

一、flink整合hive的catalog
flink的元数据需要存放在hive中,需要创建hive的catalog(可以理解为一个flink中的数据库)

-- 进入sql客户端 sql-client.sh -- 创建hive catalog CREATE CATALOG hive_catalog WITH ( 'type' = 'hive', 'default-database' = 'default', 'hive-conf-dir' = '/usr/local/soft/hive-1.2.1/conf' ); -- set the HiveCatalog as the current catalog of the session USE CATALOG hive_catalog; -- 创建一个flink_init.sql文件,将hive catalog放进去,
-- 后面再启动sql-client -i flink_init.sql (时指定sql文件)
create database gma_ods; create database gma_dwd; create database gma_dws; create database gma_dim; create database gma_ads;
# 1、在mysql中创建数据库gma,指定彪马格式为utf-8 # 2、修改canal配置文件 cd /usr/local/soft/canal/conf/example # 修改配置文件 vim instance.properties # 增加动态topic配置,每个表在kafka中生成一个topic canal.mq.dynamicTopic=gma\\..* # 3、开启mysqlbinlog日志 vim /etc/my.cnf # 在配置文件中增加二配置 # 需要将配置放在[mysqld]后面 # 打开binlog log-bin=mysql-bin # 选择ROW(行)模式 binlog-format=ROW # 重启mysql service mysqld restart # 4、启动canal cd /usr/local/soft/canal/bin ./restart.sh # 5、在数据库中创建表 # 执行下面这个sql文件 init_mysql_table.sql # 6、查看topic是否生成 kafka-topics.sh --list --zookeeper master:2181 # 如果topic没有生成,检测前面哪里出了问题,创建表之后必须要有topic # 7、导入数据到mysql中 # 执行sql文件 load_data.sql # 8、使用kafka控制台消费者消费数据 kafka-console-consumer.sh --bootstrap-server master:9092 --from-beginning --topic gma.base_category1
4、ODS层
-
-

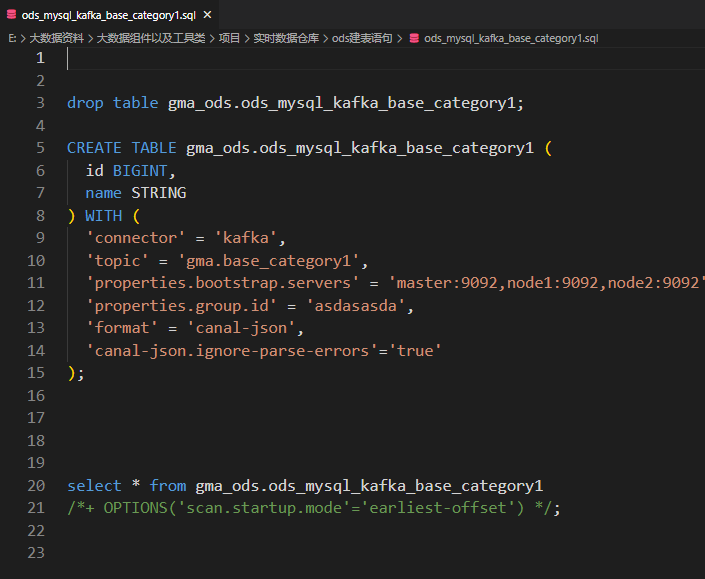
# 进入sql-client sql-client.sh -i flink_init.sql # 创建ods层所有的表 ods_mysql_kafka_base_category1:商品一级分类表 ods_mysql_kafka_base_category2:商品二级分类表 ods_mysql_kafka_base_category3:商品三级分类表 ods_mysql_kafka_base_province:省份配置报表 ods_mysql_kafka_base_region:地区配置表 ods_mysql_kafka_base_trademark:品牌表 ods_mysql_kafka_date_info:时间配置表 ods_mysql_kafka_holiday_info:节假日表 ods_mysql_kafka_holiday_year:节假日对应时间表 ods_mysql_kafka_order_detail:订单详情表,一个订单中一个商品一条数据 ods_mysql_kafka_order_info:订单表。一个订单一条数据,订单表中有订单状态 ods_mysql_kafka_order_status_log:订单转台变化日志记录表 ods_mysql_kafka_payment_info:支付流水表 ods_mysql_kafka_sku_info:商品信息表 ods_mysql_kafka_user_info:用户信息表
-
5、DIM层
将维度表单独保存到一个hbase的命名空间(相当于库)中
# 进入hbase shell habse shell # 创建命名空间 create_namespace 'gma_dim'
1 -- 1、在hbase中创建表 2 create 'gma_dim.dim_region','info' 3 4 -- 2、在flink实时数据仓库的dim层创建地区维度表 5 -- 创建hbase sink表 6 CREATE TABLE gma_dim.dim_hbase_region ( 7 pro_id BIGINT, 8 info ROW<pro_name STRING,region_id BIGINT,region_name STRING,area_code STRING>, 9 PRIMARY KEY (pro_id) NOT ENFORCED 10 ) WITH ( 11 'connector' = 'hbase-1.4', 12 'table-name' = 'gma_dim.dim_region', 13 'zookeeper.quorum' = 'master:2181' 14 ); 15 16 17 -- 3、编写flinksql 合并地区表和省份表,将数据保存到地区维度表中 18 insert into gma_dim.dim_hbase_region 19 select pro_id,ROW(pro_name,region_id,region_name,area_code) from ( 20 select b.id as pro_id,b.name as pro_name,region_id,region_name,area_code from 21 gma_ods.ods_mysql_kafka_base_region /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as a 22 inner join 23 gma_ods.ods_mysql_kafka_base_province /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as b 24 on 25 a.id=b.region_id 26 ) as c 27 28 --4、到hbase中查看是否有数据 29 scan 'gma_dim.dim_region'
