Python测试之道——笔记1
引言
如果利用python做自动化测试的话,一些python相关的基础知识是必须要掌握的。常用的比如:python代码规范、变量与数据类型、运算、函数和字符串处理等。
语法规范
这里只介绍重点和常用的一些注意事项。
在使用python编码的时候,我们应该严格按照pep8的规范来要求自己,这样不仅仅提高代码的可读性,同时也提高了自己编码的整体水平。

重点关注:
1. python不像java一样,代码以分号结束,python一条命令一行代码,没有分号。
2.每行的长度不超过80个字符。这里是除导入较长的模块和注释里的内容。
3.python的隐式连接是使用()、[]和{}。 切记不要使用反斜杠来连接行。
不推荐这种:
a = "这是一个超长的字符串" \
"这是一个很长的字符串"
print(a)
我们使用这种:
b = ("这是一个超长的字符串"
"这是一个很长的字符串")
print(b)
4.使用4个空格作为缩进代码,不要使用tab键。
5.类与方法之间需要空一行,定级定义之间空两行,其他保持一行就可以了。
6.括号内不要有空格。
7.如果一个类不继承其他的类,就显示的从object继承,嵌套也一样。
推荐使用:
class TestClass01(object):
pass
不要使用这种:
class TestClass01:
pass
8.字符串合并使用+,不要使用%s%s,字符串打印使用format格式化,不要使用+
如:
# 推荐
a = "a" + "b"
b = "{},{}".format(1,2)
c = "key1: %s, key2: %d"%("aa",2)
d = "key1: {}, key2: {}".format("python",1)
print(a)
print(b)
print(c)
print(d)
# 不推荐
a = "%s%s" % ("a","b")
b = "{}{}".format(1,2)
c = "key1: aa" + ", " + "key2: 2"
d = "key1: " + "python" + ", " + "key2: " + str(1)
print(a)
print(b)
print(c)
print(d)
执行结果:
ab 1,2 key1: aa, key2: 2 key1: python, key2: 1 ab 12 key1: aa, key2: 2 key1: python, key2: 1 Process finished with exit code 0
9.导入的格式,每个导入应该单独占一行,
# 推荐 import os import sys # 不推荐 import os,sys
10. 块注释和行注释,使用#号来注释。
语法规范总结:
规范有很多,平时使用注意以下几点就行:
1、换行和缩进
2、模块导入
3、注释
更多了解,可以参考官方文档:https://www.python.org/dev/peps/pep-0008/
变量与变量类型
