用python读文件如.c文件生成excel文件
记录一下,如何实现的,代码如下:

#!/usr/bin/env python # coding=utf-8 # 打开文件 import xlwt import re import sys bookfile = xlwt.Workbook(encoding='utf-8') table = bookfile.add_sheet('data',cell_overwrite_ok=True) table_head = ['日志路径', '触发条件','级别','内容'] for i in range(len(table_head)): table.write(0, i, table_head[i]) file = open(sys.argv[1]) row = 1 while True: # 读取一行内容 text = file.readline() #searchObj = re.search( r'[a-zA-Z0-9]*\.log', text, re.M|re.I) pattern = re.compile(r'[a-zA-Z0-9]*\.log') # 查找数字 searchObj = pattern.findall(text) #str1 = searchObj.group() if searchObj: #print (searchObj) str = [["/home/spv/log/",sys.argv[2],sys.argv[3],sys.argv[4]]] str[0][0] += searchObj[0] print("str:%s" % str[0][0]) for col in range(0,4): table.write( row, col, str[0][col] ) bookfile.save("data.xls") row += 1 # 判断是否读到内容 if not text: break # 每读取一行的末尾已经有了一个 `\n` #print(text, end="") #print(text) # 关闭文件 file.close()
其实,但生成的excel很不规范,因为有些数据没法统计,生成excel后,需要手动修改,一般用的多的地方是:xml和excel的相互转换,命令如下:python3 ldw.py itsmwn.c 查询 debug 工单,其实跟C语言的命令行参数一样,都从0开始,
sys.argv[0]是ldw.py,
sys.argv[1]是itsmwn.c,要读取的文件名
查询 debug 工单分别对应生成的excel的第二、三和四列的内容
运行结果如下:
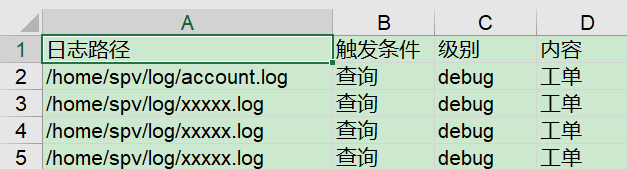
主要还是统计日志路径,后面三列还是需要根据代码内容进行修改
作者:逆袭之路
-------------------------------------------
个性签名:独学而无友,则孤陋而寡闻。做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!
标签:
python



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端