
MongoDB基础2

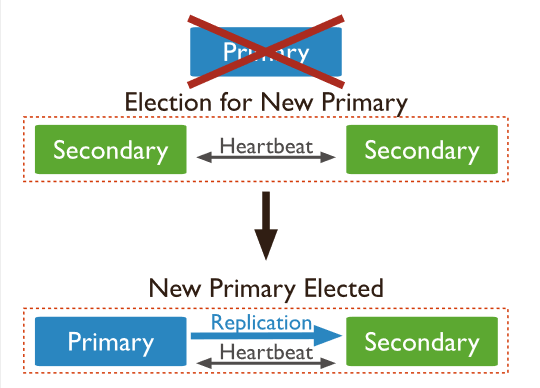
所谓副本集,就是指一组服务器的集群,其中有一个主服务器,用于处理用户的请求,其余为备份服务器,用于保存主服务器的数据副本。如果主服务器崩溃了,会自动将一个备份服务器升级为新主服务器,从而保证服务的正常运行。
MongoDB提供复制的功能,用来将数据保存到多台服务器上,在实际生产环境中,强烈建议集群并使用复制的功能,以实现故障转移和健壮服务。
MongoDB有主从复制和副本集两种主从复制模式,主从复制最大的问题就是无法自动故障转移,MongoDB副本集解决了主从复制无法自动故障转移的缺点,因此应优先考虑使用副本集复制。
对于简单的主从复制无法自动故障转移的缺陷,各个数据库都在改进,MySQL推出MGR,Redis的哨兵,MongoDB的副本集。
要创建一个副本集合,必然要创建多个副本,每个副本都有自己的data区域和log区域,所以先创建几个存放数据的文件夹,比如在前面的mongdb目录下的data/db,在创建几个存放日志的文件夹。
cd /usr/local/mongodb sudo chown -R root:wonders ./mongodb sudo chmod -R 771 ./mongodb cd /usr/local/mongodb mkdir ./data/db2 mkdir ./data/db3 mkdir ./data/db4
在启动MongoDB服务器的时候,使用--replSet 副本集名称,例如:
# --fork 表示后台启动 >./bin/mongod --port 27000 --fork --dbpath /usr/local/mongodb/data/db2 --logpath /usr/local/mongodb/logs/mongodb2.log --replSet rs0 about to fork child process, waiting until server is ready for connections. forked process: 8605 child process started successfully, parent exiting >./bin/mongod --port 27001 --fork --dbpath /usr/local/mongodb/data/db3 --logpath /usr/local/mongodb/logs/mongodb3.log --replSet rs0 ./bin/mongod --port 27002 --fork --dbpath /usr/local/mongodb/data/db4 --logpath /usr/local/mongodb/logs/mongodb4.log --replSet rs0
由于原来的服务占用了27017端口,所以做集群时我们单独开几个端口去做。

连接到副本集,进行副本集的初始化,以及rs.status()内部参数说明


# 连接进入副本集内 >./bin/mongo localhost 27000 # 查看副本集的状态 rs.status(); 或者 rs.config()查看简洁信息;或者 db.printRelicationInfo(); # rs辅助函数,rs是一个全局变量,其中包含了与复制相关的辅助函数,可以通过rs.help()查看 # 初始化副本集 > rs.initiate({"_id":"rs0",members:[{"_id":0,"host":"127.0.0.1:27000"},{"_id":1,"host":"127.0.0.1:27001"},{"_id":2,"host":"127.0.0.1:27002"}]}) { "ok" : 1, "operationTime" : Timestamp(1594306431, 1), "$clusterTime" : { "clusterTime" : Timestamp(1594306431, 1), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId" : NumberLong(0) } } } rs0:SECONDARY> rs0:PRIMARY> rs.config() { "_id" : "rs0", "version" : 1, "protocolVersion" : NumberLong(1), "writeConcernMajorityJournalDefault" : true, "members" : [ { "_id" : 0, "host" : "127.0.0.1:27000", "arbiterOnly" : false, "buildIndexes" : true, "hidden" : false, "priority" : 1, "tags" : { }, "slaveDelay" : NumberLong(0), "votes" : 1 }, { "_id" : 