
2: 写一个demo(zeppeline 上用flink SQL 读kafka数据)
1: docker 安装kafka, 参考 : https://www.cnblogs.com/liufei1983/p/15706019.html
注意的是: topic 变成cdn_events.
kafka 生成如下的消息 :
{"uuid":"fdafafa","client_ip":"fdafasf","request_time": 123213,"response_size":123213,"uri": "fdsfs","event_ts":344}
2: 需要的jar包可以直接放到flink的lib目录下:
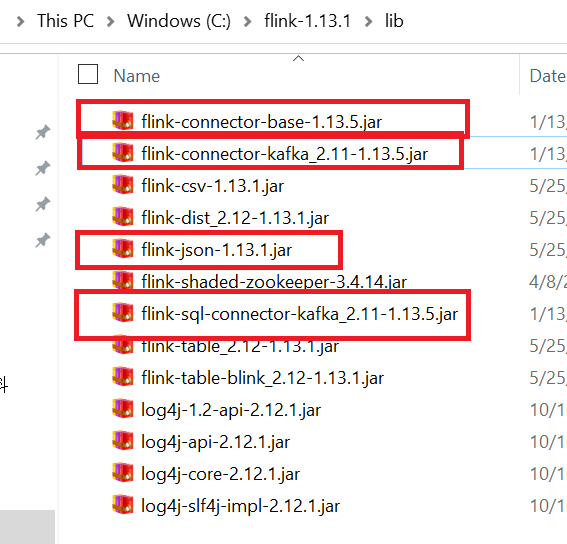
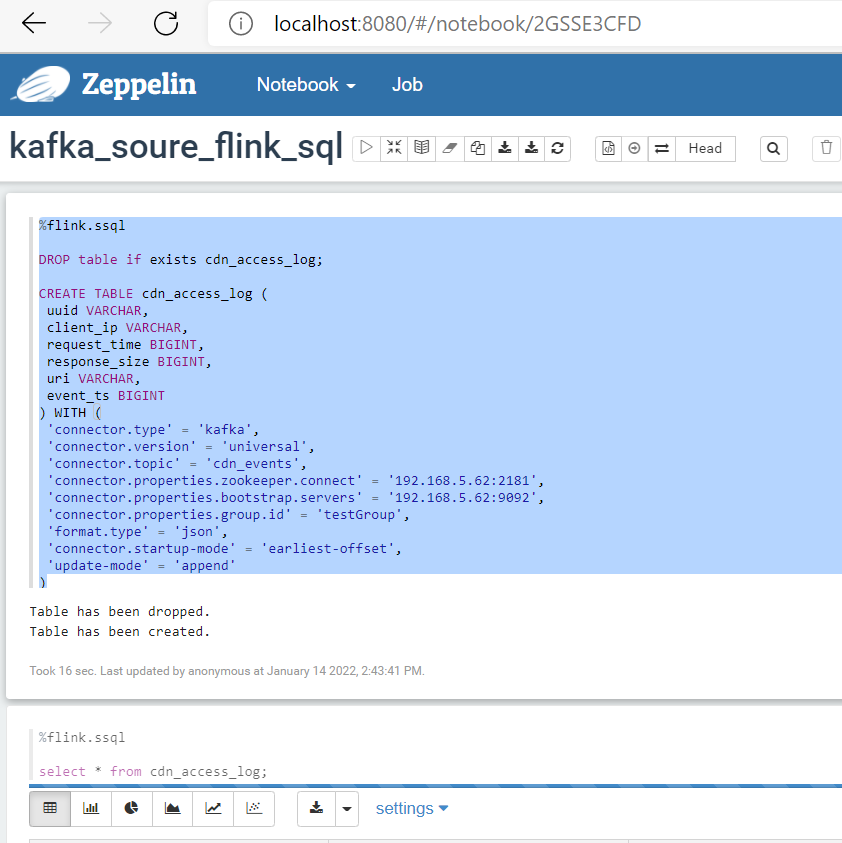
3: 创建一个source table;
%flink.ssql DROP table if exists cdn_access_log; CREATE TABLE cdn_access_log ( uuid VARCHAR, client_ip VARCHAR, request_time BIGINT, response_size BIGINT, uri VARCHAR, event_ts BIGINT ) WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'cdn_events', 'connector.properties.zookeeper.connect' = '192.168.5.62:2181', 'connector.properties.bootstrap.servers' = '192.168.5.62:9092', 'connector.properties.group.id' = 'testGroup', 'format.type' = 'json', 'connector.startup-mode' = 'earliest-offset', 'update-mode' = 'append' )
然后用SSQL 去读kafka数据
%flink.ssql select * from cdn_access_log;
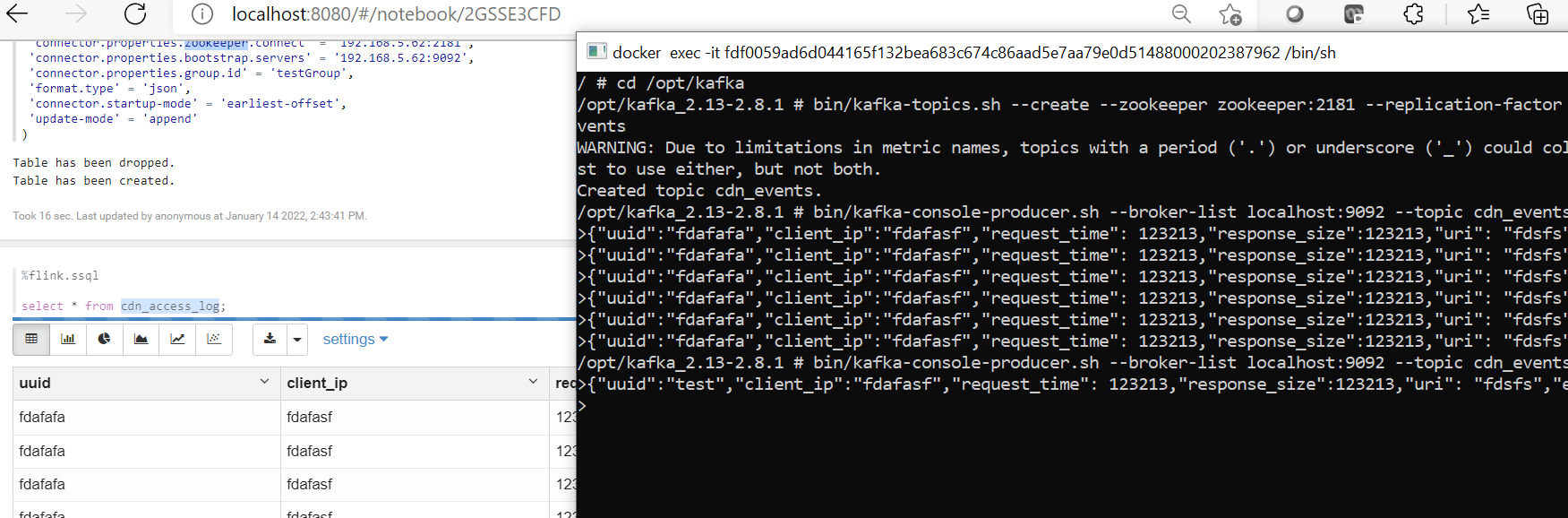
4: 在kafka的producer端,持续的产生数据,在flink SSQL端就会实时的读取数据进行处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号