MLP是否可以发展为下一代视觉网络主干【读论文,网络结构】
论文:Are we ready for a new paradigm shift? A Survey on Visual Deep MLP,review,2021年末
1. MLP、CNNs和transformer结构分析
- MLP即为多层感知机,多层全连接网络前向堆叠而成,主要存在问题是参数量太大;
- CNNs为了解决上述问题,引入了两个inductive biases(可以理解为先验假设):
- 局部相关下;2. 平移不变性。由于卷积核参数是共享的,极大的降低了模型参数量;
- 由于使用卷积核的尺寸较小(3x3,5x5),使得模型感受野较小;transformer将图片打成patch,然后在全局作self-attention运算,感受野为全局,在大数据集上效果更好;
- 最近一篇研究:Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs,(CVPR2022),使用大卷积核,扩大感受野,取得不错结果。
- 发展趋势:使得感受野该大时候大,改小时候小,现在需要集大成性质工作。
2. MLP作为新范式的尝试:MLP-Mixer 【是否恰当?】
MLP作为新范式在视觉上应用以MLP-Mixer为开端,结果如下:
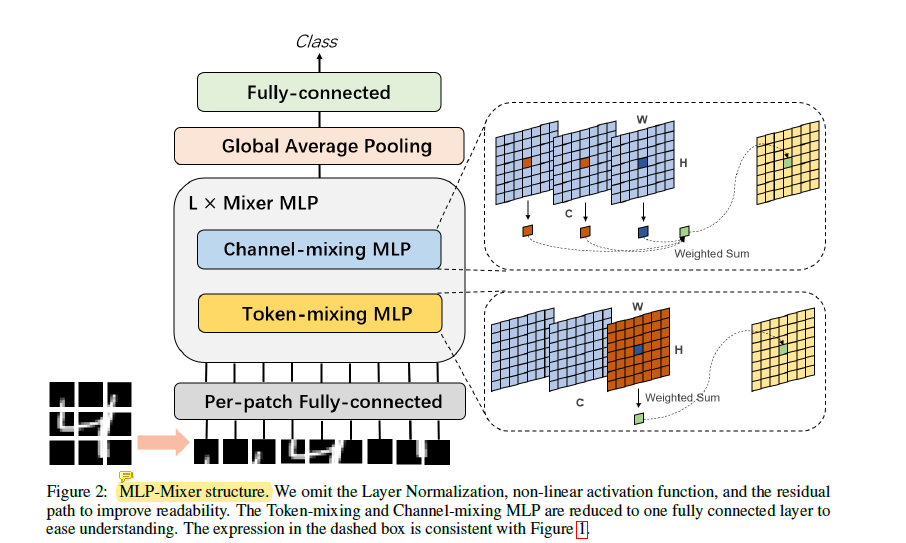
per-patch fully-connected对每个patch作线性投影,类似ViT,可以用和patch同样大小的卷积核、stride=patch size一次计算得到。
tocken-mixing MLP 和 channel-mixing MLP分别由两个全连接层加非线性激活函数(GELU)组成。tocken-mixing MLP具有全局感受野,在tocken层作变化(参数量),channel-mixing在特征维度作变化,做不同层间特征融合,和1x1卷积效果相当。两者都参数共享。
感受野、是否对输入分辨率敏感、参数量、计算复杂度(FLOPs)对比如下:
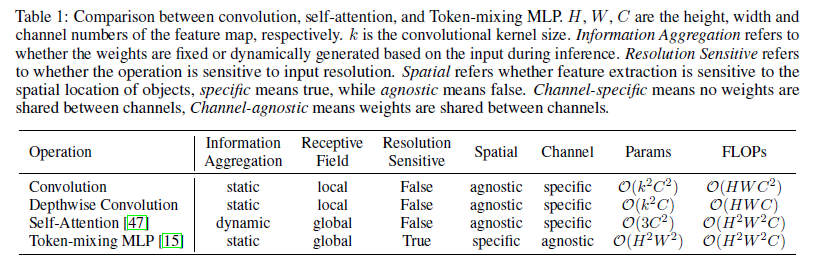
瓶颈:
- 和CNNs相比,没有先验偏差,因此需要大的数据集来训练;
- 计算复杂度和输入尺寸成平方关系(),复杂度过大;
- 不能处理任意 尺寸的图片输入;
3. MLP范式在模块层面的变体【魔改】
3.1 大部分都在魔改MLP-Mixer的tocken-mixing块,分为三类:
1.Axial and channel projection blocks
原有的tocken-mixing计算复杂度过大,因此一些人将投影空间正交分解;沿分解后的维度编码空间信息,为了解决对对输入分辨率敏感问题,WaveMLP and MorphMLP使用了局部窗口策略,但是因此影响了长程依赖(大的感受野)。
2. Channel-only projection blocks
一些人直接抛弃了空间全连接层,为了重新引入感受野,将不同空间位置的特征对齐到一个channel,实现了类似cnn的局部感受野的效果(为何不对一层全部空间做对齐?这不就全局感受野了?)
spatial-shift MLP在通道维,选取不同的位置对齐,然后做1x1卷积,可以一定程度做到感受野扩张。
3. Spatial and channel projection blocks
4.
