爬虫第三课:互联网中网页信息的爬取
基本步骤
这节课们们的目的就是使用Requests模块+BeautifulSoup模块爬取网站上的信息
首先爬取一个网站主要分两步
1、第一步我们要了解服务器与本地交换机制,选择正确的办法我们才能获取正确的信息。
2、我们需要了解一些解析真实网页获取信息的一些办法,还有一些思路
服务器与本地交换机制
我们先讲解一下服务器与本地的交换机制,首先我们先了解一个这样运作的常识,我们在平常浏览网页的时候,实际上我们使用浏览器点击每一个页面,都是向网站所在的服务器发起一个请求,我们称之为Request,而这个服务器接到请求之后呢,会给我们一个回信,我们称之为Reaponse,正是这种行为一个Request一个Response,请求与回应,实际上呢 这种方式就被成为HTTP协议,也就是说我们客户端与服务器进行会话的一种方式。
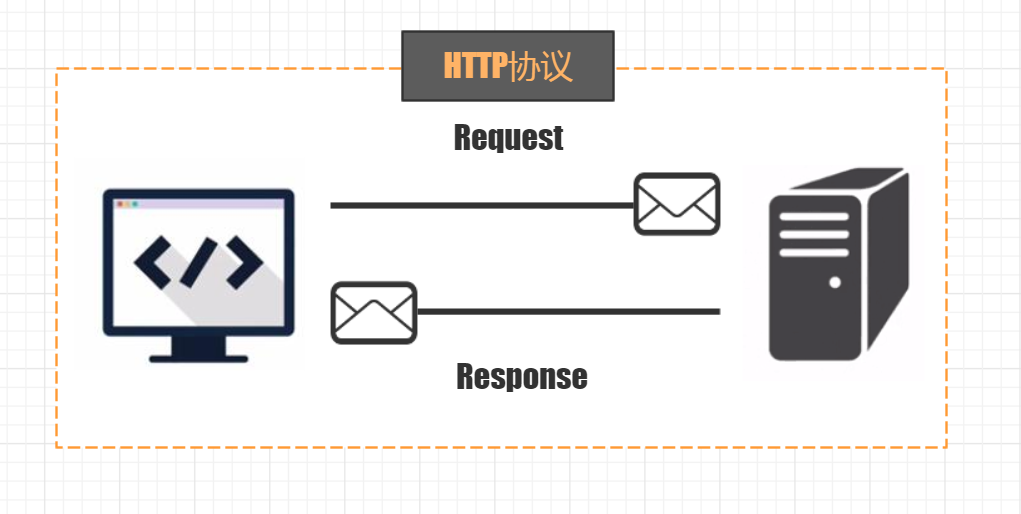
Request
在向服务器请求的时候,一个Request的行为实际上包含了不同的方法,在HTTP 1.0的时代,实际上只有GET、POST、HEAD三种方法。

然后到了HTTP 1.1之后,也就是现在不叫普及的协议之后,又增添了PUT、OPTIONS、CONNECT、TRSCE、DELETE总共加起来现在是有8中方法。

我们在这里并不会展开细致的讲解,你听到这里的时候可能会感到比较困惑,为什么一种请求还有这么多种方法,实际在这里来讲我们要了解的不需要这么多,我们只需要知道我们向服务器去请求的时候GET和POST是最常用的两种方法。

简单的来说99%的网页都可以使用这两种方法达成浏览,实际上他们的功能有很多地方很相像,但是却有着不同的作用,比如我们去点击一个页面,点击一个按钮的时候实际上是一个GET,然后再比如我们进行发微博,这种行为就是一种POST行为,但是具体的一些细节我们不展开。
我们使用爬虫抓取页面实际上也是模仿的这两种方式,而对于我们使用爬虫来讲,知道一个GET方法实际上90%以上的网站我们就都能够顺利的爬取到了,所以说接下来的Request这部分我们将着重展开,GET的使用方法,使用GET的request的请求,最简单来讲包含这些信息,使用它的方法在最左端的get,请求网址的指向与page_one.html,我们知道这是一个网页,使用什么样的协议,就是HTTP 1.1,以及他的这个主网址在哪里,相当与是host后面的后缀形成了你要请求的这个网页链接,这是一个请求,最简单的要发送的信息包含在内,当然使用request的话我们还可以去向服务器发送更多信息,比如说你是谁,你在哪儿,你是处于什么状态,还有你甚至是用什么浏览器,这些信息全部可以通过request已经发送,你发送不同的这些信息给浏览器浏览器会给你反馈不同的结果,比如说我们日常生活中,在使用手机浏览器和使用PC端浏览器所看到的页面结构内容是不一样的,这就是因为我们再使用不同浏览器向网页进行请求的时候,服务器识别了我们请求的客户端到底是什么,然后决定给我们要发送什么形态的网页,开的网页,这就是在一个简单的request中,加上了不同的信息呈现不同的结果。