商品表、品类表、spu表、商品三级分类、商品二级分类、商品一级分类表退化为商品维度表
1 -- 1、在hbsae中创建商品维度表 2 create 'gma_dim.dim_item_info','info' 3 4 -- 2、在flink实时数据仓库中创建商品维度表 5 CREATE TABLE gma_dim.dim_hbase_item_info ( 6 sku_id bigint, 7 info ROW<spu_id bigint, price decimal(10,0) , sku_name STRING, sku_desc STRING, weight decimal(10,2),
tm_id bigint, tm_name STRING, category3_id bigint, category3_name STRING, category2_id bigint, category2_name STRING,
category1_id bigint, category1_name STRING, sku_default_img STRING, create_time TIMESTAMP(3) >, 8 PRIMARY KEY (sku_id) NOT ENFORCED 9 ) WITH ( 10 'connector' = 'hbase-1.4', 11 'table-name' = 'gma_dim.dim_item_info', 12 'zookeeper.quorum' = 'master:2181', 13 'sink.buffer-flush.max-rows'='0' 14 ); 15 16 17 --3、关联多张表得到商品维度表 18 insert into gma_dim.dim_hbase_item_info 19 select 20 sku_id,ROW(spu_id , price, sku_name, sku_desc, weight, tm_id, tm_name, category3_id, category3_name,
category2_id, category2_name, category1_id, category1_name, sku_default_img, create_time) as info 21 from ( 22 select 23 a.id as sku_id, 24 a.spu_id, 25 a.price, 26 a.sku_name, 27 a.sku_desc, 28 a.weight, 29 a.tm_id, 30 b.tm_name, 31 a.category3_id, 32 c.name as category3_name, 33 d.id as category2_id, 34 d.name as category2_name, 35 e.id as category1_id, 36 e.name as category1_name, 37 a.sku_default_img, 38 a.create_time 39 from 40 gma_ods.ods_mysql_kafka_sku_info 41 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as a 42 inner join 43 gma_ods.ods_mysql_kafka_base_trademark 44 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as b 45 on a.tm_id=cast(b.tm_id as bigint) 46 inner join 47 gma_ods.ods_mysql_kafka_base_category3 48 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as c 49 on a.category3_id=c.id 50 inner join 51 gma_ods.ods_mysql_kafka_base_category2 52 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as d 53 on c.category2_id=d.id 54 inner join 55 gma_ods.ods_mysql_kafka_base_category1 56 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as e 57 on d.category1_id=e.id 58 ) as f;
1 --1、在hbase中创建用户维度表 2 create 'gma_dim.dim_user_info','info' 3 4 --2、在flink实时数据仓库中创建用户维度表 5 CREATE TABLE gma_dim.dim_hbase_user_info ( 6 user_id BIGINT, 7 info ROW<login_name STRING , nick_name STRING , passwd STRING , name STRING , phone_num STRING ,
email STRING , head_img STRING , user_level STRING , birthday DATE , gender STRING , create_time TIMESTAMP(3)>, 8 PRIMARY KEY (user_id) NOT ENFORCED 9 ) WITH ( 10 'connector' = 'hbase-1.4', 11 'table-name' = 'gma_dim.dim_user_info', 12 'zookeeper.quorum' = 'master:2181' 13 ); 14 15 --3、编写flink sql读取ods层用户信息表将数据保存到hbae中构建用户维度表 16 insert into gma_dim.dim_hbase_user_info 17 select id as user_id,ROW(login_name,nick_name,passwd,name,phone_num,email,head_img,user_level,birthday,gender,create_time) from 18 gma_ods.ods_mysql_kafka_user_info 19 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as a 20 ;
