Locust + Influxdb + Grafana性能测试——单机模式(Windows篇)
引言
前面一篇文章Grafana + Prometheus监控篇之Windows监控Linux服务器资源 ,我已经讲过了在windows系统上如何使用Grafana监控Linux服务器资源。这边讲的是如何使用Grafana展示Locust性能测试数据。
背景
在使用Locust压测的时候,如果使用Web则可以查看到QPS压测过程的曲线图。而如果使用no web模式启动,Locust版本更新后,现在使用的是--headless模式启动,则只有一些打印的日志可以查看。
如果是在Linux服务器上进行压测,无界面模式的话,我们根本无法实时的看到压测数据。正好有一款强大的工具Grafana可以将Locust压测数据图表实时展示在界面上。
设计思路
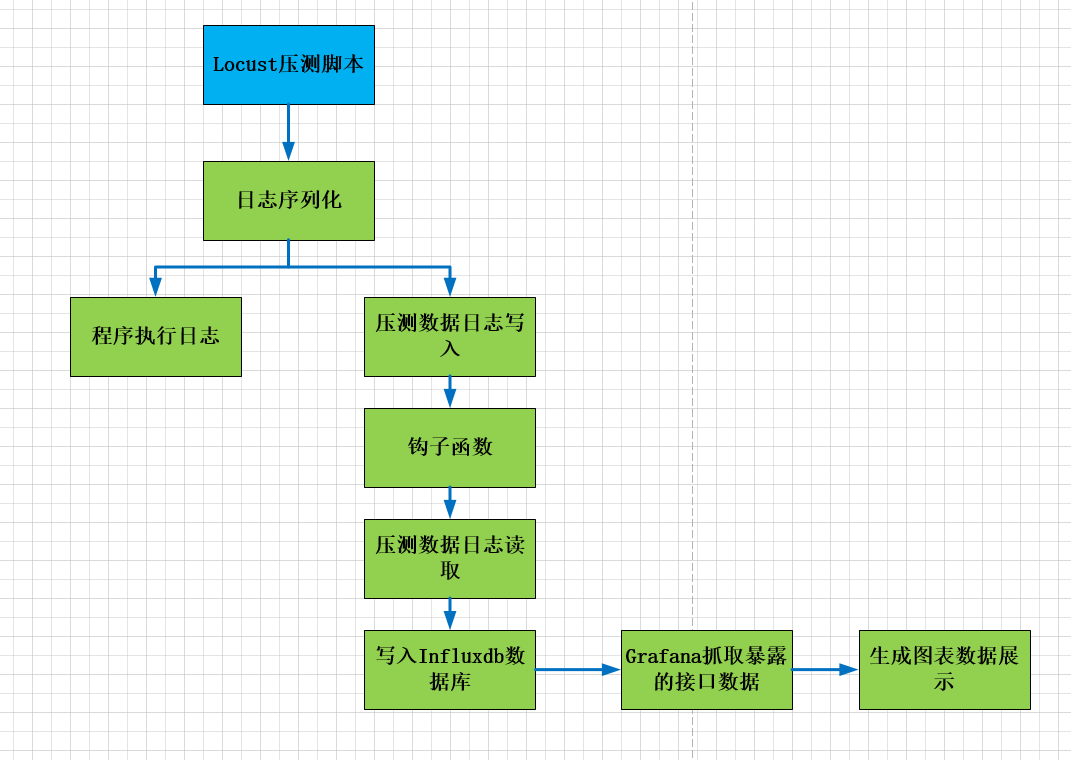
要想在Grafana平台上展示数据,最关键的就是对数据的处理,也就是对压测日志的处理。
Locust命令行模式启动,会输出两种信息,一种是压测数据,一种是Locust执行数据。
处理步骤大致分为:
1、首先将locust执行过程的日志写入文件中
2、通过读取执行文件的日志信息,再将其转化存储到influxdb数据库
3、最后根据influxdb数据库的数据,展示图表
画一个简单的草图,如下:
环境准备
1、python3.6.5
2、locust1.2.3
3、Grafana7.1.5
4、Influxdb1.8.2
如何搭建之前讲过,这里就再复述下载地址:
grafana 安装
https://grafana.com/grafana/download?platform=windows