Response
response,是网站回应给我们的信息,而简单的来说,我们在之前的学习中爬取的是一个本地的网页,爬取的是一个本地的网页,这些网页如果在网络环境中,实际上是在我们向网站提出一个request,之后然后服务器会把我们请求的这个网页以response的形式去发送给我们,我们会得到了一些基本信息比如说,状态码,告诉我如果是200的话那么意味着我的一次请求成功, 如果我的请求失败应该返回给我403或404。如果请求成功之后,后续应该会把网页中的元素陆陆续续地加载,这也就是我们这节的依据,再一次request的请求之后我们把网站返回给我们的这个网页进行解析,分析它,去抓取我们想要的数据。

刚才那简单的叙述了一下request 和 response的原理,那么接下来我们打开浏览器来看一些这种比较抽象的概念是如何在真实的网络环境中发生的,我们首先打开一个网页,右键点击检查(或者按F12)进入到开发者模式,我们可以看到网页的源代码已经加载出来了,这时候我们去监视这个网络行为,点击下图中选项栏中的Network,然后点击刷新网页,网页被重新加载。
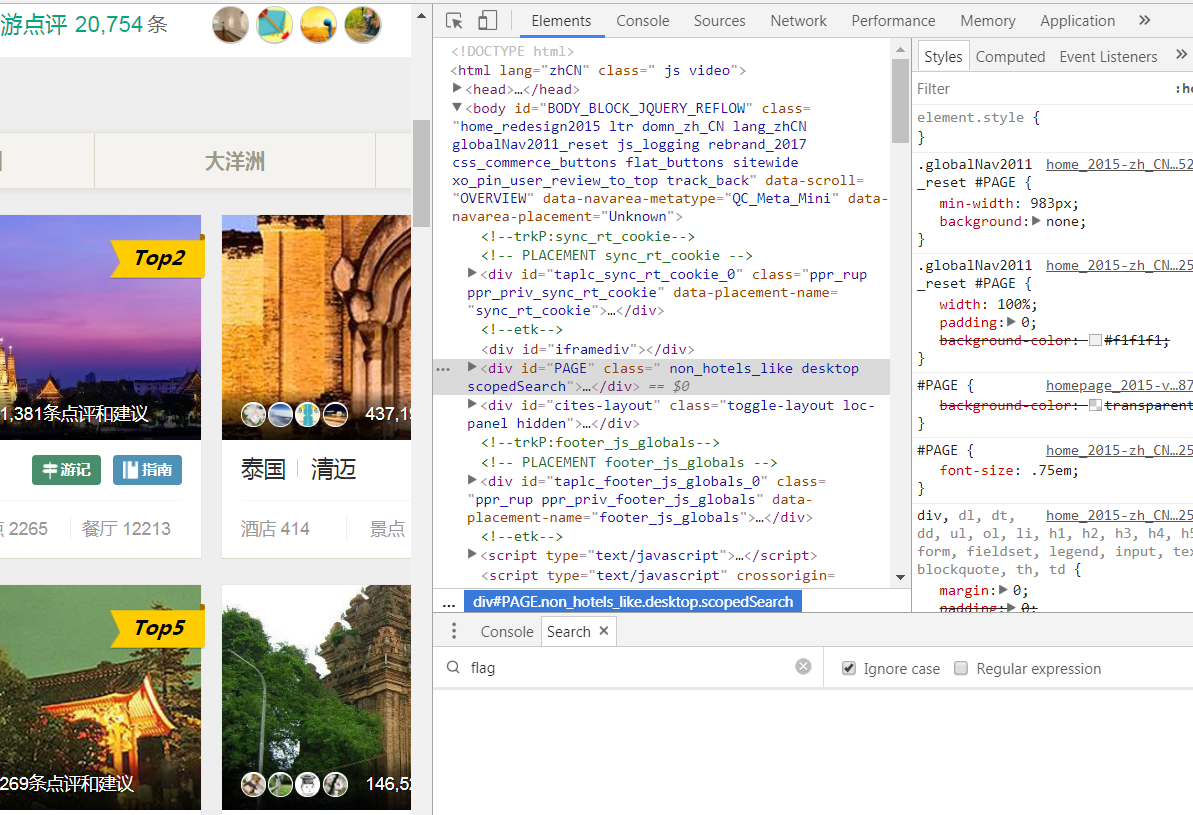
这时候我们我们可以看到网页中的加载的信息都已经显示在这里。
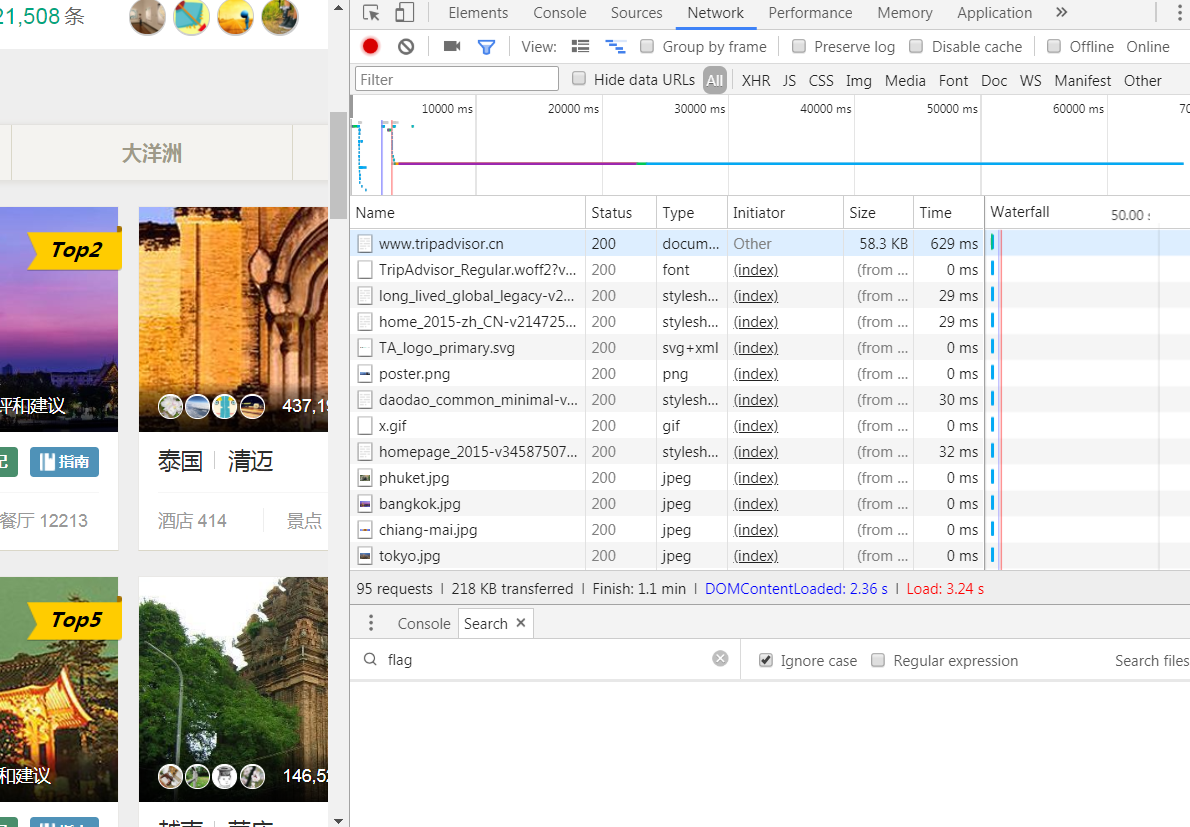
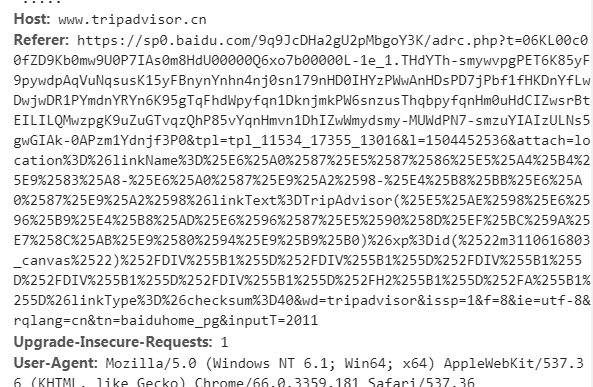
这时候我们点击途中的第一个网页,在headers中,request和response的信息全部记载在这个监视器中,我们点击Request Headers,在这里我们可以看到网页请求的方式以及一些其他的特定的信息都已显示在这里。下图中我们可以看到这个网页的cookie。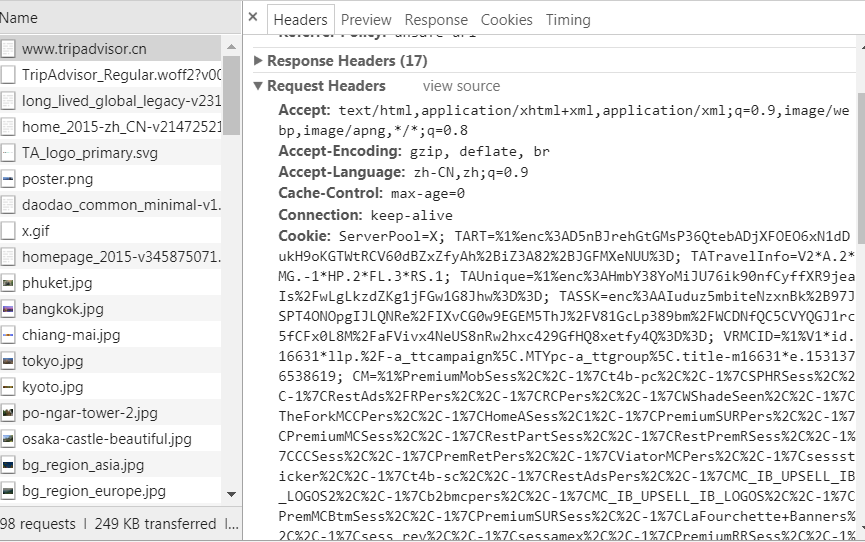
