Python定时任务框架之Apscheduler 案例分享
引言
前面已经讲过Celery做定时任务的场景,现在分享另一个框架Apscheduler。Apscheduler的全称是Advanced Python Scheduler。它是一个轻量级的 Python 定时任务调度框架。同时,它还支持异步执行、后台执行调度任务。本人小小的建议是一般项目用APScheduler,因为不用像Celery那样再单独启动worker、beat进程,而且API也很简洁。
需求背景
前端时间双十一公司业务暴增的情况下,订单也是暴增,要在钉钉群定时播报关键的业务数据,这个时候需要一个简洁又快速出结果的方案。于是偷偷用python花了不到半个小时写了一个不到30行的脚本(包括调试),完成了领导的需求。
简介
Apscheduler的官方文档可以参考:https://apscheduler.readthedocs.io/en/latest/modules/triggers/cron.html#module-apscheduler.triggers.cron 或:https://apscheduler.readthedocs.io/en/latest/userguide.html#
Python定时任务框架APScheduler,Advanced Python Scheduler (APScheduler) 是一个轻量级但功能强大的进程内任务调度器,作用为在指定的时间规则执行指定的作业(时间规则:指定的日期时间、固定时间间隔以及类似Linux系统中Crontab的方式);并且该框架可以进行持久化配置,保证在项目重启或者崩溃恢复后仍然能够恢复之前的作业继续运行。
特点
1、不依赖于Linux系统的crontab系统定时,独立运行
2、可以动态添加新的定时任务,如下单后30分钟内必须支付,否则取消订单,就可以借助此工具(每下一单就要添加此订单的定时任务)
3、对添加的定时任务可以做持久保存
四大组件
触发器(triggers):触发器包含调度逻辑,描述一个任务何时被触发,按日期或按时间间隔或按 cronjob 表达式三种方式触发。每个作业都有它自己的触发器,除了初始配置之外,触发器是完全无状态的。
作业存储器(job stores):作业存储器指定了作业被存放的位置,默认情况下作业保存在内存,也可将作业保存在各种数据库中,当作业被存放在数据库中时,它会被序列化,当被重新加载时会反序列化。作业存储器充当保存、加载、更新和查找作业的中间商。在调度器之间不能共享作业存储。
执行器(executors):执行器是将指定的作业(调用函数)提交到线程池或进程池中运行,当任务完成时,执行器通知调度器触发相应的事件。
调度器(schedulers):任务调度器,属于控制角色,通过它配置作业存储器、执行器和触发器,添加、修改和删除任务。调度器协调触发器、作业存储器、执行器的运行,通常只有一个调度程序运行在应用程序中,开发人员通常不需要直接处理作业存储器、执行器或触发器,配置作业存储器和执行器是通过调度器来完成的。
重要组件说明
触发器(triggers)——目前APScheduler支持触发器:
DateTrigger IntervalTrigger CronTrigger
DateTrigger: 指定日期时间执行一次
IntervalTrigger: 固定时间间隔执行,支持每秒、每分、每时、每天、每周
CronTrigger: 类似Linux系统的Crontab定时任务
DateTrigger和IntervalTrigger很好理解,使用也比较简单,这里重点说一下CronTrigger触发器。
CronTrigger触发器的参数选项如下:
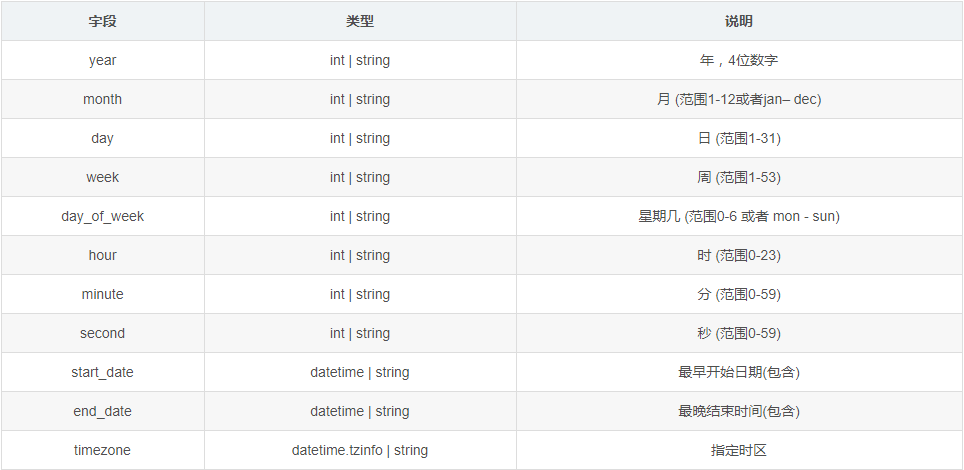
CronTrigger可用的表达式:
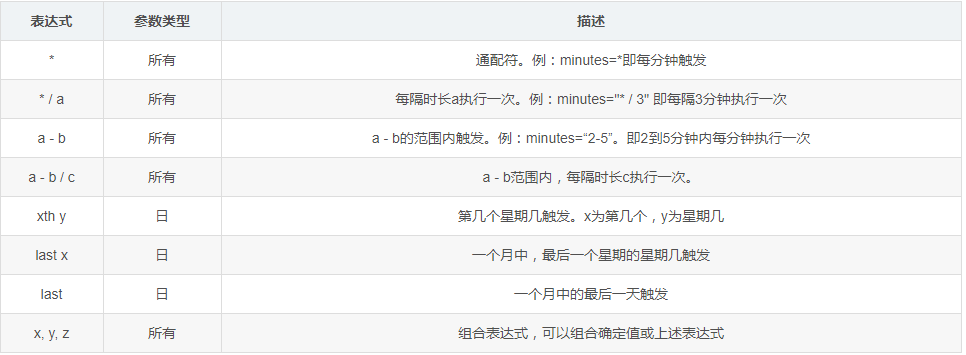
执行器(executors)——目前APScheduler支持的Executor:
AsyncIOExecutor GeventExecutor ThreadPoolExecutor ProcessPoolExecutor TornadoExecutor TwistedExecutor
作业存储器(job stores)——目前APScheduler支持的Jobstore:
MemoryJobStore MongoDBJobStore RedisJobStore RethinkDBJobStore SQLAlchemyJobStore ZooKeeperJobStore
调度器(schedulers)——目前APScheduler支持的Scheduler:
AsyncIOScheduler BackgroundScheduler --非阻塞方式 BlockingScheduler --阻塞方式 GeventScheduler QtScheduler TornadoScheduler TwistedScheduler
Job作业——Job作为APScheduler最小执行单位。创建Job时指定执行的函数,函数中所需参数,Job执行时的一些设置信息。