变量定义:大家知道程序是用来处理数据的,而变量是用来存储数据的。python中变量不需要声明类型,可以存储任何值,每个变量在内存中被创建,
变量赋值以后该变量才会被创建。基于变量的数据类型,解释器会分配指定内存,并决定什么数据可以被存储在内存中。
等号(=)用来给变量赋值。
python五种标准的数据类型:
1、Numbers(数字)
2、String(字符串)
3、List(列表)
4、Tuple(元组)
5、Dictionary(字典)
6、Set(集合)
Python3 的六个标准数据类型中:
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
Python 数字
当指定一个值(数字),数字对象就被创建:
var = 1 print(var)
python有四种不同的数字类型:
int(有符号整型) long(长整型[也可以代表八进制和十六进制]) float(浮点型) complex(复数)
Python字符串
字符串转换
# 字符转换
str(x) # x为任意数据类型
# 字符串合并
a = 123
b = "123"
print(str(a) + b)
# 字符串截取
a = "a=abc,b=123,abcd,(1,2,3)"
print(a.split(','))
print(a.split(',', 2))
print(a.split(',')[1].split('=')[1])
#字符串替换
a = "a=abc,b=123,abcd,(1,2,3)"
print(a.replace(',', ':'))
print(a.replace(',', ':', 2))
print(a.replace(',', ':', 3))
b = a.replace(',', ':', 3)
print(b)
Python 列表
List(列表)是python中使用最频繁的数据类型
列表可以完成大多数集合类的数据结构实现,它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
列表用 [ ] 标识,是 python 最通用的复合数据类型。列表中值的切割也可以用到变量 [头下标:尾下标]
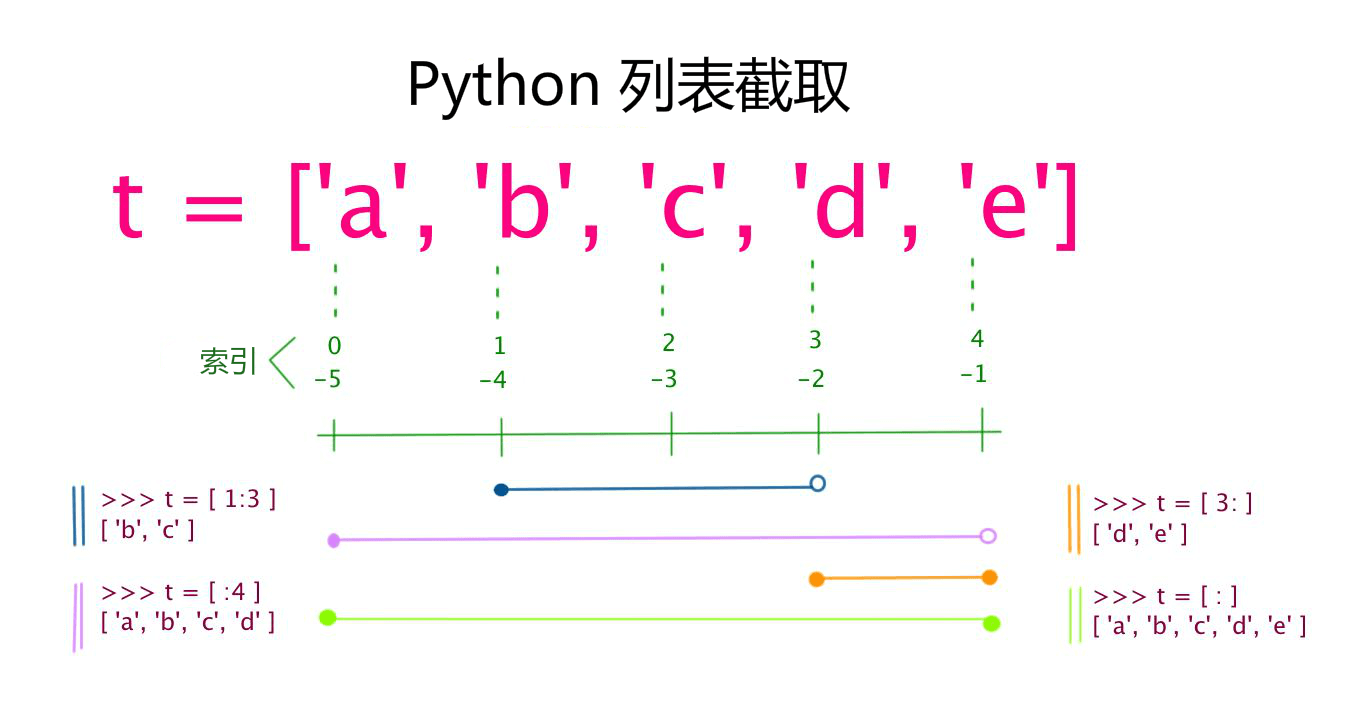
一个完整的切片表达式包含两个“:”,用于分隔三个参数(start_index、end_index、step)。当只有一个“:”时,默认第三个参数step=1;当一个“:”也没有时,start_index=end_index,表示切取start_index指定的那个元素。
切片操作基本表达式:object[start_index:end_index:step]
step:正负数均可,其绝对值大小决定了切取数据时的‘‘步长”,而正负号决定了“切取方向”,正表示“从左往右”取值,负表示“从右往左”取值。当step省略时,默认为1,即从左往右以步长1取值。“切取方向非常重要!”“切取方向非常重要!”“切取方向非常重要!”,重要的事情说三遍!