下图是Request中的User-Agent是我们使用代理的名称,以及地址host。
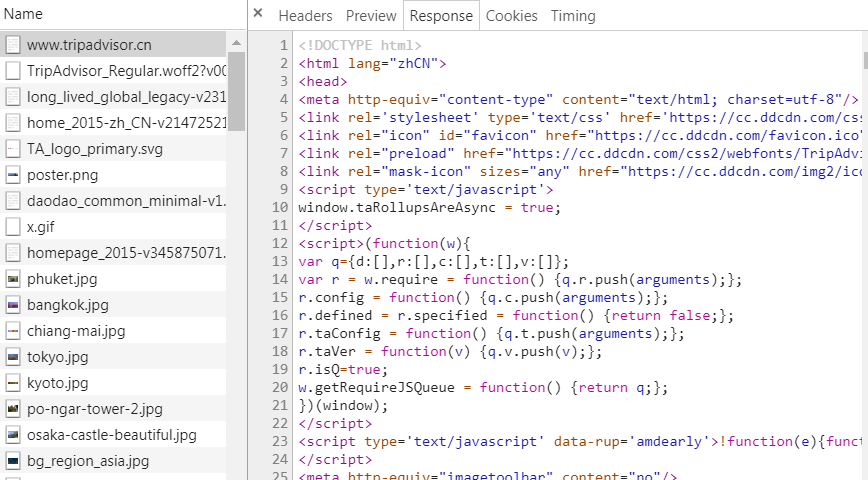
接下来我们再看选项栏中Response中的信息,实际上response的主体信息就是我们这个网页的本身,这边我么可以看到response加载的网页源码和我们之前使用检查打开看到的网页源码是一致的。
进行网页中信息爬取
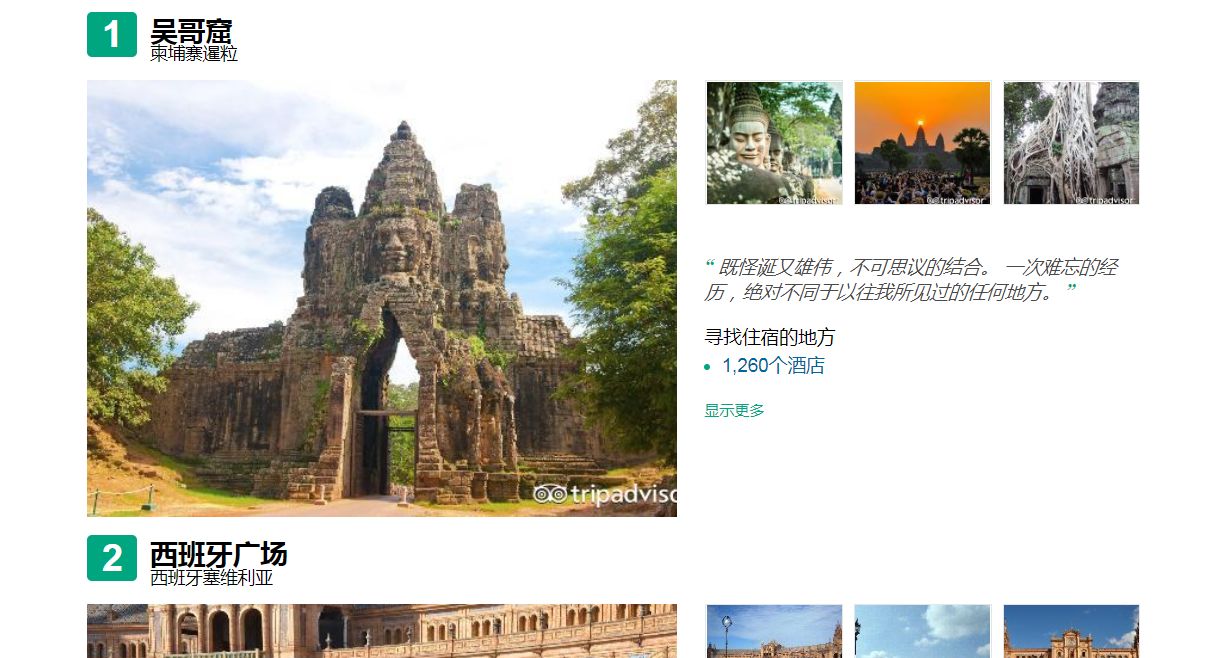
这个就是Request和Response这种交互行为在浏览器中的演示,那么接下来我们就是通过利用一种与服务器的交互行为来爬去我们想要的这个数据信息,在我们写查询代码之前,我们先来看一下我们要爬去的网页,筛选一下我们需要的元素。我们需要的元素是图片信息,以及图片名称,酒店个数。
1.使用Request向服务器请求获取网页内容