influxdata 安装
https://portal.influxdata.com/downloads/
influxdata 连接工具
https://github.com/CymaticLabs/InfluxDBStudio/releases
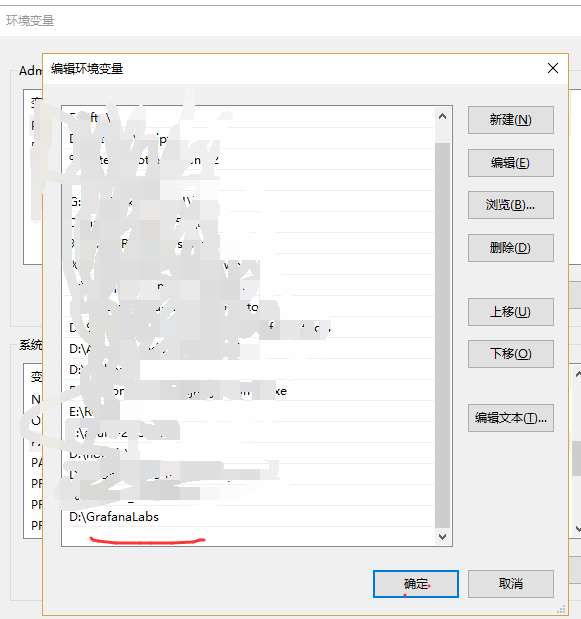
另外,windows使用命令启动grafana的方法如下:
windows命令启动是通过nssm.exe程序,所以需要在环境变量path里配置它。否则只能运行grafana-server.exe程序来启动。
首先配置环境变量:
以管理员方式打开cmd,输入nssm回车可以看到有哪些命令,如下主要命令:
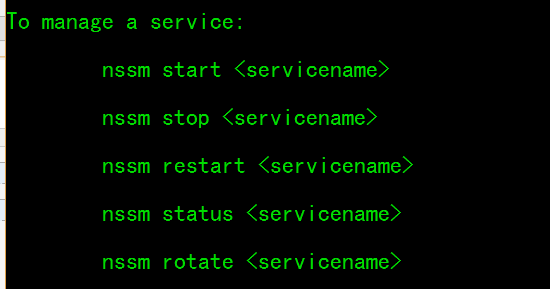
启动命令:
nssm start grafana
重启命令:
nssm restart grafana
停止命令
nssm stop grafana
测试一下启动:

打开浏览器,输入localhost:3000,账号和密码都是admin,如图:
单机模式场景
项目结构:

主要代码
读取日志程序read_pressureData.py文件:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
# @Time : 2020/10/3 0003 12:13
# @Author : liudinglong
# @File : read_pressureData.py
# @Description:
# @Question:
'''
import io
import platform
import os,sys
