Java高并发与多线程(二)-----线程的实现方式
今天,我们开始Java高并发与多线程的第二篇,线程的实现方式。
通常来讲,线程有三种基础实现方式,一种是继承Thread类,一种是实现Runnable接口,还有一种是实现Callable接口,当然,如果我们铺开,扩展一下,会有很多种实现方式,但是归根溯源,其实都是这几种实现方式的衍生和变种。
我们依次来讲。
【第一种 · 继承Thread】
继承Thread之后,要实现父类的run方法,然后在起线程的时候,调用其start方法。
1 public class DemoThreadDemoThread extends Thread {
2 public void run() {
3 System.out.println("我执行了一次!");
4 }
5
6 public static void main(String[] args) throws InterruptedException {
7 for (int i = 0; i < 3; i++) {
8 Thread thread = new DemoThreadDemoThread();
9 thread.start();
10 Thread.sleep(3000);
11 }
12 }
13 }
这里,有些同学对start方法和run方法的作用理解有点问题,解释一下:
|
start()方法被用来启动新创建的线程,在start()内部调用了run()方法。 当你调用run()方法的时候,其实就和调用一个普通的方法没有区别。 |
【第二种 · 实现Runnable接口】
第二种方法,是实现Runnable接口的run方法,在起线程的时候,如下,new一个Thread类,然后把类当做参数传进去。
1 public class DemoThreadDemoRunnable implements Runnable { 2 public void run() { 3 System.out.println("我执行了一次!"); 4 } 5 6 public static void main(String[] args) throws InterruptedException { 7 for (int i = 0; i < 3; i++) { 8 Thread thread = new Thread(new DemoThreadDemoRunnable()); 9 thread.start(); 10 Thread.sleep(3000); 11 } 12 } 13 }
- 两种基础实现方式的选择
这两种方法看起来其实差不多,但是平时使用的时候我们如何做选择呢?
一般而言,我们选择Runnable会好一点;
首先,我们从代码的架构考虑。
实际上,Runnable 里只有一个 run() 方法,它定义了需要执行的内容,在这种情况下,实现了 Runnable 与 Thread 类的解耦,Thread 类负责线程启动和属性设置等内容,权责分明。
第二点就是在某些情况下可以提高性能。
使用继承 Thread 类方式,每次执行一次任务,都需要新建一个独立的线程,执行完任务后线程走到生命周期的尽头被销毁,如果还想执行这个任务,就必须再新建一个继承了 Thread 类的类,如果此时执行的内容比较少,比如只是在 run() 方法里简单打印一行文字,那么它所带来的开销并不大,相比于整个线程从开始创建到执行完毕被销毁,这一系列的操作比 run() 方法打印文字本身带来的开销要大得多。
如果我们使用实现 Runnable 接口的方式,就可以把任务直接传入线程池,使用一些固定的线程来完成任务,不需要每次新建销毁线程,大大降低了性能开销。
第三点好处在于可以继承其他父类。
Java 语言不支持双继承,如果我们的类一旦继承了 Thread 类,那么它后续就没有办法再继承其他的类,这样一来,如果未来这个类需要继承其他类实现一些功能上的拓展,它就没有办法做到了,相当于限制了代码未来的可拓展性。
- 为什么说Runnable和Thread其实是同一种创建线程的方法?