2.使用BeautifulSoup解析页面

3.描述要爬取元素的位置
首先是我们需要的标题,我们根据上节课学习的方法拿到一个标题的CSS Selector,去掉特殊的路径(学习过Html就应该明白),找到所有标题,我们定位一个元素就找到它唯一性的特征。

查找图片的时候,我们为了找到我们需要的图片,我们可以指定图片的高和宽来查找图片

酒店个数

4.整理并筛选所需信息
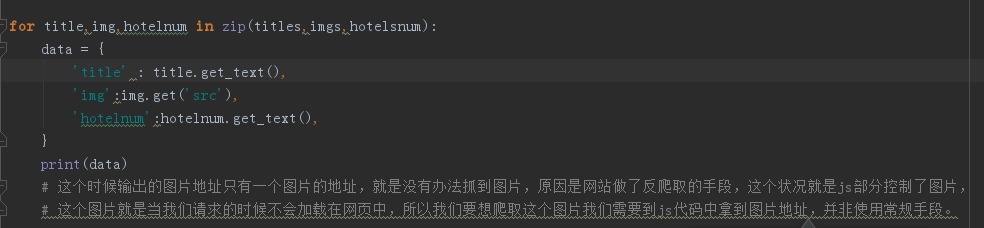
但是我们输出之后发现我们拿到的图片地址是错误的,这个是因为网站采取了反爬虫的手段,使用js代码控制了图片,我们以后再讲解怎么拿到正确图片的方法。
接下来就是代码展示
from bs4 import BeautifulSoup import requests url = 'https://www.tripadvisor.cn/TravelersChoice-Landmarks' wb_data=requests.get(url) soup = BeautifulSoup(wb_data.text,'lxml') titles = soup.select('div.winnerLayer > div.winnerName > div.mainName.extra > a') imgs = soup.select("img[width='472px']") hotelsnum = soup.select('div.lodging > div.lodgbdy > ul > li > a ') for title,img,hotelnum in zip(titles,imgs,hotelsnum): data = { 'title' : title.get_text(), 'img':img.get('src'), 'hotelnum':hotelnum.get_text(), } print(data)
今天的爬虫就讲到这里,重点就是我们先把服务器与本地交换机制了解清楚,然后进行网页信息爬取练习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号