id:指定作业的唯一ID name:指定作业的名字 trigger:apscheduler定义的触发器,用于确定Job的执行时间,根据设置的trigger规则,计算得到下次执行此job的 时间, 满足时将会执行 executor:apscheduler定义的执行器,job创建时设置执行器的名字,根据字符串你名字到scheduler获取到执行此 job的 执行器,执行job指定的函数 max_instances:执行此job的最大实例数,executor执行job时,根据job的id来计算执行次数,根据设置的最大实例数 来确定是否可执行 next_run_time:Job下次的执行时间,创建Job时可以指定一个时间[datetime],不指定的话则默认根据trigger获取触 发时间 misfire_grace_time:Job的延迟执行时间,例如Job的计划执行时间是21:00:00,但因服务重启或其他原因导致 21:00:31才执行,如果设置此key为40,则该job会继续执行,否则将会丢弃此job coalesce:Job是否合并执行,是一个bool值。例如scheduler停止20s后重启启动,而job的触发器设置为5s执行 一次,因此此job错过了4个执行时间,如果设置为是,则会合并到一次执行,否则会逐个执行 func:Job执行的函数 args:Job执行函数需要的位置参数 kwargs:Job执行函数需要的关键字参数
创建步骤
基本分为四个步骤:创建调度器→添加调度任务/触发器(满足条件)→执行器
# 1.创建调度器 # 后台执行 此处程序不会发生阻塞 scheduler = BackgroundScheduler() # 2.添加调度任务 # 3.触发器triggers='interval' # 每隔20秒执行一次 scheduler.add_job(main, 'interval', seconds=20) # 4.满足条件执行器 scheduler.start()
触发器 Trigger使用三种场景
date——定时调度(在特定的时间日期执行,作业只会执行一次)
from apscheduler.schedulers.background import BackgroundScheduler, BlockingScheduler sched = BlockingScheduler() def my_job(): print(1) # The job will be executed on November 6th, 2009 sched.add_job(my_job, 'date', run_date=date(2009, 11, 6), args=['text']) # The job will be executed on November 6th, 2009 at 16:30:05 sched.add_job(my_job, 'date', run_date=datetime(2009, 11, 6, 16, 30, 5), args=['text'])
interval——间隔调度(每隔多久执行一次)
from datetime import datetime
import os
from apscheduler.schedulers.blocking import BlockingScheduler
def tick():
print('Tick! The time is: %s' % datetime.now())
if __name__ == '__main__':
scheduler = BlockingScheduler()
# sep1 每隔3秒执行一次
scheduler.add_job(tick, 'interval', seconds=3)
# sep2 表示每隔3天17时19分07秒执行一次任务
scheduler.add_job(tick, 'interval', days=3, hours=17, minutes=19, seconds=7)
# 每20秒执行一次
scheduler.add_job(tick, 'interval', seconds=61)
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C '))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
pass
cron——某一定时时间执行(按指定的周期执行):
from datetime import datetime
import os
from apscheduler.schedulers.blocking import BlockingScheduler
def tick():
print('Tick! The time is: %s' % datetime.now())
if __name__ == '__main__':
scheduler = BlockingScheduler()
# 表示每天的19:23 分执行任务
scheduler.add_job(tick, 'cron', hour=19,minute=23)
# 每天8点整执行
scheduler.add_job(tick, 'cron', day_of_week='0-6', hour=8, minute=00, second=00)
# 每天0点,1点,8点执行
scheduler.add_job(tick,'cron',month='*', day='*', hour='0,1,8',minute='00')
# 表示2017年3月22日17时19分07秒执行该程序
scheduler.add_job(tick, 'cron', year=2017, month=3, day=22, hour=17, minute=19, second=7)
# 表示任务在6,7,8,11,12月份的第三个星期五的00:00,01:00,02:00,03:00 执行该程序
scheduler.add_job(tick, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
# 表示从星期一到星期五5:30(AM)直到2014-05-30 00:00:00
scheduler.add_job(tick, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2014-05-30')