1, "host" : "127.0.0.1:27001", "arbiterOnly" : false, "buildIndexes" : true, "hidden" : false, "priority" : 1, "tags" : { }, "slaveDelay" : NumberLong(0), "votes" : 1 }, { "_id" : 2, "host" : "127.0.0.1:27002", "arbiterOnly" : false, "buildIndexes" : true, "hidden" : false, "priority" : 1, "tags" : { }, "slaveDelay" : NumberLong(0), "votes" : 1 } ], "settings" : { "chainingAllowed" : true, "heartbeatIntervalMillis" : 2000, "heartbeatTimeoutSecs" : 10, "electionTimeoutMillis" : 10000, "catchUpTimeoutMillis" : -1, "catchUpTakeoverDelayMillis" : 30000, "getLastErrorModes" : { }, "getLastErrorDefaults" : { "w" : 1, "wtimeout" : 0 }, "replicaSetId" : ObjectId("5f072f7fcec01346c70fc955") } }
默认情况下、客户端不能从备份节点读取数据,可以通过显示的执行如下语句来允许读:db.getMongo().setSlaveOk()
# 在非master上不允许操作 rs0:SECONDARY> show dbs; 2020-07-10T08:29:17.286+0800 E QUERY [js] Error: listDatabases failed:{ "operationTime" : Timestamp(1594340954, 1), "ok" : 0, "errmsg" : "not master and slaveOk=false", "code" : 13435, "codeName" : "NotMasterNoSlaveOk", "$clusterTime" : { "clusterTime" : Timestamp(1594340954, 1), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId" : NumberLong(0) } } } : _getErrorWithCode@src/mongo/shell/utils.js:25:13 Mongo.prototype.getDBs@src/mongo/shell/mongo.js:139:1 shellHelper.show@src/mongo/shell/utils.js:882:13 shellHelper@src/mongo/shell/utils.js:766:15 @(shellhelp2):1:1 # 在副本集上调用如下funtion后就可以在副本集上操作(只读)了 rs0:SECONDARY> db.getMongo().setSlaveOk() rs0:SECONDARY> show dbs; admin 0.000GB config 0.000GB local 0.000GB
在副本集master节点上新增数据库插入数据,查看其他节点是否同步
rs0:PRIMARY> use mydb; rs0:PRIMARY> db.mydb.insert({"name":"maomao"}) rs0:PRIMARY> db.mydb.find({}) { "_id" : ObjectId("5f07b7bcf30bbd27c30b8ea2"), "name" : "maomao" } rs0:SECONDARY> use mydb; switched to db mydb rs0:SECONDARY> db.mydb.find() { "_id" : ObjectId("5f07b7bcf30bbd27c30b8ea2"), "name" : "maomao" } # 只允许读不允许写 rs0:SECONDARY> db.mydb.insert({"name":"jiji"}) WriteCommandError({ "operationTime" : Timestamp(1594342304, 1), "ok" : 0, "errmsg" : "not master", "code" : 10107, "codeName" : "NotMaster", "$clusterTime" : { "clusterTime" : Timestamp(1594342304, 1), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId" : NumberLong(0) } } })
当kill调掉master节点后,其他节点会投票(查找最新更新的节点)选出一个新节点作为master