首先,我们可以去看看Thread的源码,我们可以看到:

其实Thread类也是实现了Runnable接口,以下是Thread的run方法:

其中的target指的就是你是实现了Runnable接口的类:
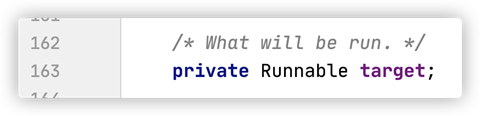
Thread被new出来之后,调用Thread的start方法,会调用其run方法,然后其实执行的就是Runnable接口的run方法(实现后的方法)。
所以,当你继承了Thread之后,你实现的run方法其实还是Runnable接口的run方法,
因此,其实无返回值线程的实现方式只有一种,那就是实现Runnable接口的run方法,然后调用Thread的start方法,start方法内部会调用你写的run方法,完成代码逻辑。
【第三种 · 实现Callable接口】
第 3 种线程创建方式是通过有返回值的 Callable 创建线程。
Callable接口实际上是属于Executor框架中的功能类,之后的部分会详细讲述Executor框架。
Callable和Runnable可以认为是兄弟关系,Callable的call()方法类似于Runnable接口中run()方法,都定义任务要完成的工作,实现这两个接口时要分别重写这两个方法;
主要的不同之处是call()方法是有返回值的,运行Callable任务可以拿到一个Future对象,表示异步计算的结果。
我们通过Future对象可以了解任务执行情况,可取消任务的执行,还可获取执行结果。
代码示例如下:
1 public class DemoThreadDemoCallable implements Callable<Integer> { 2 3 private volatile static int count = 0; 4 5 public Integer call() { 6 System.out.println("我是callable,我执行了一次"); 7 return count++; 8 } 9 10 public static void main(String[] args) throws InterruptedException, ExecutionException { 11 List<FutureTask<Integer>> taskList = new ArrayList<FutureTask<Integer>>(); 12 13 for (int i = 0; i < 3; i++) { 14 FutureTask<Integer> futureTask = new FutureTask<Integer>(new DemoThreadDemoCallable()); 15 taskList.add(futureTask); 16 } 17 18 for (FutureTask<Integer> task : taskList) { 19 Thread.sleep(1000); 20 new Thread(task).start(); 21 } 22 23 // 一般这个时候是做一些别的事情 24 Thread.sleep(3000); 25 for (FutureTask<Integer> task : taskList) { 26 if (task.isDone()) { 27 System.out.printf("我是第%s次执行的!\n", task.get()); 28 } 29 } 30 } 31 }
执行结果如下:
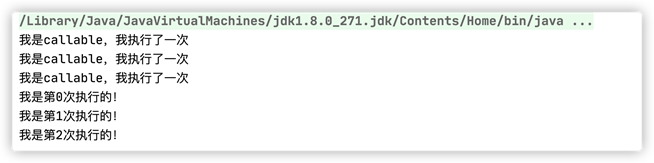
|
其中,count 使用volatile 修饰了一下,关于volatile 关键字,之后会再次讲到,这里先不说。 |
当然了,我们一般情况下,都会使用线程池来进行Callable的调用,如下代码所示。