# 表示每5秒执行该程序一次,相当于interval 间隔调度中seconds = 5
scheduler.add_job(tick, 'cron', second='*/5')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C '))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
pass
完整Demo
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
# @Time : 2020/11/17 0017 22:16
# @Author : liudinglong
# @File : send_demo.py
# @Description:
# @Question:
'''
from datetime import datetime
import json
import urllib.request
import pymysql as pms
from apscheduler.schedulers.background import BackgroundScheduler,BlockingScheduler
import os
# Mac下关闭ssl验证用到以下模块
import ssl
'''
----------------------------------------------
# 需要CMD命令下安装以下支持库:
# pip install apscheduler
# pip install pymysql
----------------------------------------------
'''
# Mac和Linux下关闭ssl验证,不然会报错
ssl._create_default_https_context = ssl._create_unverified_context
# 你的钉钉机器人url
global myurl
my_url = "https://oapi.dingtalk.com/robot/send?access_token=XXXXXXXXXXXX"
def send_request(url, datas):
# 传入url和内容发送请求
# 构建一下请求头部
header = {
"Content-Type": "application/json",
"Charset": "UTF-8"
}
sendData = json.dumps(datas) # 将字典类型数据转化为json格式
sendDatas = sendData.encode("utf-8") # python3的Request要求data为byte类型
# 发送请求
request = urllib.request.Request(url=url, data=sendDatas, headers=header)
# 将请求发回的数据构建成为文件格式
opener = urllib.request.urlopen(request)
# 打印返回的结果
print(opener.read())
def get_mysqldatas(sql):
# 一个传入sql导出数据的函数,实例为MySQL需要先安装pymysql库,cmd窗口命令:pip install pymysql
# 跟数据库建立连接
conn = pms.connect(host='服务器地址', user='用户名', passwd='密码', database='数据库', port=3306, charset="utf8")
# 使用 cursor() 方法创建一个游标对象
cur = conn.cursor()
# 使用 execute() 方法执行 SQL
cur.execute(sql)
# 获取所需要的数据
datas = cur.fetchall()
# 关闭连接
cur.close()
# 返回所需的数据
return datas
def get_ddmodel_datas(type):
# 返回钉钉模型数据,1:文本;2:markdown所有人;3:markdown带图片,@接收人;4:link类型
if type == 1:
my_data = {
"msgtype": "text",
"text": {
"content": " "
},
"at": {
"atMobiles": [
"188XXXXXXX"
],
"isAtAll": False
}
}
elif type == 2:
my_data = {
"msgtype": "markdown",
"markdown": {"title": " ",
"text": " "
},
"at": {
"isAtAll": True
}
}
elif type == 3:
my_data = {
"msgtype": "markdown",
"markdown": {"title": " ",
"text": " "
},
"at": {
"atMobiles": [
"188XXXXXXXX"
],
"isAtAll": False
}
}
elif type == 4:
my_data = {
"msgtype": "link",
"link": {
"text": " ",
"title": " ",
"picUrl": "",
"messageUrl": " "
}
}
return my_data
def main():
print('Main! The time is: %s' % datetime.now())
# 按照钉钉给的数据格式设计请求内容 链接https://open-doc.dingtalk.com/docs/doc.htm?spm=a219a.7629140.0.0.p7hJKp&treeId=257&articleId=105735&docType=1
# 调用钉钉机器人全局变量myurl
global myurl