start_index:表示起始索引(包含该索引对应值);该参数省略时,表示从对象“端点”开始取值,至于是从“起点”还是从“终点”开始,则由step参数的正负决定,step为正从“起点”开始,为负从“终点”开始。
end_index:表示终止索引(不包含该索引对应值);该参数省略时,表示一直取到数据“端点”,至于是到“起点”还是到“终点”,同样由step参数的正负决定,step为正时直到“终点”,为负时直到“起点”
"""列表"""
a = [1,2,"python",(3,"aa")]
# 删除
a.remove("python")
print(a)
# 新增
a.append(4)
print(a)
a.insert(1,"java")
print(a)
# 修改
a[2] = "python"
print(a)
# 合并
b = [5,6,7]
a.extend(b)
print(a)
b = b + a
print(b)
Python 元组
元组不可修改,使用小括号()存储数据,元素之间使用逗号分隔。
a = (1, "a", (3, "python")) print(a[0]) print(a[1]) print(a[2]) print(a[-1]) print(a[2][-1]) print(a[-1][0]) print(a[1:-1])
Python 字典
列表是有序集合,而字典是无序集合。两者区别,字典表现形式是{},并且通过键来存取的,而列表是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。
"""字典"""
a = {'a':1,'b':2,'c':3}
print(a)
# 删除
del(a['a'])
print(a)
b = {'a':4,'d':5}
# 更新
a.update(b)
print(a)
Python 集合
使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
# 集合
test = {1,2,3,"python","java","python"}
# 输出元素,重复的自动去掉
print(test)
# 增加元素
test.add("php")
print(test)
# 增加多个
test.update([4,5,6])
print(test)
# 删除元素
test.remove(6)
print(test)
a = set('abc')
b = set('abcde')
print(a)
print(a - b) # 差集
print(b - a)
print(a | b) # 并集
print(a & b) # 交集
print(a ^ b) # a与b不同时存在的元素
# 成员关系判断
member = {"python","php","java","c#"}
if "python" in member:
print("python在集合中")
else:
print("不在集合中")
运算符
自动化测试中,经常使用运算符,对数据进行处理。
python中运算符主要有:
1、算术运算符
2、比较(关系)运算符
3、赋值运算符
4、逻辑运算符
5、位运算符
6、成员运算符
7、身份运算符
经常使用的是赋值、算术,比较这三种,当然在断言的时候,会使用成员运算符。判断两个变量是否是相同的标识(id),可以使用身份运算符。
当然,条件判断的时候,还会使用逻辑运算符。
# and和or 左右两边不一定是布尔类型,有可能是表达式,and左边为真时,才会去算右边的值,or左边为真时,就不会去算右边的值,not右边值为假才会返回真。
# 0为False , 1为True
a = 1
b = 2
c = 0
print(a and b)
print(a or b)
print(not a)
print(bool(a))
print(a and c)
print(bool(c))
print(c or b)
print(a and b and c)
if a > 0 and b:
print(a)
字符串
python使用时,字符串是非常频繁的一个数据类型。
创建方式:使用''或"",即可。
访问方式:通过[]来截取。
# 字符串合并
a = 123
b = "123"
print(str(a) + b)
# 字符串截取
a = "a=abc,b=123,abcd,(1,2,3)"
print(a.split(','))
print(a.split(',', 2))
print(a.split(',')[1].split('=')[1])
# 字符串替换
a = "a=abc,b=123,abcd,(1,2,3)"
print(a.replace(',', ':'))
print(a.replace(',', ':', 2))
print(a.replace(',', ':', 3))
b = a.replace(',', ':', 3)
print(b)
# 访问
a = "adfa_2323"
print(a[:-2])
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符,使用最频繁的是:
# 续行符
print("test \
test")
# 反斜杠
print("\\")
# 换行
print("test\ntest")
# 响铃
print("\a")
# 单引号
print('\'')
# 双引号
print("\"")
字符串前面使用r,是显示原始字符串,不是转义
字符串前面使用u,一般是中文使用u,进行unicode编码时,防止中文乱码。
字符串前面使用b,是bytes字节串类型。
a = u"中国"
print(a)
b = r"fadfa\\"
print(b)
c = bytes("中国",encoding='utf8')
print(c)
d = c.decode()
print(d)
输出结果:
中国 fadfa\\ b'\xe4\xb8\xad\xe5\x9b\xbd' 中国
在Python3中,所有的字符串都是Unicode字符串(16位)。
函数
1、函数的定义:什么是函数呢?
其实函数就是一段代码的集合,里面是有很多方法和内容,可以重复调用的。主要是内置函数和自定义函数。
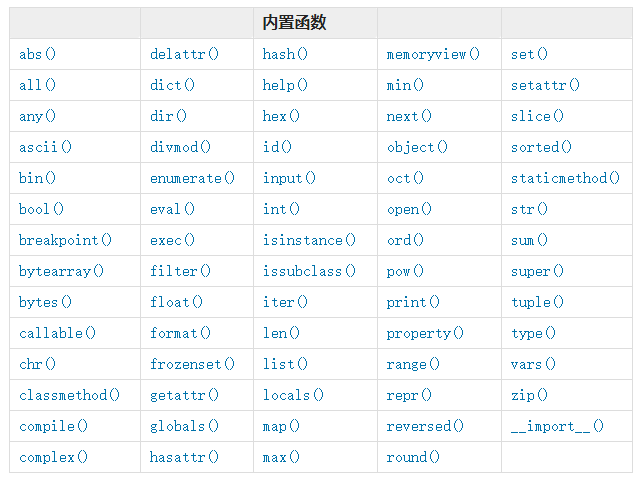
平时我们使用print,其实就是python的内置函数。
python主要的内置函数如下:
2、函数的返回值。
这主要是我们自己定义的函数,如:
#!/usr/bin/python3
# 可写函数说明
def sum( arg1, arg2 ):