1 public class DemoThreadDemoCallablePool { 2 public static void main(String[] args) { 3 ExecutorService threadPool = Executors.newSingleThreadExecutor(); 4 Future<Integer> future = threadPool.submit(new DemoThreadDemoCallable()); 5 try { 6 System.out.println(future.get()); 7 } catch (Exception e) { 8 System.err.print(e.getMessage()); 9 } finally { 10 threadPool.shutdown(); 11 } 12 } 13 }
- Callable和Runnable的区别
最后,我们来看看Callable和Runnable的区别:
- Callable规定的方法是call(),而Runnable规定的方法是run()
- Callable的任务执行后可返回值,而Runnable的任务是不能返回值的(运行Callable任务可拿到一个Future对象, Future表示异步计算的结果)
- call()方法可抛出异常,而run()方法是不能抛出异常的
【三种创建线程的基础方式图示】
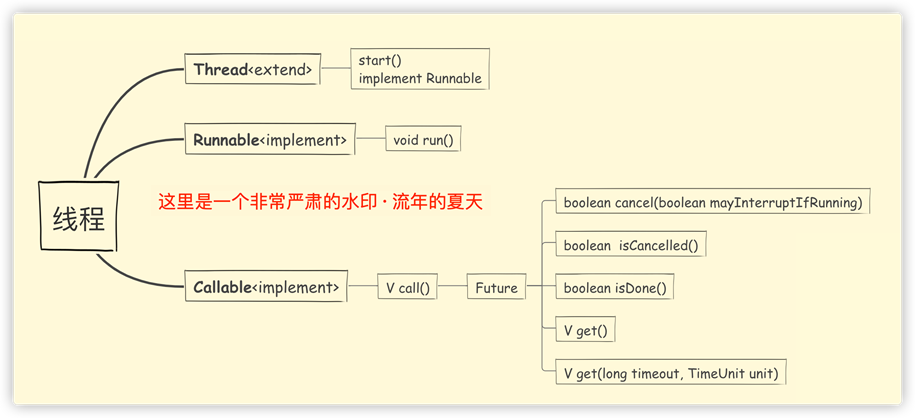
通过图示基本上可以看得很清楚,Callable是需要Future接口的实现类搭配使用的;
Future接口一共有5个方法:
-
- boolean cancel(boolean mayInterruptIfRunning)
用于取消任务,如果取消任务成功则返回true,如果取消任务失败则返回false。
参数mayInterruptIfRunning表示是否允许取消正在执行却没有执行完毕的任务,如果设置true,则表示可以取消正在执行过程中的任务。
如果任务已经完成,此方法返回false,即取消已经完成的任务会返回false;
如果任务正在执行,若mayInterruptIfRunning设置为true,则返回true,若mayInterruptIfRunning设置为false,则返回false;
如果任务还没有执行,则无论mayInterruptIfRunning为true还是false,肯定返回true。
-
- boolean isCancelled()
如果在Callable任务正常完成前被取消,返回True
-
- boolean isDone()
若Callable任务完成,返回True
-
- V get() throws InterruptedException, ExecutionException
返回Callable里call()方法的返回值,调用这个方法会导致程序阻塞,必须等到子线程结束后才会得到返回值
-
- V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException
用来获取执行结果,如果在指定时间内,还没获取到结果,就直接返回null
事实上,FutureTask是Future接口唯一一个实现类。(只看了1.7和1.8,后面的版本没有check)
【JVM线程模型】
在上一节的时候我们讲了线程的生命周期和状态,其实每一个线程,从创建到销毁,都占用了大量的CPU和内存,但是真正执行任务锁占用的资源可能并没有很多,可能只能占用到里面很少的一部分。
在java里面,使用线程执行异步任务的时候,如果每次都创建一个新的线程,那么系统资源会大量被占用,服务器会一直处于超高负荷的运算,最终很容易就会造成系统崩溃。
从jdk1.5开始,java将工作单元和执行机制分离,工作单元主要包括Runnable和Callable,执行机制就是Executor框架。