from db_init.conn_influxdb import ConnectInfluxDB
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # 项目目录
curPath = os.path.abspath(os.path.dirname(__file__))
rootPath = os.path.split(curPath)[0]
sys.path.append(rootPath)
pattern = '/' if platform.system() != 'Windows' else '\\'
influxdb = ConnectInfluxDB()
def pressureData_test():
"""
:param kwargs:
"""
performance_path = os.path.join(BASE_DIR ,'log'+ pattern + "run.log")
with io.open(performance_path) as f:
data_list = f.readlines()
locust_list = []
for data in data_list:
splits = data.split()
# print("splits :%s" % splits)
temp = []
for s in splits:
if s.replace(" ", "").strip('\n').strip('|').__len__() != 0:
temp.append(s)
if len(temp) > 1 and temp[0] == 'POST':
print("进入res")
print(temp)
method = temp[0]
api = temp[1]
reqs = temp[2]
fails = temp[3]
Avg = temp[4]
Min = temp[5]
Max = temp[6]
Median = temp[7]
qps = temp[8]
failures = temp[9]
locust_dict = {'Method': method, 'Name': api, 'Requests': reqs, 'Fails': fails, 'Average_ms': Avg,
'Min_ms': Min, 'Max_ms': Max, 'Median_ms': Median, 'Current_RPS': qps,
'Failures_s': failures}
locust_list.append(locust_dict)
if len(temp) > 1 and temp[0] == 'Aggregated':
print("进入Aggregated")
print("Aggregated:%s"%temp)
# method = temp[0]
api = temp[0]
reqs = temp[1]
fails = temp[2]
Avg = temp[3]
Min = temp[4]
Max = temp[5]
Median = temp[6]
qps = temp[7]
failures = temp[8]
locust_dict = {'Method': "", 'Name': api, 'Requests': reqs, 'Fails': fails, 'Average_ms': Avg,