1 --1、创建kafka sink表 2 3 CREATE TABLE gma_dwd.dwd_kafka_payment_info ( 4 id bigint, 5 user_id BIGINT, 6 payment_time STRING, 7 payment_type STRING, 8 province_id BIGINT, 9 skus STRING, 10 payment_price decimal(10,2), 11 sku_num BIGINT, 12 proc_time as PROCTIME(), 13 PRIMARY KEY (id) NOT ENFORCED-- 设置唯一主键 14 ) WITH ( 15 'connector' = 'upsert-kafka', 16 'topic' = 'dwd_payment_info', 17 'properties.bootstrap.servers' = 'master:9092', 18 'key.format' = 'json', 19 'value.format' = 'json' 20 ); 21 22 --2、关联支付流水表,订单表,订单明细表,构建支付事实表 23 24 insert into gma_dwd.dwd_kafka_payment_info 25 select 26 id, 27 cast(user_id as BIGINT) as user_id, 28 payment_time, 29 payment_type, 30 cast(province_id as BIGINT) as province_id, 31 listAGG(cast(sku_id as STRING)) as skus, 32 sum(order_price*sku_num) as payment_price, 33 sum(sku_num) as sku_num 34 from ( 35 select a.id,a.user_id,a.payment_time,a.payment_type,b.province_id,c.sku_id,c.order_price,cast(c.sku_num as bigint) as sku_num from 36 gma_ods.ods_mysql_kafka_payment_info 37 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as a 38 inner join 39 gma_ods.ods_mysql_kafka_order_info 40 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as b 41 on cast(a.order_id as bigint)=b.id 42 inner join 43 gma_ods.ods_mysql_kafka_order_detail 44 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as c 45 on b.id=c.order_id 46 ) 47 as d 48 group by 49 id,user_id,payment_time,payment_type,province_id; 50 51 52 -- 消费kafka 53 kafka-console-consumer.sh --bootstrap-server master:9092,node2:9092,node2:9092 --from-beginning --topic dwd_payment_info 54 55 --在flink中查询数据 56 select * from gma_dwd.dwd_kafka_payment_info /*+ OPTIONS('scan.startup.mode'='earliest-offset') */
1 -- 1、创建kafka sink表 2 3 CREATE TABLE gma_dwd.dwd_kafka_order_info ( 4 id BIGINT, 5 consignee STRING, 6 consignee_tel STRING, 7 delivery_address STRING, 8 order_status STRING, 9 user_id BIGINT, 10 payment_way STRING, 11 create_time TIMESTAMP(3), 12 operate_time TIMESTAMP(3), 13 expire_time TIMESTAMP(3), 14 province_id BIGINT, 15 skus STRING, 16 total_amount decimal(10,2), 17 proc_time as PROCTIME(), 18 PRIMARY KEY (id) NOT ENFORCED-- 设置唯一主键 19 ) WITH ( 20 'connector' = 'upsert-kafka', 21 'topic' = 'dwd_order_info', 22 'properties.bootstrap.servers' = 'master:9092', 23 'key.format' = 'json', 24 'value.format' = 'json' 25 ); 26 27 28 -- 执行sql 29 insert into gma_dwd.dwd_kafka_order_info 30 select 31 a.id, 32 a.consignee, 33 a.consignee_tel, 34 a.delivery_address, 35 a.order_status, 36 a.user_id, 37 a.payment_way, 38 a.create_time, 39 a.operate_time, 40 a.expire_time, 41 cast(a.province_id as bigint), 42 b.skus, 43 a.total_amount 44 from 45 gma_ods.ods_mysql_kafka_order_info 46 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as a 47 join 48 ( 49 select order_id,listagg(cast(sku_id as STRING)) as skus from 50 gma_ods.ods_mysql_kafka_order_detail 51 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ 52 group by order_id 53 ) 54 as b 55 on a.id=b.order_id


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界