Django+Celery学习笔记1——任务队列介绍
引言
为啥要学这个?在做测试的时候,对于一些特殊场景,比如凌晨3点执行一批测试集,或者在前端发送100个请求时,而每个请求响应至少1s以上,用户不可能等着后端执行完成后,将结果返回给前端,这个时候需要一个异步任务队列。而python提供一个分布式异步消息任务队列------- Celery。
什么是任务队列
任务队列一般用于线程或计算机之间分配工作的一种机制。
任务队列的输入是一个称为任务的工作单元,有专门的职程(Worker)进行不断的监视任务队列,进行执行新的任务工作。
Celery 通过消息机制进行通信,通常使用中间人(Broker)作为客户端和职程(Worker)调节。启动一个任务,客户端向消息队列发送一条消息,然后中间人(Broker)将消息传递给一个职程(Worker),最后由职程(Worker)进行执行中间人(Broker)分配的任务。
Celery 可以有多个职程(Worker)和中间人(Broker),用来提高Celery的高可用性以及横向扩展能力。
Celery 是用 Python 编写的,但协议可以用任何语言实现。除了 Python 语言实现之外,还有Node.js的node-celery和php的celery-php。
可以通过暴露 HTTP 的方式进行,任务交互以及其它语言的集成开发。
Celery简介
Celery 是一个异步任务队列,一个Celery有三个核心组件:
1、Celery 客户端: 用于发布后台作业;当与 Flask 一起工作的时候,客户端与 Flask 应用一起运行。
2、Celery workers: 运行后台作业的进程。Celery 支持本地和远程的 workers,可以在本地服务器上启动一个单独的 worker,也可以在远程服务器上启动worker,需要拷贝代码;
3、消息代理: 客户端通过消息队列和 workers 进行通信,Celery 支持多种方式来实现这些队列。最常用的代理就是 RabbitMQ 和 Redis。
Celery场景使用举例
前面引言中已经说了两种,这里再列举一下:
1、Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理,
如果你的业务场景中需要用到异步任务,就可以考虑使用celery
2、你想对100台机器执行一条批量命令,可能会花很长时间 ,但你不想让你的程序等着结果返回,而是给你返回 一个任务ID,
你过一段时间只需要拿着这个任务id就可以拿到任务执行结果, 在任务执行ing进行时,你可以继续做其它的事情
3、Celery 在执行任务时需要通过一个消息中间件来接收和发送任务消息,以及存储任务结果, 一般使用rabbitMQ or Redis
Celery特点
1、简单:一单熟悉了celery的工作流程后,配置和使用还是比较简单的
2、高可用:当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务
3、快速:一个单进程的celery每分钟可处理上百万个任务
4、灵活: 几乎celery的各个组件都可以被扩展及自定制
Celery工作流
草图:
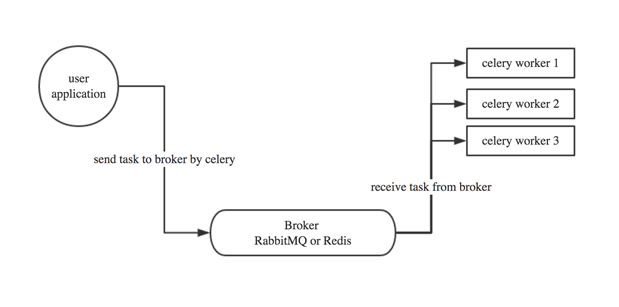
user:用户程序,用于告知celery去执行一个任务。就是produce消息提供者。
broker: 存放任务(依赖RabbitMQ或Redis,进行存储)
worker:执行任务
Celery特性描述
1、方便查看定时任务的执行情况, 如 是否成功, 当前状态, 执行任务花费的时间等.
2、使用功能齐备的管理后台或命令行添加,更新,删除任务.
3、方便把任务和配置管理相关联.
4、可选 多进程, Eventlet 和 Gevent 三种模型并发执行.
5、提供错误处理机制.
6、提供多种任务原语, 方便实现任务分组,拆分,和调用链.
7、支持多种消息代理和存储后端.
8、Celery 是语言无关的.它提供了python 等常见语言的接口支持.
Celery架构图
画一个简单的架构图,帮助理解:

Celery组件
角色:
1、Celery Beat : 任务调度器. Beat 进程会读取配置文件的内容, 周期性的将配置中到期需要执行的任务发送给任务队列.
2、Celery Worker : 执行任务的消费者, 通常会在多台服务器运行多个消费者, 提高运行效率.
3、Broker : 消息代理, 队列本身. 也称为消息中间件. 接受任务生产者发送过来的任务消息, 存进队列再按序分发给任务消费方(通常是消息队列或者数据库).
4、Producer : 任务生产者. 调用 Celery API , 函数或者装饰器, 而产生任务并交给任务队列处理的都是任务生产者.