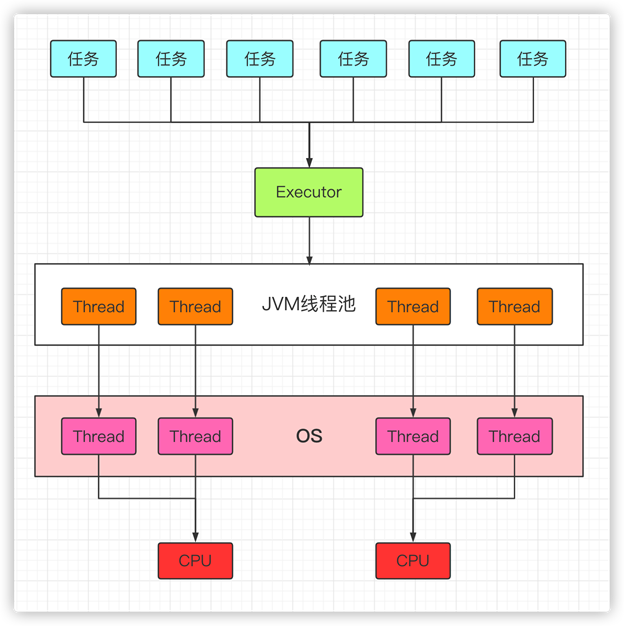
在HotSpot VM的线程模型中,Java线程会被一对一的映射成本地操作系统线程。(Java线程创建的时候,操作系统里面会对应创建一个线程,Java线程被销毁,操作系统中的线程也被销毁)
在应用层,Java多线程程序会将整个应用分解成多个任务,然后运行的时候,会使用Executor将这些任务分配给固定的一些线程去分别执行,而底层操作系统内核会将这些线程映射到硬件处理器上,调用CPU进行执行。
类似下图:
【Executor框架】
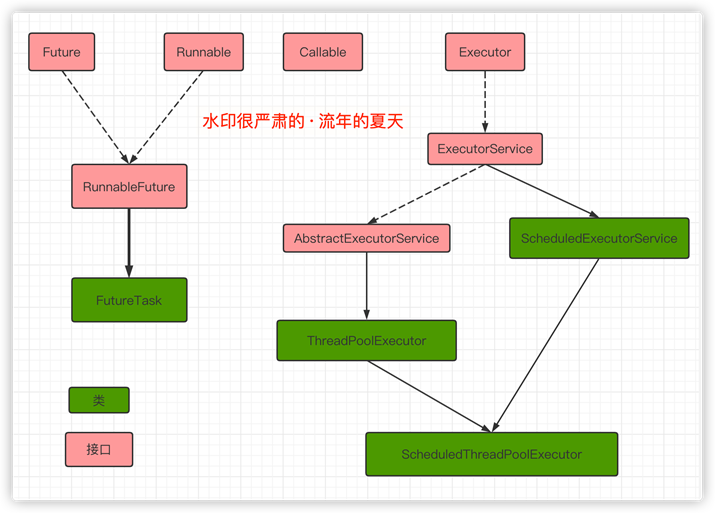
以上,是Executor框架结构图解。
Executor框架包括3大部分:
-
- 任务
也就是工作单元,包括被执行任务需要实现的接口(Runnable/Callable)
-
- 任务的执行
把任务分派给多个线程的执行机制,包括Executor接口及继承自Executor接口的ExecutorService接口。
-
- 异步计算的结果
包括Future接口及实现了Future接口的FutureTask类。
-
- Executor
Executor框架的基础,将任务的提交和执行分离开。
-
- TreadPoolExecutor
线程池的核心实现类,用来执行被提交的任务。
通常使用Executors创建,一共有三种类型的ThreadPoolExecutor:
-
-
- SingleThreadExecutor(单线程)
- FixedThreadPool(限制当前线程数量)
- CachedThreadPool(大小无界的线程池)
-
-
- ScheduledThreadPoolExecutor
实现类,可以在一个给定的延迟时间后,运行命令,或者定期执行。
通常也是由Executor创建,一共有两种类型的ScheduledThreadPoolExecutor。
-
-
- ScheduledThreadPoolExecutor(包含多个线程,周期性执行)
- SingleThreadScheduledExecutor(只包含一个线程)
-
-
- Future
异步计算的结果。
这里在很多时候返回的是一个FutureTask的对象,但是并不是必须是FutureTask,只要是Future的实现类即可。
【TreadPoolExecutor】
之前已经说过,TreadPoolExecutor是线程池的核心实现类,所有线程池的底层实现都依靠它的构造函数:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
我们可以依次解释一下:
- corePoolSize
核心线程数,也叫常驻线程数,线程池里从创建之后会一直存在的线程数量。
- maximumPoolSize
最大线程数,线程池中最多存在的线程数量。
- keepAliveTime
空闲线程的存活时间,一个线程执行完任务之后,等待多久会被线程池回收。
- unit
keepAliveTime参数的单位
- workQueue
线程队列(一般为阻塞队列)
- threadFactory
线程工厂,用于创建线程
- handler
拒绝策略,由于达到线程边界和队列容量而阻止执行时使用的处理程序。
其实,线程池不能算作一种创建线程的方式,为什么呢?
|
对于线程池而言,本质上是通过线程工厂创建线程的。 默认采用 DefaultThreadFactory ,它会给线程池创建的线程设置一些默认值,比如:线程的名字、是否是守护线程,以及线程的优先级等。
|
关于线程池的详细概念内容,可先参考我的另外一篇博客:线程池略略观,后面也会再说。
关于线程的主要创建方式,大概就是以上这些,下一篇,会讲线程的基本属性和主要方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号