# 1.Text类型群发消息
# 合并标题和数据
My_content = "hello, @188XXXXXXXX 这是一个测试消息"
my_data = get_ddmodel_datas(1)
# 把文本内容写入请求格式中
my_data["text"]["content"] = My_content
send_request(my_url, my_data)
# 2.Markdown类型群发消息(MySQL查询结果发送)
# 获取sql数据
sql = "SELECT branch_no,count(*) from wzy_customer_user group by branch_no order by branch_no"
my_mydata = get_mysqldatas(sql)
str1 = '\t\n\r'
seq = []
for i in range(len(my_mydata)):
seq.append(str(my_mydata[i]))
data = str1.join(seq)
data = data.replace('\'', '')
data = data.replace('(', '')
data = data.replace(')', '')
data = data.replace(',', '\t')
print(data)
Mytitle = "#### XXX报表\r\n单位\t数量\t\n\r %s"
my_Mytitle = Mytitle.join('\t\n') % data
my_data = get_ddmodel_datas(2)
my_data["markdown"]["title"] = "XXXX 通报"
my_data["markdown"]["text"] = my_Mytitle
send_request(my_url, my_data)
# 3.Markdown(带图片@对象)
my_data = get_ddmodel_datas(3)
my_data["markdown"]["title"] = "系统预警"
my_data["markdown"][
"text"] = "#### 系统预警内容 \n > @188XXXXXXXX \n\n > \n > ###### 20点00分发布 [详情](http://www.baidu.cn/)"
send_request(my_url, my_data)
# 字体颜色:<font color='#FF4500' size=2>%s</font> 双\n\n表示换行
# 4.Link类型群发消息
my_data = get_ddmodel_datas(4)
my_data["link"]["text"] = "群机器人是钉钉群的高级扩展功能。群机器人可以将第三方服务的信息聚合到群聊中,实现自动化的信息同步。 "
my_data["link"]["title"] = "自定义机器人协议"
my_data["link"][
"messageUrl"] = "https://open-doc.dingtalk.com/docs/doc.htm?spm=a219a.7629140.0.0.Rqyvqo&treeId=257&articleId=105735&docType=1"
send_request(my_url, my_data)
if __name__ == "__main__":
# 定时执行任务,需要先安装apscheduler库,cmd窗口命令:pip install apscheduler
# 随脚本执行
# 1.创建调度器
# scheduler = BlockingScheduler() --阻塞方式
# 后台执行 此处程序不会发生阻塞
scheduler = BackgroundScheduler()
# 2.添加调度任务
# 3.触发器triggers='interval'
# 每隔20秒执行一次
scheduler.add_job(main, 'interval', seconds=20)
'''
***定时执行示例***
#固定时间执行一次
#sched.add_job(main, 'cron', year=2018, month=9, day=28, hour=15, minute=40, second=30)
#表示2017年3月22日17时19分07秒执行该程序
scheduler.add_job(my_job, 'cron', year=2017,month = 03,day = 22,hour = 17,minute = 19,second = 07)
#表示任务在6,7,8,11,12月份的第三个星期五的00:00,01:00,02:00,03:00 执行该程序
scheduler.add_job(my_job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
#表示从星期一到星期五5:30(AM)直到2014-05-30 00:00:00
scheduler.add_job(my_job(), 'cron', day_of_week='mon-fri', hour=5, minute=30,end_date='2014-05-30')
#表示每5秒执行该程序一次,相当于interval 间隔调度中seconds = 5
scheduler.add_job(my_job, 'cron',second = '*/5')
'''
# 4.满足条件执行器
scheduler.start()
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
# 其他任务是独立的线程执行
while True:
pass
# time.sleep(60)
# print('进程正在执行!')
except (KeyboardInterrupt, SystemExit):
# 终止任务
scheduler.shutdown()
print('Exit The Job!')
使用案例——钉钉群定时播报消息
1、在钉钉群助手中,自定义一个机器人,如图:
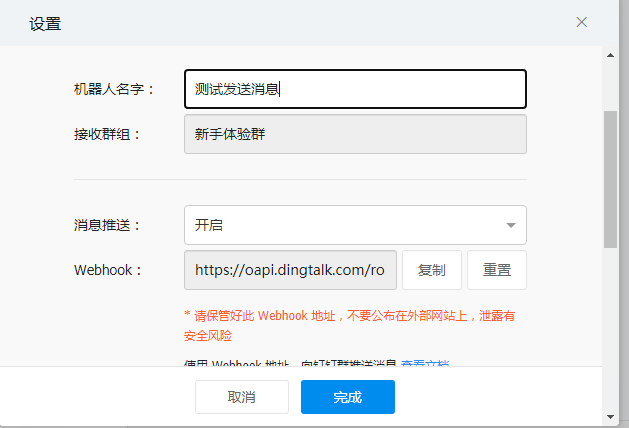
代码设置10秒发送一次,具体如下:
scheduler.add_job(main,'interval',seconds=10)
运行结果:

截图如下:

脚本部署
定时任务的脚本在一定时期内是需要持久使用,如果用IDE跑肯定不方面,于是将它弄到服务器上。
先把脚本上传到服务器上,然后按照相关的库,最后就是启动,在Linux启动方式如下:
linux命令运行py脚本:nohup python -u test.py > out.log 2>&1 &

日志:
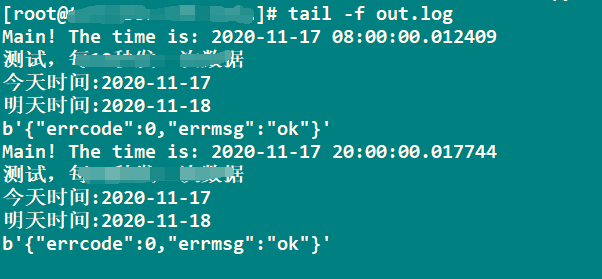
这里需要注意的是,参数使用-u的意义:
python的输出有缓冲,导致out.log并不能够马上看到输出。 -u 参数,使得python不启用缓冲。
nohup就是不挂起的意思( no hang up)。该命令的一般形式为:nohup ./test &
末尾加个&是指在后台运行,不会因为终端关闭或断开连接而终止程序。
具体可以参考:https://www.runoob.com/linux/linux-comm-nohup.html
这样就启动了一个py服务。
总结
对定时任务框架Apscheduler的简单使用到此。在工作中遇到其他需要,可以进一步了解,学习是为了解决问题,为了更好的工作。同时,欢迎小伙伴进去沟通交流测试心得与工作方法。
作者:全栈测试开发日记
出处:https://www.cnblogs.com/liudinglong/
csdn:https://blog.csdn.net/liudinglong1989/
微信公众号:全栈测试开发日记
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号