LinkedHashMap实现LRUCache
前言:
在学习 LRU 算法的时候,看到 LruCache 源码实现是基于 LinkedHashMap,今天学习一下 LinkedHashMap 的好处以及如何实现 lru 缓存机制的。
需求背景:
LRU 这个算法就是把最近一次使用时间离现在时间最远的数据删除掉,而实现 LruCache 将会频繁的执行插入、删除等操作,我们就会想到使用 LinkedList,但是我们又要基于 Key-Value 来保存数据,这个时候我们就会想起 HashMap,但是 HashMap 不能像 linkedList 那样保留数据的插入顺序,如果要使用 HashMap 的话可以使用它的一个子类 LinkedHashMap。
LinkedHashMap 介绍:
LinkedHashMap 是 Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变, LinkedHashMap 实现与 HashMap 的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序 (调用 get 方法) 的链表。默认是按插入顺序排序,如果指定按访问顺序排序,那么调用 get 方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。 可以重写 removeEldestEntry 方法返回 true 值指定插入元素时移除最老的元素。更多关于 LinkedHashMap 的知识介绍请查看这篇博客,博客地址:http://www.cnblogs.com/children/archive/2012/10/02/2710624.html
LinkedHashMap 使用:
因为我们这里为了实现 LRU 算法,排序方式 设置为 true 访问顺序排序
int initialCapacity = 10;//初始化容量
float loadFactor = 0.75f;//加载因子,一般是 0.75f
boolean accessOrder = true;//排序方式 false 基于插入顺序 true 基于访问顺序
Map<String, Integer> map = new LinkedHashMap<>(initialCapacity, loadFactor, accessOrder);
具体看下效果:
for (int i = 0; i < 10; i++) {
map.put(String.valueOf(i), i);
}
//访问前顺序
for (Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator(); it.hasNext(); ) {
Map.Entry<String, Integer> next = it.next();
Log.e(TAG, "linkedMap--before-->" + next.getKey());
}
//模拟访问
map.get("5");
//访问后数据
for (Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator(); it.hasNext(); ) {
Map.Entry<String, Integer> next = it.next();
Log.e(TAG, "linkedMap--after-->" + next.getKey());
}
}

运行结果发现访问过的 5 未知发生了变化 说明是基于访问排序的。我们接下来再看下如何移除过期的。
final int initialCapacity = 10;//初始化容量
float loadFactor = 0.75f;//加载因子,一般是 0.75f
boolean accessOrder = true;//排序方式 false 基于插入顺序 true 基于访问顺序
//Map<String, Integer> map = new LinkedHashMap<>(initialCapacity, loadFactor, accessOrder);
Map<String, Integer> map = new LinkedHashMap(initialCapacity, loadFactor, accessOrder) {
@Override
protected boolean removeEldestEntry(Entry eldest) {
return size() > initialCapacity;
}
};
for (int i = 0; i < 15; i++) {
map.put(String.valueOf(i), i);
}
//访问前顺序
for (Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator(); it.hasNext(); ) {
Map.Entry<String, Integer> next = it.next();
Log.e(TAG, "linkedMap--before-->" + next.getKey());
}
我们容量定的 10 个,我们插入 15 个 我们发现最先插入的五个不见了,说明 LRU 算法起到效果了。
手写一个 LRU 算法
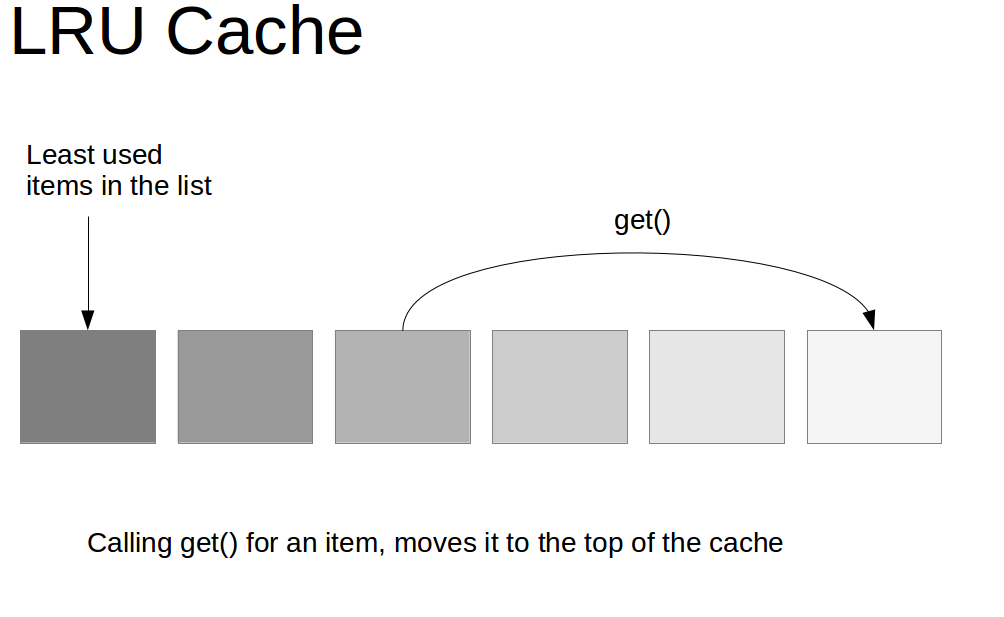
LRU 就是 Least Recently Used 的缩写,翻译过来就是“最近最少使用”。也就是说 LRU 算法会将最近最少用的缓存移除,让给最新使用的缓存。而往往最常读取的,也就是读取次数最多的,所以利用好 LRU 算法,我们能够提供对热点数据的缓存效率,能够提高缓存服务的内存使用率。
那么如何实现呢?
其实,实现的思路非常简单,就像下面这张图种描述的一样。
你可以现场手写最原始的 LRU 算法,那个代码量太大了,似乎不太现实。
不求自己纯手工从底层开始打造出自己的 LRU,但是起码要知道如何利用已有的 JDK 数据结构实现一个 Java 版的 LRU。
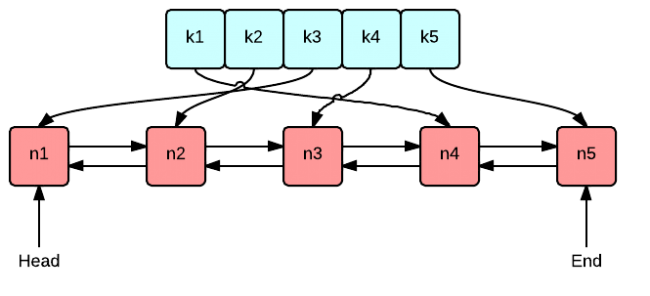
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private int capacity;
/**
* 传递进来最多能缓存多少数据
*
* @param capacity 缓存大小
*/
public LRUCache(int capacity) {
// 这里的true
// 排序方式 false 基于插入顺序 true 基于访问顺序
super(capacity, 0.75f, true);
this.capacity = capacity;
}
/**
* 如果map中的数据量大于设定的最大容量,返回true,再新加入对象时删除最老的数据
*
* @param eldest 最老的数据项
* @return true则移除最老的数据
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当 map中的数据量大于指定的缓存个数的时候,自动移除最老的数据
return size() > capacity;
}
}Copy to clipboardErrorCopied
参考文献:https://doocs.github.io/advanced-java/#/./docs/high-concurrency/redis-expiration-policies-and-lru

 浙公网安备 33010602011771号
浙公网安备 33010602011771号