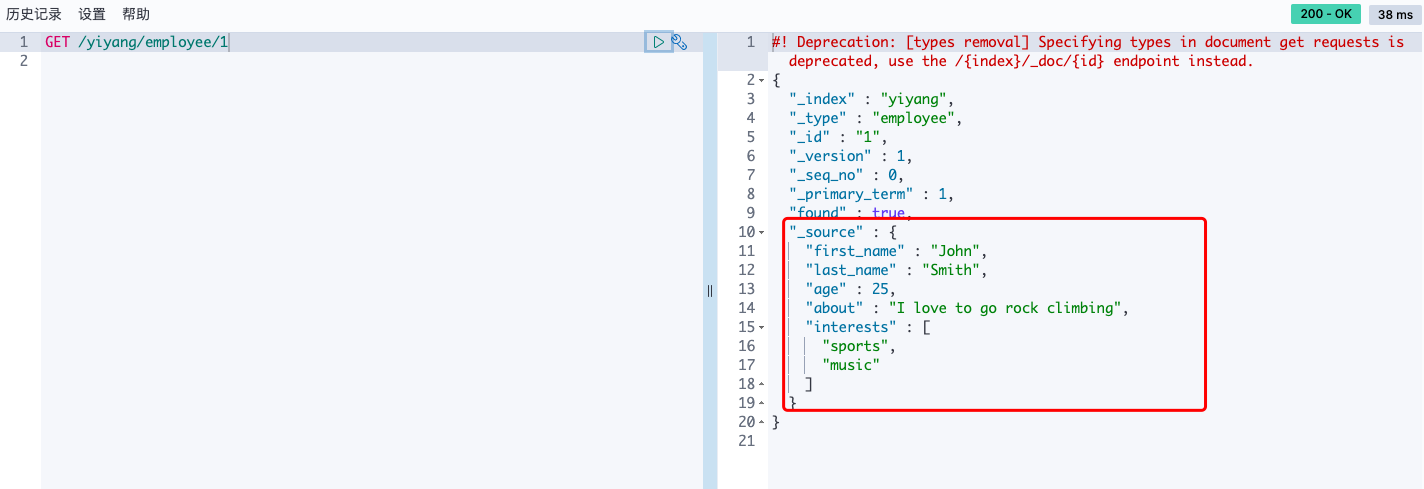
查询单个雇员的信息
GET /yiyang/employee/1
查询所有的
GET /yiyang/employee/_search
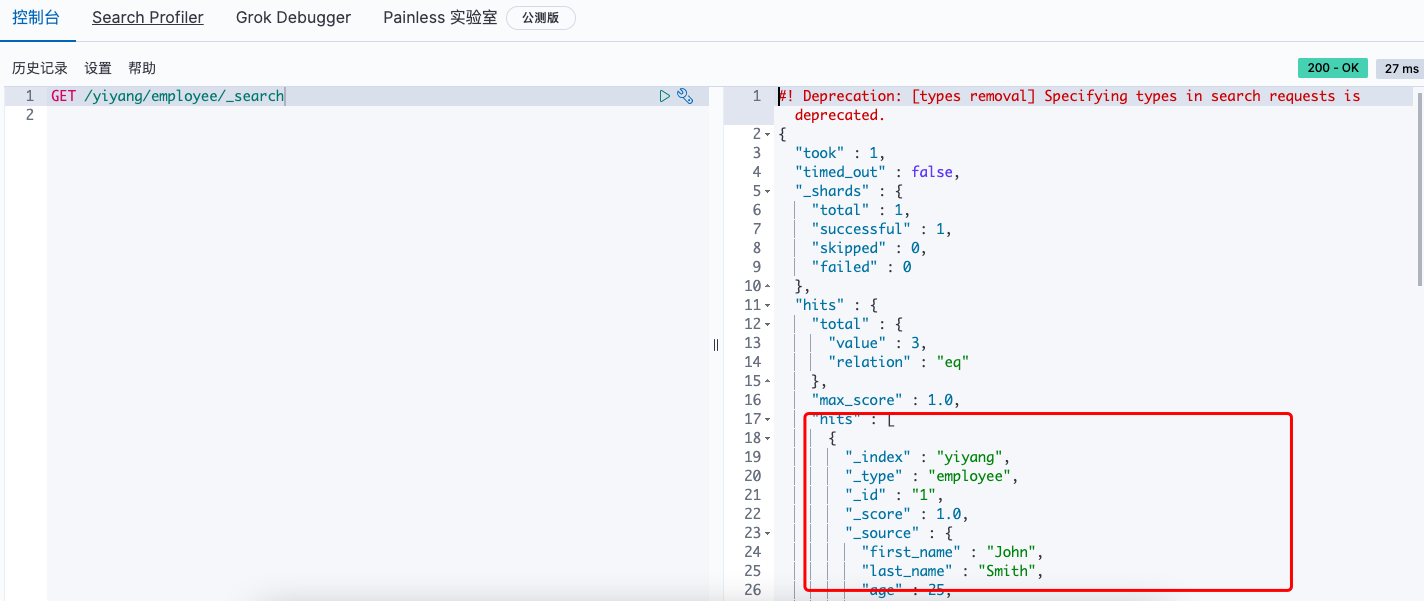
数据都在hits中
使用查询表达式搜索
GET /yiyang/employee/_search
{
"query": {
"match": {
"last_name": "Smith"
}
}
}
这个请求使用 JSON 构造,并使用了一个 match 查询(属于查询类型之一)。
match是必须全等于,相当于MySQL中的=
更复杂的搜索
现在尝试下更复杂的搜索。 同样搜索姓氏为 Smith 的员工,但这次我们只需要年龄大于 30 的。查询需要稍作调整,使用过滤器 filter ,它支持高效地执行一个结构化查询。
GET /yiyang/employee/_search
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}
这部分是一个 range 过滤器 , 它能找到年龄大于 30 的文档,其中 gt 表示_大于_(great than)。
扩展:gte表示大于等于,lt表示小于,lte表示小于等于。
全文搜索
截止目前的搜索相对都很简单:单个姓名,通过年龄过滤。现在尝试下稍微高级点儿的全文搜索——一项 传统数据库确实很难搞定的任务。
搜索下所有喜欢攀岩(rock climbing)的员工:
GET /yiyang/employee/_search
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}
显然我们依旧使用之前的 match 查询在about 属性上搜索 “rock climbing” 。得到两个匹配的文档:
{
"took" : 61,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
...