# 退出主节点,kill主节点 [liuwei@localhost mongodb]$ ps -ef|grep mongo liuwei 3677 3437 0 08:27 pts/3 00:00:00 ./bin/mongo --port 27001 liuwei 3994 3852 0 08:27 pts/4 00:00:00 ./bin/mongo --port 27002 root 7301 1 0 Jul09 ? 00:02:11 /usr/local/mongodb/bin/mongod --config /usr/local/mongodb/mongodb.conf liuwei 8605 1 0 Jul09 ? 00:04:18 ./bin/mongod --port 27000 --fork --dbpath /usr/local/mongodb/data/db2 --logpath /usr/local mongodb/logs/mongodb2.log --replSet rs0 liuwei 16273 2068 0 08:59 pts/2 00:00:00 grep --color=auto mongo liuwei 19075 1 0 Jul09 ? 00:04:13 ./bin/mongod --port 27001 --fork --dbpath /usr/local/mongodb/data/db3 --logpath /usr/local mongodb/logs/mongodb3.log --replSet rs0 liuwei 19936 1 0 Jul09 ? 00:04:11 ./bin/mongod --port 27002 --fork --dbpath /usr/local/mongodb/data/db4 --logpath /usr/local mongodb/logs/mongodb4.log --replSet rs0 [liuwei@localhost mongodb]$ sudo kill -9 8605 # 在从节点内查看信息,发现27000不可达,而27002此刻成为master rs0:SECONDARY> rs.status() { ... "members" : [ { "_id" : 0, "name" : "127.0.0.1:27000", "health" : 0, "state" : 8, "stateStr" : "(not reachable/healthy)", ... }, { "_id" : 1, "name" : "127.0.0.1:27001", "health" : 1, "state" : 2, "stateStr" : "SECONDARY", ... }, { "_id" : 2, "name" : "127.0.0.1:27002", "health" : 1, "state" : 1, "stateStr" : "PRIMARY", ... ... } # 27002成为master,那它是否可以插入数据? rs0:SECONDARY>db.isMaster() # 使用isMaster查看当前节点信息 rs0:SECONDARY> db.isMaster() { "hosts" : [ "127.0.0.1:27000", "127.0.0.1:27001", "127.0.0.1:27002" ], "setName" : "rs0", "setVersion" : 1, "ismaster" : true, "secondary" : false, "primary" : "127.0.0.1:27002", "me" : "127.0.0.1:27002", ... } rs0:PRIMARY> db.mydb.find() { "_id" : ObjectId("5f07b7bcf30bbd27c30b8ea2"), "name" : "maomao" } rs0:PRIMARY> db.mydb.insert({"name":"keke"}) WriteResult({ "nInserted" : 1 }) # 可以插入,且输入端变成rs0:PRIMARY
# 直接再次启动,起不来了?这是使用kill暴力杀死导致的,可能导致数据出了状况, # 因为我这是在同一台机器上演示的如果在不同服务器,可以使用db.shutdownServer()关 # 闭当前机器上的所有mongo服务 [liuwei@localhost mongodb]$ ./bin/mongod --port 27001 --fork --dbpath /usr/local/mongodb/data/db2 --logpath /usr/local/mongodb/logs/mongodb2.log --replSet rs0 about to fork child process, waiting until server is ready for connections. forked process: 22710 ERROR: child process failed, exited with error number 48 To see