Selenium Web自动化测试——基于unittest框架的PO设计模式
引言
前面一直在讲接口自动化测试框架与案例分享,很少讲Selenium这个Web自动化测试神器。它主要用来做UI自动化测试,大家都知道UI自动化测试成本相当高,一般的Web自动化测试我是一直不建议做的。
虽然不推荐,但是这里有一个设计思想是不错的——PO设计模式。
PO设计模式
PO设计模式,英文名称:Page Object Model。PO设计模式是Selenium自动化测试中最佳的设计方式之一。相比传统设计中:页面定位元素→输入数据→操作元素→断言结果,会有以下问题:
1、易用性差:杂乱无章的定位元素方法,例如:find_element;
2、扩展性不好:用例孤立,无法扩展;
3、复用性差:无公共方法,很难服用;
4、可维护性差:一旦元素变化或测试步骤变化,需要维护大量代码和用例;
针对上面一些弊端,做了一些优化:
POM设计模式,将页面定位和业务操作分开,将元素定位和测试方法分离,从而提高代码的维护性。而传统的POM是元素定位和测试方法放在一起,如下图:
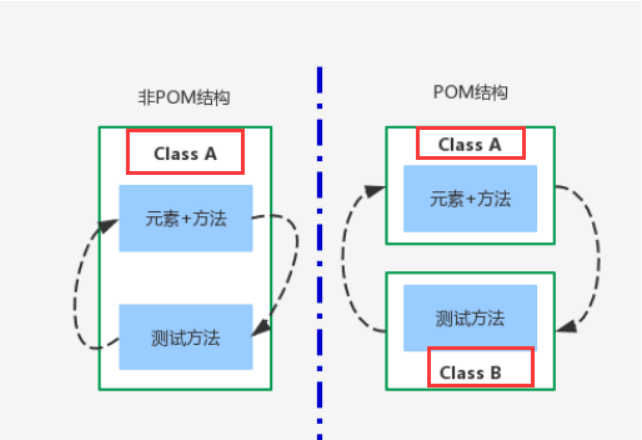
这样做的优势:
1、页面元素定位和业务操作方法分离,使得代码更加清晰,减少冗余代码;
2、测试方法单独抽离,这样提高用例的可读性;
3、针对ui变化频繁的项目和测试步骤的变化,提高了测试用例的维护性;
一条测试用例可能需要多个步骤操作元素,将每一个步骤单独封装成一个方法,在执行测试用例时调用封装好的方法进行操作。PO模式可以把一个页面分为三个层级,对象库层、操作层、业务层。
PO设计模式核心组件
画一个操作如下:
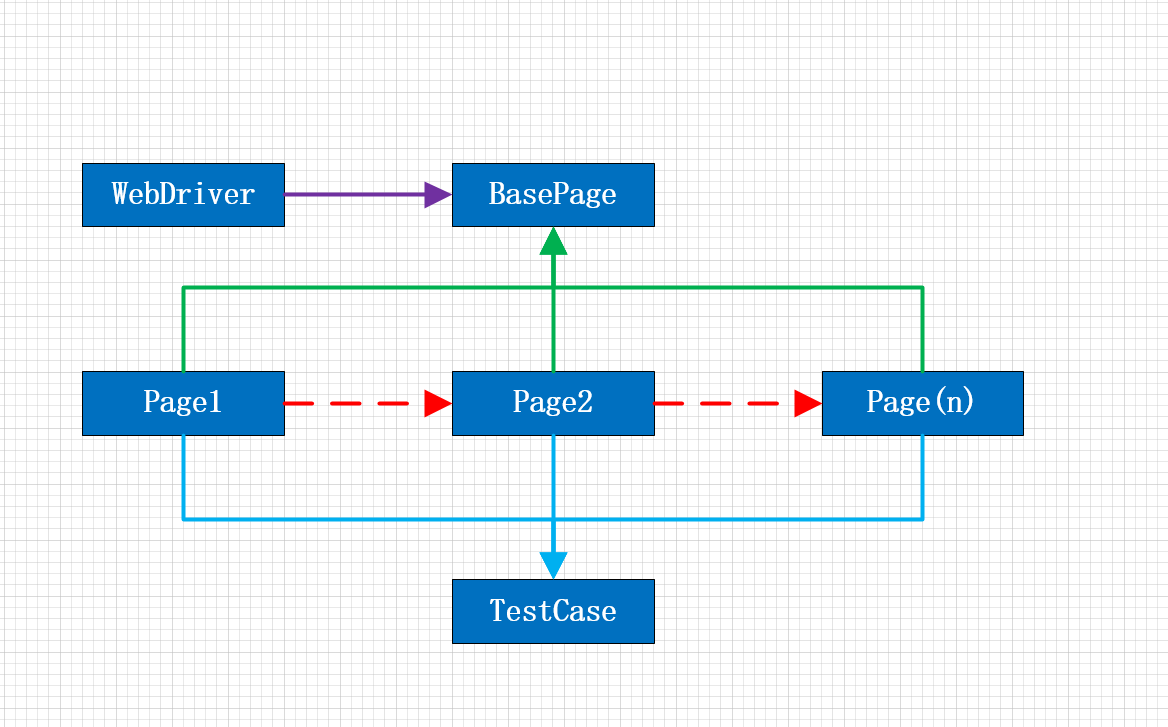
PO的核心要素:
在 PO 模式中抽离封装集成一个 BasePage 类,该基类应该拥有一个只实现 webdriver 实例的属性
每一个page 都继承BasePage,通过 driver 来管理 page 中元素,将 page 中的操作封装成一个个方法
TestCase 继承 unittest.TestCase类,并依赖page类,从而实现相应的测试步骤
首先抽象封装一个BasePage类,这个基类拥有Webdriver实例的属性,将页面分成一个个Page,每一个Page继承基类BasePage,可以通过driver来管理每一个Page中的元素,
在Page中将定位元素的操作封装成一个一个方法。TestCase继承unittest里面的TestCase类,并且依赖Page类,进行测试步骤的执行工作。
这样以来,页面元素一旦变化,只需要维护每一个Page中的方法,测试流程发生变化,只需要维护TestCase即可。
核心组件:
BasePage.py模块:
1 2 3 4 5 | class BasePage(object): def __init__(self,driver): self.driver = driver pass |
Page页面模块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | from SeleniumProject.PO.BasePage import BasePageclass LoginBase(BasePage): # 定位元素,括号中是通过find_element来获取元素的属性 uname = () pwd = () def set_uname(self,uname): name =self.driver.find_element(*LoginBase.uname) name.send_keys("用户名") def set_pwd(self,pwd): password = self.driver.find_element(*LoginBase.pwd) password.send_keys("密码") pass |