为了降低计算复杂度,走了CNN的老路,降低了感受野
3.2 感受野和复杂度分析
下面这张图很形象了
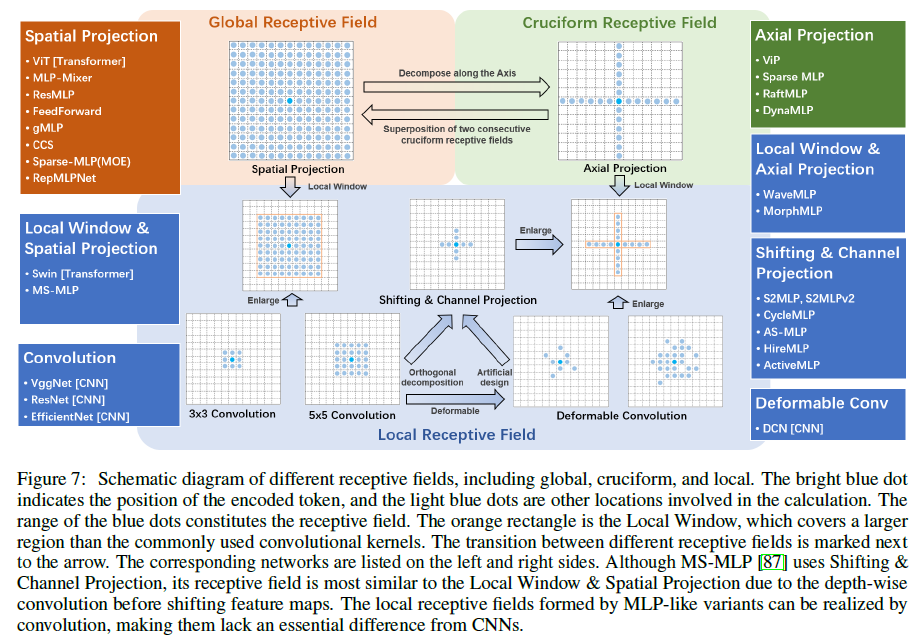
关于复杂度:
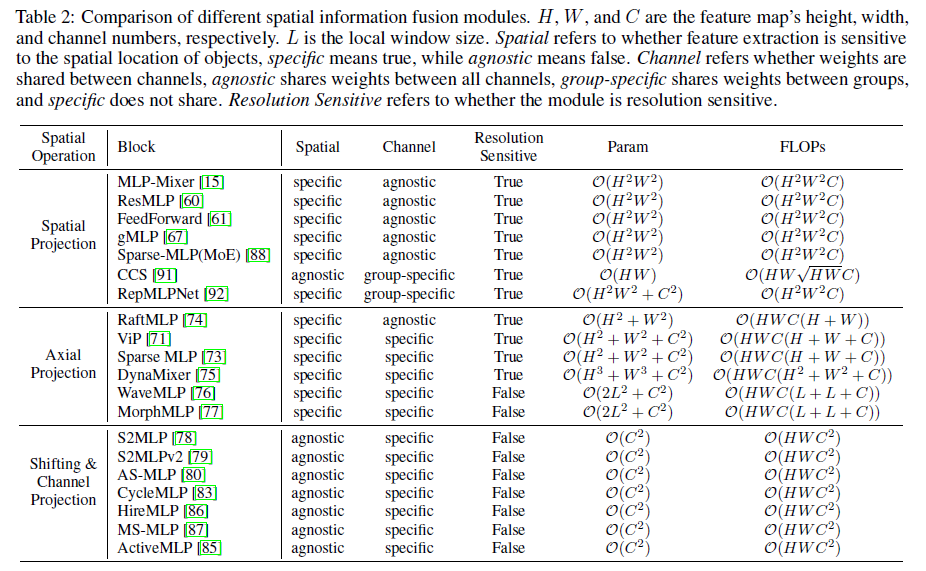
文章总结写的很棒,这里做摘记:
The bottleneck of Token-mixing MLP (Section 3.3) induces researchers to redesign the block. Recently released MLP-like variants reduce the model’s computational complexity, dynamic aggregation information, and resolving image resolution sensitivity. Specifically, researchers decompose the full spacial projection orthogonally, restrict interaction within a local window, perform channel projection after shifting feature maps, and make other artificial designs. These careful and clever designs demonstrate that researchers have noticed that the current amount of data and computational power is insufficient for pure MLPs. Comparing the computational complexity has a theoretical significance, but it is not the only determinant of inference time and final model efficiency. Analysis of the receptive field shows that the new paradigm is instead moving towards the old paradigm. To put it more bluntly, the development of MLP heads backto the way of CNNs. Hence, we still need to make efforts to balance long-distance dependence and image resolution sensitivity.