'Min_ms': Min, 'Max_ms': Max, 'Median_ms': Median, 'Current_RPS': qps,
'Failures_s': failures}
locust_list.append(locust_dict)
influxdb.post_dump_data(locust_list, "locust")
这种方法比较简单粗暴的序列化日志,当然也可以使用正则re.match来提取。
拿到日志后需要写入到数据库,代码如下:
'''
# @Time : 2020/10/3 0003 11:21
# @Author : liudinglong
# @File : conn_influxdb.py
# @Description:
# @Question:
'''
from influxdb import InfluxDBClient
class ConnectInfluxDB:
"""
连接influxdb数据库
"""
def __init__(self):
self.influx_client = InfluxDBClient('localhost', 8086, '', '', 'testdb')
self.make = False
for database in self.influx_client.get_list_database():
if "testdb" not in database["name"]:
self.make = True
else:
# 写入前删除数据
self.influx_client.drop_measurement("locust")
self.make = False
if self.make:
self.influx_client.create_database("testdb")
def post_dump_data(self, data, measurement):
"""
@param data:
@param measurement:
"""
if isinstance(data, list):
for key in data:
json_body = [
{
"measurement": measurement,
"fields": key,
}
]
self.influx_client.write_points(json_body)
if __name__ == '__main__':
pass
运行压测程序
这里使用非GUI模式启动程序,单机模式启动方式如下:
locust -f grafana_test.py -u 10 -r 3 -t 1m -H https://api.apiopen.top/ --csv C:\Users\Administrator\PycharmProjects\Locust_grafana_demo\data_csv\ --logfile=C:\Users\Administrator\PycharmProjects\Locust_grafana_demo\log\locust.log --loglevel=INFO 1>C:\Users\Administrator\PycharmProjects\Locust_grafana_demo\log\run.log 2>&1 --headless
版本更新后,locust1.2.3无界面启动的参数是:--headless,而非--no-web。
如果想将locust的压测日志和程序print分开存,可以这样:
locust -f locustfile.py --headless -u 10 -r 3 -t 1m -H https://api.apiopen.top/ --logfile=D:\locust_test_20190228\log\locust.log --loglevel=INFO 1>D:\locust_test_20190228\log\stdout.log 2>D:\locust_test_20190228\log\run.log
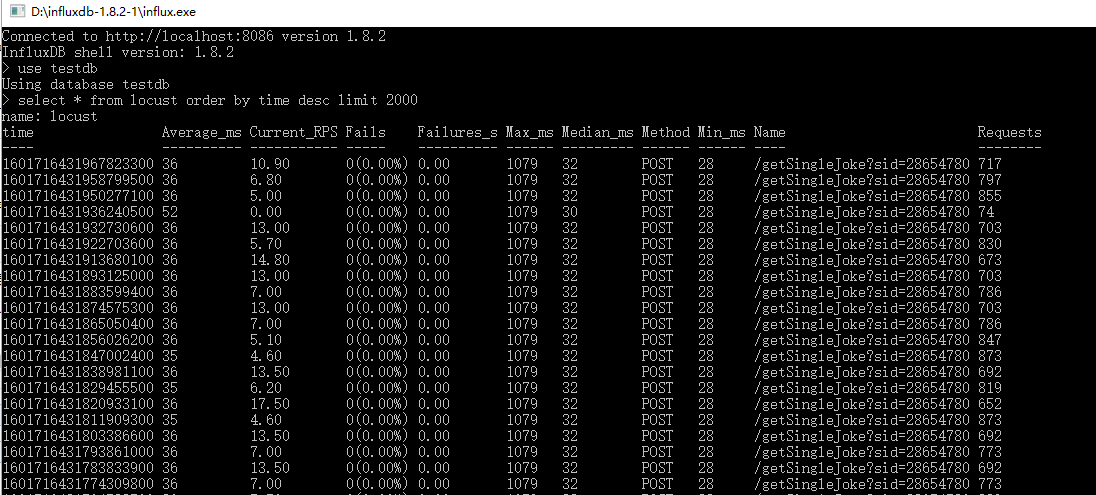
运行后可以手动执行以下写入的程序,然后再查看数据库:
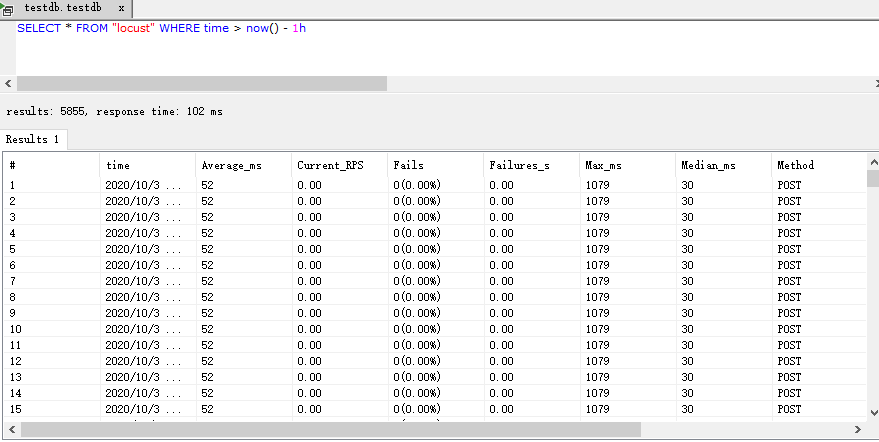
可以用工具查一下:
Grafana图标展示
首先配置好influxdb数据库数据源,如下:

配置完数据源后,再配置数据展示方式,图 + 表方式展示数据,如下:

效果如下: 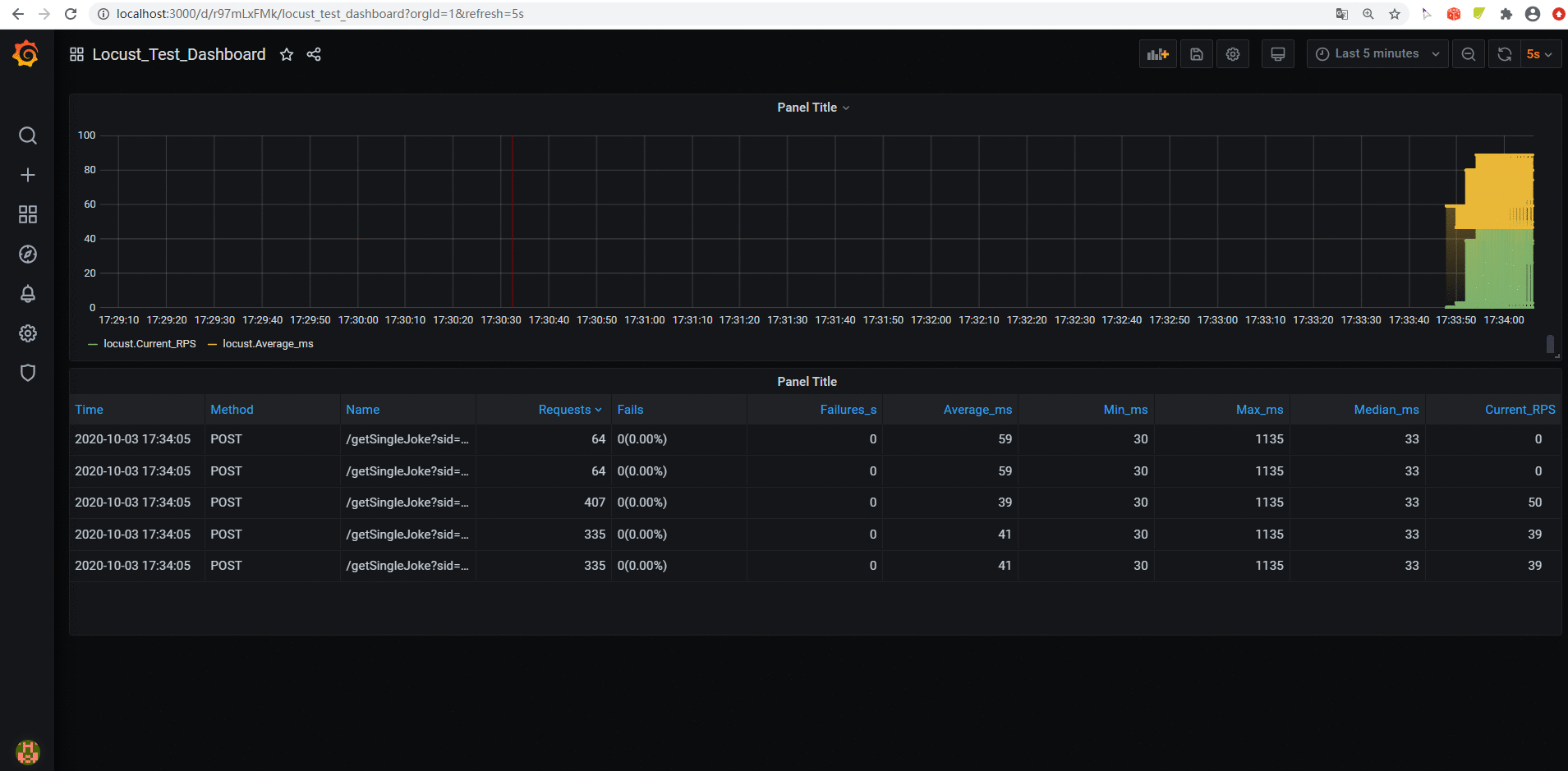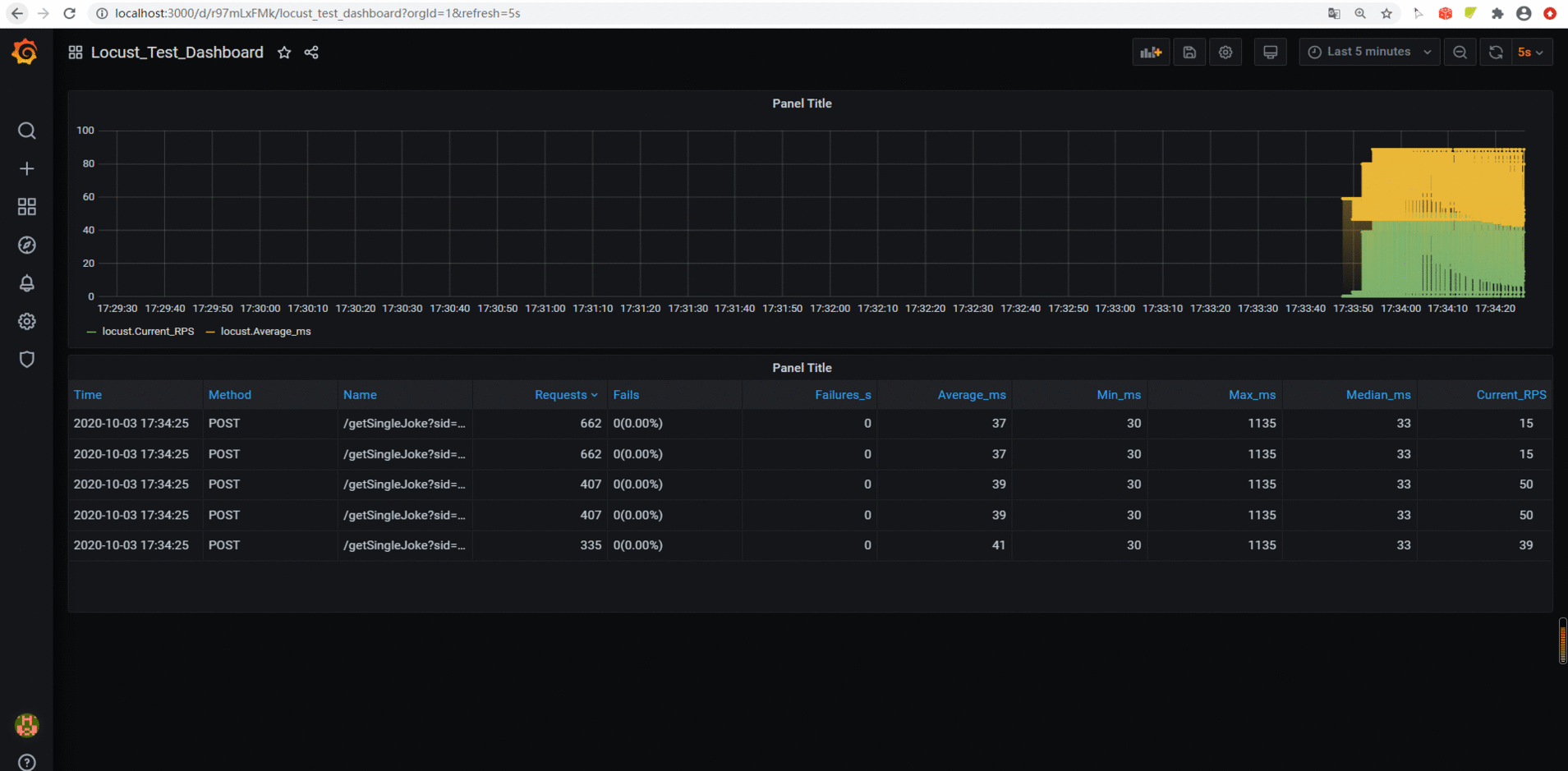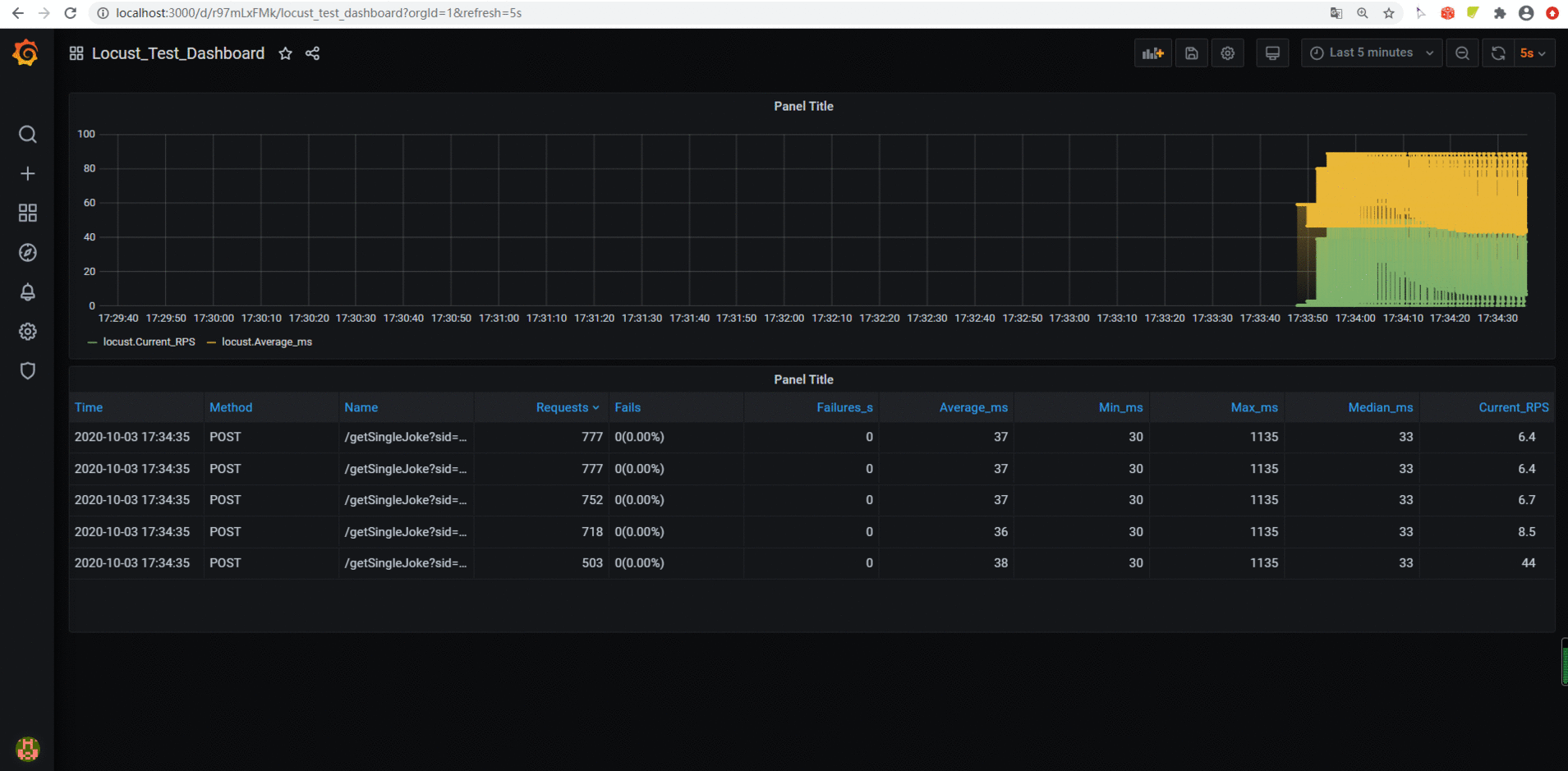
因为上面命令是执行1分钟,所以执行完后的图表是这样:
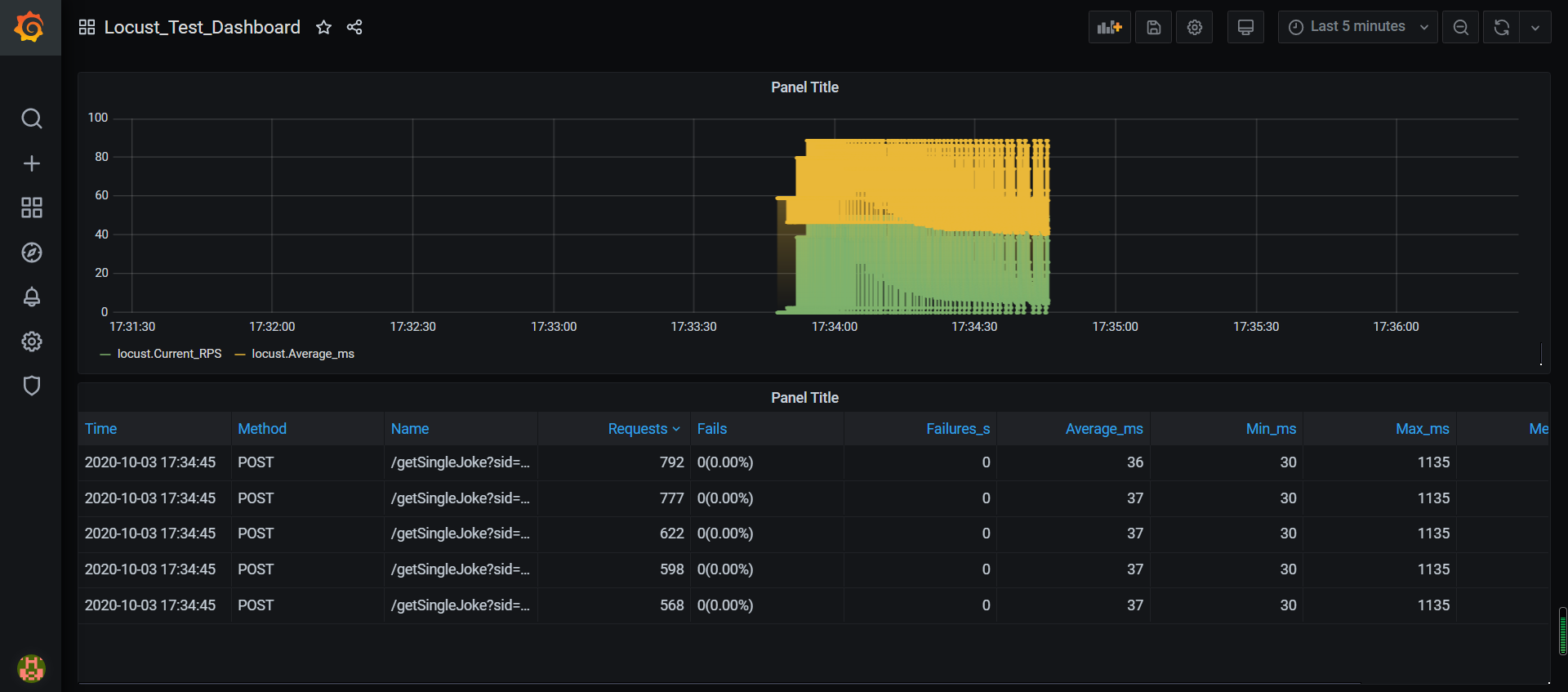
作者:全栈测试开发日记
出处:https://www.cnblogs.com/liudinglong/
csdn:https://blog.csdn.net/liudinglong1989/
微信公众号:全栈测试开发日记
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号