TestCase用例模块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | from unittest import TestCaseimport unittestfrom selenium import webdriverclass Test_Login(TestCase): def setUp(self): self.driver = webdriver.Chrome() self.driver.get("https://cn.bing.com/") # 测试步骤 def test_Login(self): self.driver.get(self.base_url) pass def tearDown(self): self.driver.quit()if __name__ == "__main__": unittest.main() |
PO模式简单实例
现在根据PO设计模式思想,简单实现一个需求:
打开浏览器,输入url:https://www.baidu.com,在百度搜索文本框内输入关键字:selenium,然后单击:百度一下,进行搜索。
根据需求,设计步骤如下:
BasePage:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | #!/usr/bin/env python# -*- coding: utf-8 -*-'''# @Time : 2020/11/22 0022 16:07# @Author : liudinglong# @File : basepage.py# @Description: # @Question: '''from selenium import webdriverfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECclass BasePage(object): def __init__(self,driver,url): """ @param driver: @param base_url: """ self.dr = driver self.base_url = url # 定义私有方法,类对象和子类可以访问 def _open(self,url): self.dr.get(url) self.dr.maximize_window() # 定义open方法,调用_open方法 def open(self): self._open(self.base_url) def find_emelemt(self,*loc): try: WebDriverWait(self.dr,10).until(EC.visibility_of_all_elements_located(loc)) return self.dr.find_element(*loc) except: print("页面中没有%s元素"%(self.loc)) # 定义script()方法,用于执行JS脚本,比方上上传文件啥的 def script(self, src): self.dr.excute_script(src) # 定义页面跳转方法,比方说有的页面有frame嵌套 def switch_frame(self, loc): return self.dr.switch_to_frame(loc) # 重新定义send_keys()方法,为了保证搜索按钮是否存在,还有有的输入框中默认有值,要清空 def send_keys(self, loc, value, clear_first=True, click_first=True): try: # getattr方法相当于实现了self.loc loc = getattr(self, "_%s" % loc) # 是否存在搜索按钮 if click_first: self.find_emelemt(*loc).click() # 清空搜索框中的值,并输入需要搜索的值 if clear_first: self.find_emelemt(*loc).clear() self.find_emelemt(*loc).send_keys(value) except: print("页面上未找到%s元素" % (self.loc)) |
