
二 、监督学习 VS 无监督学习
机器学习的常用方法,主要分为有监督学习(supervised learning)和无监督学习(unsupervised learning)。
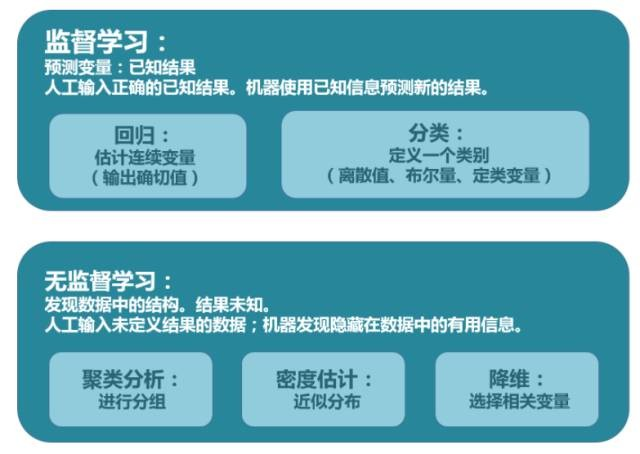
监督学习,就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,也就具有了对未知数据进行分类的能力。
在人对事物的认识中,我们从孩子开始就被大人们教授这是鸟啊、那是猪啊、那是房子啊,等等。我们所见到的景物就是输入数据,而大人们对这些景物的判断结果(是房子还是鸟啊)就是相应的输出。当我们见识多了以后,脑子里就慢慢地得到了一些泛化的模型,这就是训练得到的那个(或者那些)函数,从而不需要大人在旁边指点的时候,我们也能分辨的出来哪些是房子,哪些是鸟。监督学习里典型的例子就是KNN、SVM。
监督学习是训练神经网络和决策树的常见技术
无监督学习(也有人叫非监督学习,反正都差不多)则是另一种研究的比较多的学习方法,它与监督学习的不同之处,在于我们事先没有任何训练样本,而需要直接对数据进行建模。这听起来似乎有点不可思议,但是在我们自身认识世界的过程中很多处都用到了无监督学习。比如我们去参观一个画展,我们完全对艺术一无所知,但是欣赏完多幅作品之后,我们也能把它们分成不同的派别(比如哪些更朦胧一点,哪些更写实一些,即使我们不知道什么叫做朦胧派,什么叫做写实派,但是至少我们能把他们分为两个类)。无监督学习里典型的例子就是聚类了。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化。通俗点将就是实际应用中,不少情况下无法预先知道样本的标签,也就是说没有训练样本对应的类别,因而只能从原先没有样本标签的样本集开始学习分类器设计。
非监督学习目标不是告诉计算机怎么做,而是让它(计算机)自己去学习怎样做事情
两者的不同点
1. 有监督学习方法必须要有训练集与测试样本。在训练集中找规律,而对测试样本使用这种规律。而非监督学习没有训练集,只有一组数据,在该组数据集内寻找规律。
2. 有监督学习的方法就是识别事物,识别的结果表现在给待识别数据加上了标签。因此训练样本集必须由带标签的样本组成。而非监督学习方法只有要分析的数据集的本身,预先没有什么标签。如果发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不予以某种预先分类标签对上号为目的。
3. 非监督学习方法在寻找数据集中的规律性,这种规律性并不一定要达到划分数据集的目的,也就是说不一定要“分类”。
这一点是比有监督学习方法的用途要广。 譬如分析一堆数据的主分量,或分析数据集有什么特点都可以归于非监督学习方法的范畴。
4. 用非监督学习方法分析数据集的主分量与用K-L变换计算数据集的主分量又有区别。后者从方法上讲不是学习方法。因此用K-L变换找主分量不属于无监督学习方法,即方法上不是。而通过学习逐渐找到规律性这体现了学习方法这一点。在人工神经元网络中寻找主分量的方法属于无监督学习方法。
何时采用哪种方法
简单的方法就是从定义入手,有训练样本则考虑采用监督学习方法;无训练样本,则一定不能用监督学习方法。但是,现实问题中,即使没有训练样本,我们也能够凭借自己的双眼,从待分类的数据中,人工标注一些样本,并把它们作为训练样本,这样的话,可以把条件改善,用监督学习方法来做。对于不同的场景,正负样本的分布如果会存在偏移(可能大的偏移,可能比较小),这样的话,监督学习的效果可能就不如用非监督学习了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号