4. MLP范式的网络结构(从single-stage到pyramid)
三类,如图:
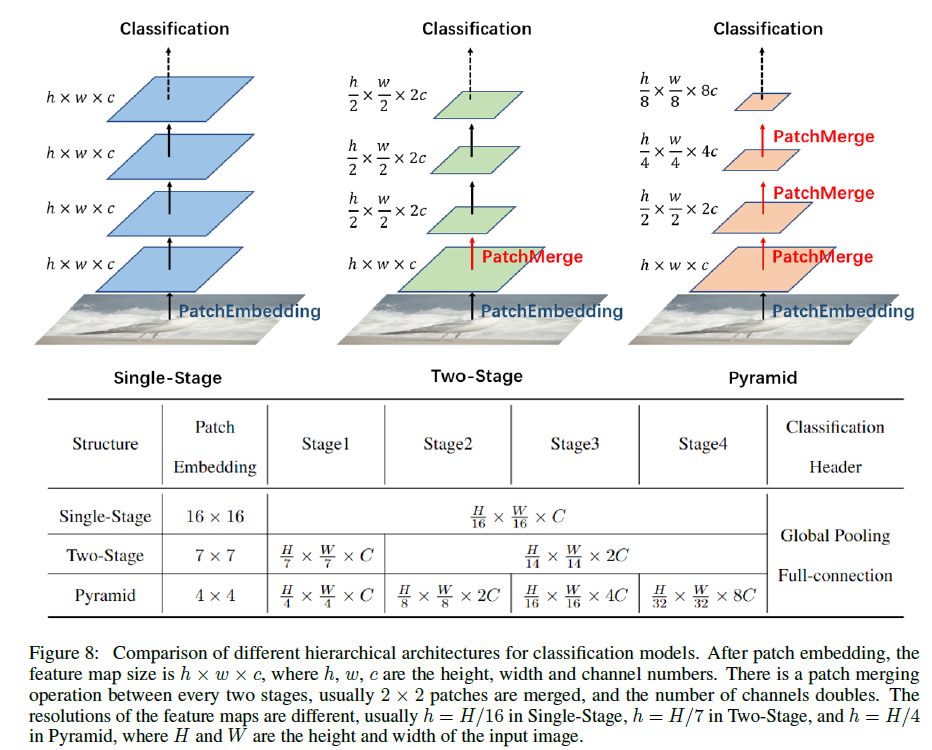
Single-stage来源于ViT,patch embedding之后,特征图尺寸不在变化,然后堆叠;由于计算资源有限,图片打成patch时候一般很大,例如16x16,这样对于下游任务影响较大,不利于小目标检测。
Vision Permutator提出了two-stage方法,开始采用7x7小patch,然后进行patch merge:宽高减半,通道增加;结果是相较于one-stage,在imagenet-1k上有一个点提升。
在金字塔结构中(patch为4x4),the researchers find that using an overlapping patch embedding provides better results, that is, convolution of 7x7 with stride = 4 instead of 4x4, which is similar to ResNet(增加不同patch间信息交互?)
ViT全局感受野,swin-transformer局部感受野+shift windows进行局部信息连接,swin效果更好,是否可以设计比swin更好的局部信息交互方式应用在CNN上?扩大CNN感受野?
如何扩大CNN感受野是个有前途的方向!
5. 在任务中表现
- 图片分类 imagenet-1k
结论:(1) MLP is still relatively backward compared to CNN and Transformer,
(2) the performance gains brought by increasing data volume and architecture-specific training strategies may be greater than the module redesign, (3) the visual community is encouraged to build self-supervised methods and appropriate training strategies for pure MLPs. - 点云
由于点云的无规律性,使得MLP和transformer更适合;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律