SearchPage:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #!/usr/bin/env python# -*- coding: utf-8 -*-'''# @Time : 2020/11/22 0022 18:38# @Author : liudinglong# @File : SearchPage.py# @Description: # @Question: '''from selenium.webdriver.common.by import Byfrom Common.basepage import BasePageclass SearchPage(BasePage): # 定位元素 search_loc = (By.ID,"kw") #搜索框 btn_loc = (By.ID,"su") #搜索按钮 # 重写父类的open()方法 def open(self): self._open(self.base_url) def search_content(self,content): # 调用父类的find_emelemt,然后将本类的参数传入 content1 = self.find_emelemt(*self.search_loc) content1.send_keys(content) def btn_click(self): btn1 = self.find_emelemt(*self.btn_loc) btn1.click() |
TestCase:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | #!/usr/bin/env python# -*- coding: utf-8 -*-'''# @Time : 2020/11/22 0022 18:40# @Author : liudinglong# @File : test_001.py# @Description: # @Question: '''from unittest import TestCaseimport unittestfrom selenium import webdriverfrom time import sleepfrom Page.searchpage import SearchPageclass CaseRun(TestCase): def setUp(self): self.driver = webdriver.Chrome() self.url = "https://www.baidu.com" sleep(3) self.content = "selenium" # 测试步骤 def test_search(self): bing_page = SearchPage(self.driver,self.url) bing_page.open() bing_page.search_content(self.content) try: bing_page.btn_click() sleep(3) print("查询成功") except Exception as Error: print(Error) def tearDown(self): self.driver.quit()if __name__ == "__main__": unittest.main() |
三个核心组件完成,项目结构如下:
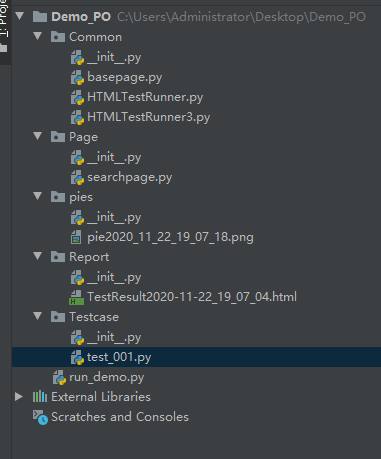
运行测试,生成报告如下:
1 2 3 4 5 6 | C:\Users\Administrator\Desktop\Demo_POC:\Users\Administrator\Desktop\Demo_PO\Report.Time Elapsed: 0:00:13.370322Process finished with exit code 0 |

总结
这个Demo很简单,主要意图是帮助理解PO设计模式的思想,如果需要代码,可以加入QQ群:696400122 ,我们这里主要是进行自动化测试和测试开发学习与沟通交流,如果其他意图请绕行~
作者:全栈测试开发日记
出处:https://www.cnblogs.com/liudinglong/
csdn:https://blog.csdn.net/liudinglong1989/
微信公众号:全栈测试开发日记
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架