additional information in this output, start without the "--fork" option. # 删掉所有和27000的目录,在重启即可 [liuwei@localhost mongodb]$ rm -r -f ./data/db2 [liuwei@localhost mongodb]$ rm -f ./logs/mongodb2.log [liuwei@localhost mongodb]$ ./bin/mongod --port 27000 --fork --dbpath /usr/local/mongodb/data/db2 --logpath /usr/local/mongodb/logs/mongodb2.log --replSet rs0 [liuwei@localhost mongodb]$ ./bin/mongo --port 27000 rs0:SECONDARY> rs.isMaster() { "hosts" : [ "127.0.0.1:27000", "127.0.0.1:27001", "127.0.0.1:27002" ], "setName" : "rs0", "setVersion" : 1, "ismaster" : false, # 重新启动后,变为secondary "secondary" : true, "primary" : "127.0.0.1:27002", "me" : "127.0.0.1:27000", ... } rs0:SECONDARY> use mydb; # 重新启动的secondary里包含了之前的数据 rs0:SECONDARY> db.mydb.find() { "_id" : ObjectId("5f07b7bcf30bbd27c30b8ea2"), "name" : "maomao" } { "_id" : ObjectId("5f07bfe6dad5fec5d78733ca"), "name" : "keke" }
# 注意,需在master副本机器内执行,在其他副本内执行不了 rs0:PRIMARY> rs.remove("127.0.0.1:27000") # 我们移除刚才重启的27000 { "ok" : 1, "operationTime" : Timestamp(1594346648, 1), "$clusterTime" : { "clusterTime" : Timestamp(1594346648, 1), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId" : NumberLong(0) } } }
Oplog是主节点的local数据库中的一个固定集合,按顺序记录了主节点的每一次写操作,MonfoDB的复制功能是使用opload来实现的,备份节点通过查询这个集合就可以知道需要进行哪些数据的复制了。
每个备份节点也都维护者自己的oplog,记录着每次从主节点复制数据的操作。这样每个节点都可以作为数据的同步源提供给其他成员使用。
由于是先复制数据,再写日志,因此可能会出现重复的复制操作,这个没有关系,MongoDB会处理这种情况,多次执行Oplog中同一个操作与执行一次是一样的。
oplog的大小是固定的,它只能保存特定数量的操作日志,如果多次大批量的执行操作,oplog很快就会被填满,oplog的大小,可以通过mongod的--oplogSize来指定。
当副本集中的一个成员启动的时候,他就会检查自身状态,然后到集群中检查是否需要同步,以及从哪同步,并进行数据的复制,这个过程就称为初始化同步。
记录前的准备工作:选择一个成员作为同步源,在local.me中为自己创建一个标识符,删除所有已存在的数据库,以全新的状态开始同步。
如果当前节点的数据仍然远远落后于数据源,那么oplog将会创建索引期间的索引操作同步过来。
完成初始化同步后,切换到普通同步状态,也就是作为备份节点使用了。
如果备份节点远远落后于同步源的数据,那么这个节点上的数据就是成旧数据。通常的处理办法是:让主节点使用比较大的oplog,以保存足够多的操作日志,可以让备份节点慢慢来同步操作。
为了维护集合的最新状态,每个成员每隔两秒会向其他成员发送一个心跳请求,用于检查每隔成员的状态。常见状态如下:
STARTUP:成员刚启动时处于这个状态,加载完副本集配置后,进入STARTUP2
RECOVERING:表明成员运转正常,但暂时不能处理读取请求
DOWN:成员不可达,有可能成员还是在正常运行,也有可能挂了
回滚的时候,会把受到影响的文档,保存到数据目录下的rollback目录中,文件名为集合名.bson,基本步骤是:
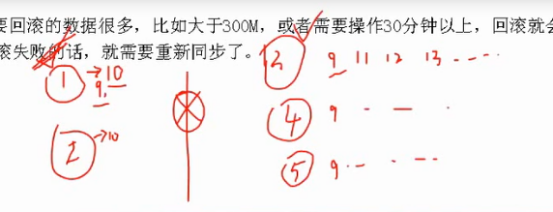
如上图,某一集群内1,2,3,4,5个节点(1,2在同一网关内,3,4,5在另一网关内),1作为主节点,某一时刻,主节点收到更新,从9条数据更新为0条,突然1,2和3,4,5之间的网络断开,此时1,2为偶数节点,无法选出主节点,3,4,5为奇数节点,假设3节点作为3,4,5的新主节点,当再次收更新时,主节3更新为11,12,13,然后4,5同步,当网络修复后,1,2和3,4,5数据不在一致,1,2也无权在争夺主节点,此时回滚,1,2回滚到和主节点最后一次同步的数据9,然后丢弃数据10,在同步主节点3上的新数据。被丢弃的数据10将存放在数据目录下的rollback目录,然后有人工判断这个数据要还是不要,要就手动加,不要就算了。