"hits" : [
{
"_index" : "yiyang",
"_type" : "employee",
"_id" : "1",
"_score" : 1.4167401,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests" : [
"sports",
"music"
]
}
},
{
"_index" : "yiyang",
"_type" : "employee",
"_id" : "2",
"_score" : 0.4589591,
"_source" : {
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests" : [
"music"
]
}
}
]
}
}
Elasticsearch 默认按照相关性得分排序,即每个文档跟查询的匹配程度。第一个最高得分的结果很明显:John Smith 的 about 属性清楚地写着 “rock climbing” 。
但为什么 Jane Smith 也作为结果返回了呢?原因是她的 about 属性里提到了 “rock” 。因为只有 “rock” 而没有 “climbing” ,所以她的相关性得分低于 John 的。
match查询会将传递的条件进行分词查询。所以会把第二条数据也会查询出来。
短词搜索
找出一个属性中的独立单词是没有问题的,但有时候想要精确匹配一系列单词或者_短语_ 。 比如, 我们想执行这样一个查询,仅匹配同时包含 “rock” 和 “climbing” ,并且 二者以短语 “rock climbing” 的形式紧挨着的雇员记录。
为此对 match 查询稍作调整,使用一个叫做 match_phrase 的查询:
GET /yiyang/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}
毫无悬念,返回结果仅有 John Smith 的文档。
...
"hits" : [
{
"_index" : "yiyang",
"_type" : "employee",
"_id" : "1",
"_score" : 1.0498221,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests" : [
"sports",
"music"
]
}
}
]
}
}
这里的match_phrase是匹配短词,使查询条件不分词。假设在有一个雇员,起about是 I love to go rock a climbing,那么也是只能查询出John Smith 的文档。
高亮搜索
许多应用都倾向于在每个搜索结果中 高亮 部分文本片段,以便让用户知道为何该文档符合查询条件。在 Elasticsearch 中检索出高亮片段也很容易。
再次执行前面的查询,并增加一个新的 highlight 参数:
GET /yiyang/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}
当执行该查询时,返回结果与之前一样,与此同时结果中还多了一个叫做 highlight 的部分。这个部分包含了 about 属性匹配的文本片段,并以 HTML 标签 封装:
{
...
"hits" : [
{
"_index" : "yiyang",
"_type" : "employee",
"_id" : "1",
"_score" : 1.0498221,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests" : [
"sports",
"music"
]
},
"highlight" : {
"about" : [
"I love to go <em>rock</em> <em>climbing</em>"
]
}
}
]
}
}
聚合(aggregations)分析。(类似于MySQL的group by)
终于到了最后一个业务需求:支持管理者对员工目录做分析。 Elasticsearch 有一个功能叫聚合(aggregations),允许我们基于数据生成一些精细的分析结果。聚合与 SQL 中的 GROUP BY 类似但更强大。
举个例子,挖掘出员工中最受欢迎的兴趣爱好:
GET /yiyang/employee/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "interests.keyword"
}
}
}
}
返回的结果是:
{
...
"aggregations" : {
"group_by_state" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "music",
"doc_count" : 2
},
{
"key" : "forestry",
"doc_count" : 1
},
{
"key" : "sports",
"doc_count" : 1
}
]
}
}
}
聚合还支持分级汇总 。比如,查询特定兴趣爱好员工的平均年龄:
GET /yiyang/employee/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "interests.keyword"
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
得到的聚合结果有点儿复杂,但理解起来还是很简单的:
{
...
"aggregations" : {
"group_by_state" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "music",
"doc_count" : 2,
"avg_age" : {
"value" : 28.5
}
},
{
"key" : "forestry",
"doc_count" : 1,
"avg_age" : {
"value" : 35.0
}
},
{
"key" : "sports",
"doc_count" : 1,
"avg_age" : {
"value" : 25.0
}
}
]
}
}
}
输出基本是第一次聚合的加强版。依然有一个兴趣及数量的列表,只不过每个兴趣都有了一个附加的 avg_age 属性,代表有这个兴趣爱好的所有员工的平均年龄。
参考文档:https://github.com/13428282016/elasticsearch-CN/wiki/es-gettting-started

 浙公网安备 33010602011771号
浙公网安备 33010602011771号