5、Result Backend : 任务处理完成之后保存状态信息和结果, 以供查询.
任务执行方式:
1.发布者发布任务(WEB 应用)
2.任务调度按期发布任务(定时任务)
依赖库:
billiard : 基于 Python2.7 的 multisuprocessing 而改进的库, 主要用来提高性能和稳定性. librabbitmp : C 语言实现的 Python 客户端 kombu : Celery 自带的用来收发消息的库, 提供了符合 Python 语言习惯的, 使用 AMQP 协议的高级借口. 这三个库, 都由 Celery 的开发者开发和维护.
消息中间件的选择
使用于生产环境的消息代理有 RabbitMQ 和 Redis, 官方推荐 RabbitMQ.
这里我使用redis。
Celery配置说明
BROKER_URL = 'redis://localhost:6379' #代理人 CELERY_RESULT_BACKEND = 'redis://localhost:6379' #结果存储地址 CELERY_ACCEPT_CONTENT = ['application/json'] #指定任务接收的内容序列化类型 CELERY_TASK_SERIALIZER = 'json' #任务序列化方式 CELERY_RESULT_SERIALIZER = 'json' #任务结果序列化方式 CELERY_TASK_RESULT_EXPIRES = 12 * 30 #超过时间 CELERY_MESSAGE_COMPRESSION = 'zlib' #是否压缩 CELERYD_CONCURRENCY = 4 #并发数默认已CPU数量定 CELERYD_PREFETCH_MULTIPLIER = 4 #celery worker 每次去redis取任务的数量 CELERYD_MAX_TASKS_PER_CHILD = 3 #每个worker最多执行3个任务就摧毁,避免内存泄漏 CELERYD_FORCE_EXECV = True #可以防止死锁 CELERY_ENABLE_UTC = False #关闭时区 CELERYBEAT_SCHEDULER = 'djcelery.schedulers.DatabaseScheduler' # 定时任务调度器
任务调用方法
1、delay
task.delay(args1, args2, kwargs=value_1, kwargs2=value_2)
2、apply_async
delay 实际上是 apply_async 的别名, 还可以使用如下方法调用, 但是 apply_async 支持更多的参数:
task.apply_async(args=[arg1, arg2], kwargs={key:value, key:value})
支持参数:
1、countdown : 等待一段时间再执行
add.apply_async((2,3), countdown=5)
2、eta : 定义任务的开始时间.
add.apply_async((2,3), eta=now+tiedelta(second=10))
3、expires : 设置超时时间.
add.apply_async((2,3), expires=60)
4、retry : 定时如果任务失败后, 是否重试.
add.apply_async((2,3), retry=False)
5、retry_policy : 重试策略.
1、max_retries : 最大重试次数, 默认为 3 次.
2、interval_start : 重试等待的时间间隔秒数, 默认为 0 , 表示直接重试不等待.
3、interval_step : 每次重试让重试间隔增加的秒数, 可以是数字或浮点数, 默认为 0.2
4、interval_max : 重试间隔最大的秒数, 即 通过 interval_step 增大到多少秒之后, 就不在增加了, 可以是数字或者浮点数, 默认为 0.2 .
自定义发布者,交换机,路由键, 队列, 优先级,序列方案和压缩方法:
task.apply_async((2,2), compression='zlib', serialize='json', queue='priority.high', routing_key='web.add', priority=0, exchange='web_exchange')
Celery 序列化
在客户端和消费者之间传输数据需要 序列化和反序列化. Celery 支出的序列化方案如下所示:
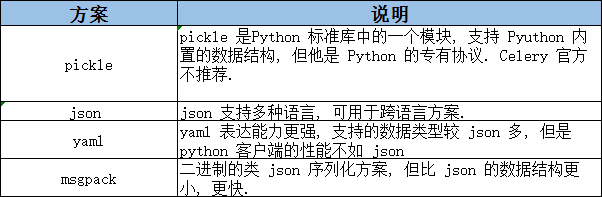
选择序列化格式
Celery默认会使用Pickle来对消息进行序列化。Pickle的好处是简单易用,但是在使用的过程中会有一些坑。当代码发生变动时,已经序列化的对象,反序列化后依然是变更前的代码。
好的实践是使用JSON作为序列化格式,使用JSON,不仅可以强迫开发者认真地设计参数,还可以避免使用pickle带来的安全隐患。
使用下面的配置:
CELERY_TASK_SERIALIZER=json
官方参考文档
官方:https://docs.celeryproject.org/en/latest/index.html
中文手册:https://www.celerycn.io/
总结
以上就是Celery的简介,有兴趣的朋友可以看看,或者进群讨论交流一下。
作者:全栈测试开发日记
出处:https://www.cnblogs.com/liudinglong/
csdn:https://blog.csdn.net/liudinglong1989/
微信公众号:全栈测试开发日记
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号