# 返回2个参数的和."
total = arg1 + arg2
print ("函数内 : ", total)
return total
# 调用sum函数
total = sum( 10, 20 )
print ("函数外 : ", total)
3、函数的参数。
主要分为四种:位置参数,默认参数,不定长参数(可变和关键字参数)
位置参数:
调用函数时,传入实参的值按照位置顺序以此赋给形参。下面这个函数中的x和n就是位置参数。
def power(x, n):
s = 1
while( n ):
n = n - 1
s = s * x
return s
默认参数:
python的函数同时还允许你给函数的参数设置默认值,当调用者没有给出参数的值时自动使用默认值。设置默认参数时要注意,必选参数必须在默认参数之前。
def power(x, n = 2):
s = 1
while( n ):
n = n - 1
s = s * x
return s
注意:默认参数必须指向不可变对象,否则会发生不可预知的错误。
可变参数:
在Python函数中还可以定义可变的参数,参数的个数可以是任意个,定义参数时,只需要在参数的前面加一个 * 符号即可。
def N(×num):
s = 1
for n in num:
s = s * n
return s
A = N(1,2,3,4,5,6,7,8,9,10) #A = 3628800
关键字参数(keyword argument):
python的关键字参数允许你传入任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。传入关键字参数的时候必须指定参数的名称(参数名由调用者自行取定),否则该参数会被认为是位置参数从而报错。
def keyword_params(**kwargs):
return kwargs
keyword_params(key1="values1",key2="values2")
可变和关键字参数混搭:
def test_fuc(*args,**kwargs):
print(args,111)
print(kwargs,222)
test_fuc(1,2,3,key1="values")
注意事项:
*args与**kwargs的区别,两者都是python中的可变参数。 *args表示任何多个无名参数,它本质是一个tuple; **kwargs表示关键字参数,它本质上是一个dict; 如果同时使用*args和**kwargs时,必须*args参数列要在**kwargs前。
在这个场景下使用这两个关键字。其实并不是必须写成*args 和**kwargs。 *(星号)才是必须的. 你也可以写成*ar 和**k. 而写成*args 和**kwargs只是一个通俗的命名约定。
关键字和位置参数混搭:
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
preson("J",33,city = "Beaijing",job = "Engineer")
4、函数嵌套
在函数中再定义一个函数,就叫做嵌套函数。嵌套函数可以访问包围范围内的变量。
如图:
def add_test(a,b):
c = a + b
def ride_test(x):
x = x*x
print(c)
return x
return ride_test(c)
print(add_test(1, 2))
这里嵌套会涉及一个闭包概念,闭包就是把内部函数作为一个变量来使用。
我们可以将闭包理解为一种特殊的函数,这种函数由两个函数的嵌套组成,且称之为外函数和内函数,外函数返回值是内函数的引用,此时就构成了闭包。
格式如下:
def 外层函数(参数):
def 内层函数():
print("内层函数执行", 参数)
return 内层函数
内层函数的引用 = 外层函数("传入参数")
内层函数的引用()
简单的一个闭包案例:
def outter(x):
def inner(y):
return x + y
return inner
test = outter(2)
print(test(3))
闭包也叫工厂函数,它的作用如下:
a:记忆外层作用域中的值;
b:可以保护变量不被修改;
c:可以让一个变量常驻内存;
内函数中修改外函数的值:
def outter(x):
a = 100
def inner(y):
nonlocal a
a = 200
return x + y + a
return inner
test = outter(2)
print(test(3))
这个结果是205,而不是105。
一般在函数结束时,会释放临时变量,但在闭包中,由于外函数的临时变量在内函数中用到,此时外函数会把临时变量与内函数绑定到一起,这样虽然外函数结束了,但调用内函数时依旧能够使用临时变量,即闭包外层的参数可以在内存中进行保留
如果想要在内函数中修改外函数的值,需要使用 nonlocal 关键字声明变量。
在看一个典型的装饰器原型:
import time
def showtime(func):
def wrapper(x):
s_time = time.time()
func()
e_time = time.time()
print('speed is {}'.format(e_time - s_time))
return x
return wrapper
def wait():
print('waiting...')
time.sleep(3)
foo = showtime(wait)
print(foo(3))
运行结果:
waiting... speed is 3.000234603881836 3
总结
有兴趣加入测试交流群,欢迎测开爱好者加入我们~
作者:全栈测试开发日记
出处:https://www.cnblogs.com/liudinglong/
csdn:https://blog.csdn.net/liudinglong1989/
微信公众号:全栈测试开发日记
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号