redis性能优化——生产中实际遇到的问题排查总结
-
背景
redis-K,V数据库,因其高性能的操作性和支持丰富的数据结构,目前大量被用于衔接应用层和关系数据库中间的缓存层。随着使用的场景越来越多,和数据量快速的递增,在生产环境中经常会遇到相关的性能瓶颈问题。这时候就需要借助一些外部的手段来分析瓶颈根源在哪,对症下药提升性能。
-
常见性能问题及问题分析过程
1、生产系统刚开始运行阶段,系统稳定。但是运行一段时间后,发现部分时间段系统接口响应变慢。查看客户端日志经常会出现这样的错误:
redis.clients.jedis.exceptions.JedisConnectionException: java.net.SocketTimeoutException: Read timed out。
2、生产环境长时间的运行后,经常会有接口返回数据失败的情况,或者是从监控上发现数据库压力某一时间暴增。查看客户端日志发现这样的错误:
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
3、突然间服务不能访问,返回错误:
redis.clients.jedis.exceptions.JedisDataException: MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk. Commands that may modify the data set are disabled. Please check Redis logs for details about the error.
当然在实际生产情况中,还有各种各样的异常情况,但是在客户端普遍表现为上面几种场景,下面我们来一步步分析上面的问题。
-
问题一:
- 首先从客户端反馈的日志,怀疑是服务器和客户端间的网络问题。为排除这个问题,我们编写脚本,在客户端定时ping服务端(redis服务),持续运行一段后,发现未有丢包的情况,排除网络问题。
- 查看redis服务端日志,未发现有异常情况。查看redis服务器资源监控,发现每几分钟左右,IO会有一波峰值,但是CPU和带宽压力都在正常范围。
- 这里介绍下我们的redis部署模式:一主一从通过redis自带的sentinal做HA,主从均有开启持久化。初步怀疑间隔性IO操作占用资源导致redis读写变慢(在此,抛出一个问题:在服务器资源CPU和带宽均未达到瓶颈的情况下,持续的IO高峰操作是否会影响物理内存的读写)。接下来采取的措施是:关闭主库的持久化,用从库来做持久化,但是这种模式下存在一个问题,如果主发生故障,sentinal做主从切换后问题同样存在,大家有更好的建议可以指点下。
- 运行一段时候,发现问题有所改善,但是依然还是会有time out的情况,只有继续排查问题。由于redis操作采用单线程,考虑会不会有某些慢查询导致time out。执行slowlog查看慢查询语句,发现有大量的keys命令操作,keys命令在大量并发情况下性能非常差,结合官方给出的warning

正式环境中,尽量避免使用keys,接下来找出使用keys的代码做优化,至此,time out问题解决。
-
问题二:
从错误日志看,是提示无法获取连接。有两种情况:
1、客户端的连接池满了,无法创建新的连接
检查客户端连接最大限制maxActive是否足够
2、redis服务端连接溢出,无法分配新的连接
检查服务端tcp连接:netstat -nat|grep -i "6379"|wc -l
检查服务端连接是否达到最大值:查看服务端支持的最大连接:CONFIG GET maxclients,查看当前服务端建立的 连接:connected_clients
通过上述检查后,发现redis服务端connected_clients连接数持续过高,经常在最大值徘徊。但是结合客户端配置的最大连接配置maxActive,计算出所有客户端连接占满的情况下最大的连接数也达不到connected_clients的连接数。
执行client list命令,发现大量的client的idle时间特别长:

正常的client连接,在持续使用的情况下,是不可能空闲这么长时间,连接长时间空闲,客户端也会关闭连接。
查看redis服务端下面两项配置:
timeout:client连接空闲多久会被关闭(这个配置容易被误导为:连接超时和操作执行超时)
tcp-keepalive:redis服务端主动向空闲的客户端发起ack请求,以判断连接是否有效
检查上述配置发现 timeout和tcp-keepalive均未启用(均为0),这种情况下,redis服务端没有有效的机制来确保服务端已经建立的连接是否已经失效。当服务器和客户端网络出现闪断,导致tcp连接中断,这种情况下的client将会一直被redis服务端所持有,就会出现上面我们看到的idle时间特长的client连接。
接下来设置timeout和tcp-keepalive来清理失效的连接。
上面问题中提到的数据库某一时间压力暴增,是由于在缓存模式下,redis请求失败,请求的压力瞬间集中到数据库。
-
问题三:
从错误提示,可以看出是向磁盘保存数据失败。引起这个问题的原因一般是内存不足,但是生产环境我们一般都会为系统分配足够的内存运行,而且查看内存情况也显示还有可用内存。
查看redis日志,发现有这个错误:Can’t save in background: fork: Cannot allocate memory
redis在保存内存的数据到磁盘时,为了防止主进程假死,会Fork一个子进程来完成这个保存操作。但是这个Fork的子进程会需要分配和主进程相同的内存,这时候就相当于需要的内存double了,如果这时候可用内存不足以分配需要的内存,将会导致Fock子进程失败而无法保存数据到磁盘。
修改linux内核参数:vm.overcommit_memory=1。至此,问题解决。
overcommit_memory有三种取值:0, 1, 2
0::检查是否有足够的可用内存供进程使用;有则允许申请,否则,内存申请失败,并把错误返回给应用进程;
1:表示内核允许分配所有的物理内存,而不管当前的内存状态如何;
2:表示内核允许分配超过所有物理内存和交换空间总和的内存。
-
优化措施总结
1、结合实际使用场景,考虑是否需要用到redis的持久化,如果单纯用来做应用层的缓存(在缓存未命中的情况下访问数据库),可以关闭持久化。
2、缓存模式下,尽量为每块缓存设置时效性,避免冷数据长时间占用资源。
3、生产环境中尽量避免使用keys操作,由于redis是单线程模式,大量的keys操作会阻塞其他的命令执行。
4、设置合理的内存回收策略,保证内存可用性的同时能适当的提供缓存的命中率。
5、提前计算出系统可能会用的内存大小,合理的分配内存。需要注意在开启持久化模式下,需要预留更多的内存提供给Fock的子进程做数据磁盘flush操作。
-
深入探讨研究
如果redis服务端未设置timeout,客户端会如何处理长时间未使用的连接?
这个问题可以从分析redis的sdk源码查找答案,不过这个过程会比较枯燥。
接下来我们直接通过抓取客户端和服务端的tcp数据包来获取答案:
这里我用wireshark来抓取中间的tcp数据包,下面是抓取了一个完整的redis连接(从发起到结束)的tcp数据包
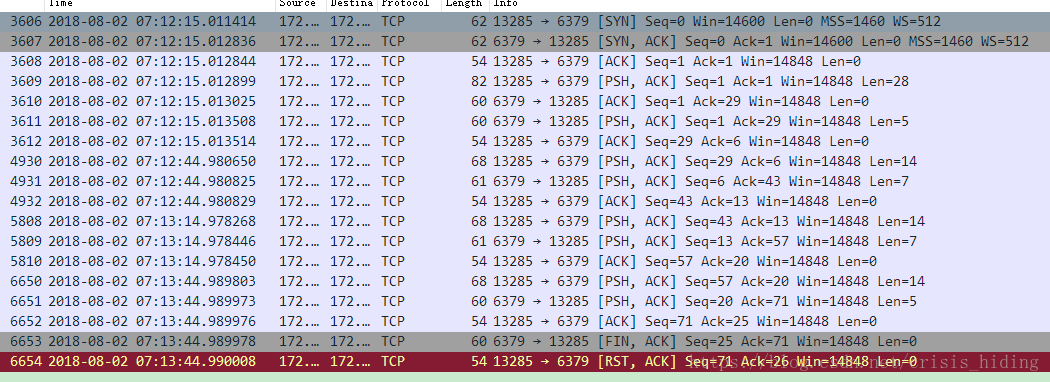
从上面可以看到,从tcp3次握手建立连接,到最后客户端发送reset包给服务端终止了这个连接。
追踪整个tcp的数据流:
*2 $4 AUTH $8 password +OK *1 $4 PING +PONG *1 $4 PING +PONG *1 $4 QUIT
从tcp数据流可以看出,整个tcp连接中间经历的操作:
1、客户端发送密码建立连接,服务端响应OK
2、客户端发送PING命令校验连接,服务端响应PONG表示成功
3、客户端再次发送PING命令校验连接,服务端响应PONG表示成功
4、客户端发送QUIT命令退出连接,服务端响应OK表示退出成功
当服务端响应QUIT命令OK后,客户端发送RESET的tcp包终止整个tcp连接。中间客户端发起了两次PING命令校验连接和一次QUIT命令来退出连接,每次间隔30s,加起来整个连接存活了90s。
————————————————
版权声明:本文为CSDN博主「_crisis」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/crisis_hiding/article/details/81490158

 浙公网安备 33010602011771号
浙公网安备 33010602011771号