如果要回滚的数据很多,比如大于300M,或者需要操作30分钟以上,回滚就会失败。如果回滚失败的话,就需要重新同步(回滚同步是普通同步,而在重新同步指的是初始化同步)了。
由于很多维护的工作需要写入操作,所以不适合在副本集中操作,可以以单机模式启动成员,也就是不要使用副本的选项,就跟以前启动单独的服务器一样。一般使用一个跟副本集配置中不一样的端口号,这样其他成员会认为这个服务器挂了。
副本集的配置以一个文档的形式保存在local.system.replSet集合中,副本集中所有成员的这个文档都是相同的,绝对不要使用update来更新这个文档,应该使用rs或者replSetReconfig命令来修改副本集的配置。
# 创建副本集,就是启动所有成员服务器后,使用rs.initiate命令 # 修改副本集成员,有rs.add,rs.remove命令,还可以使用rs.reconfig(config)命令 # 比如修改第一个成员的host名称,示例: var config = rs.config(); config.members[0].host = "newHost:port" config.members[0].newAttr= "xyz" # 添加新的属性 rs.reconfig(config);
修改其他的也一样,先rs.config()得到当前配置,然后修改数据,再rs,rsconfig就行。
不能将buildIndexes为false的成员修改为true
所谓仲裁者,就是不保存数据,专门用来投票选举主节点的副本,以解决副本个数为偶数的情况。
只是配置该节点的时候,设置:arbiterOnly:true,如果用rs来加入的话,应该是:
rs.addArb("ip:port")
优先级用来表示一个成员渴望成为主节点的程度,可以在0-100之间,默认是1。
拥有最高优先级的成员会优先选举为主节点,只要它能得到“大多数”的票,并且数据是最新的,就可以了。
如果一个高优先级的成员,数据又是最新的,通常会是的当前的主节点自动退位,让这个优先级高的做主节点。【场景极其少见】
对于设置为隐藏的成员,客户端不能发送请求,也不会作为复制源,通常用来做备份服务器,方式是:
可以通过rs.config()或者rs.status()查看到
# 例如 > rs.initiate({"_id":"rs0",members:[ {"_id":0,"host":"127.0.0.1:27000","arbiterOnly":true,"hidden":true}, {"_id":1,"host":"127.0.0.1:27001"} ]})
可以通过slaveDelay设置一个延迟的备份节点,以在主节点的数据不小心被破坏过后,能从备份中恢复回来。要求该备份节点的优先级为0。
如果不需要备份节点与主节点拥有一样的索引,可以设置:buildIndexes:false
这是一个永久选项,一旦指定了,就无法恢复为创建索引的正常的节点了
副本集最多只能拥有12个成员,只有7个成员拥有投票权。因此要创建超过7个副本集的话,需要将其他成员的投票权设置为0,例如:
rs.add({"id":8,"host":"localhost:20008","votes":0});
如果要配置超过12个成员的话,需要使用Master/Slave的方式,不过这个方式已经不建议使用了,如果将来副本集能支持更多成员的话,这个方式可能会立即废除。
如果副本集无法达到“大多数”要求的话,可能会无法选出主节点,这个时候,可以shell连接任意成员,然后使用force选项强制重新配置,示例如下:
rs.reconfig(config,{"force":true})
可以使用setDown函数,可以自己指定退化的持续时间,示例如下:
# Master节点操作 rs.stepDown() 或者 rs.stepDown(60) // 秒为单位
如果对主节点进行维护,但不希望这段时间其他节点选举新的主节点,可以在每个备份节点上执行freeze命令,强制他们始终处于备份状态。例如
rs.freeze(100) # 秒为单位,表示冻结多长时间 # 如果在主节点上执行rs.freeze(0) 可以将退位的主节点重新变为主节点(没有选举新的主节点才行)。 # 常有设置其他从节点freeze后然后主节点stepDown(n) 进行维护
当在副本集的某个成员上执行一个非常耗时的功能的话,可以设置该成员进行维护模式,方式如下:
db.adminCommand({"replSetMaintenanceMode":true});
# 要从维护模式中恢复的话,设置为falsej就可以了
# 实际场景更建议将其从副本集中退出然后进行维护
如果希望都从主节点复制数据,可以把所有的备份成员的allowChaining设置为false
主从复制是MongoDB中一种常用的复制方式。这种方式非常灵活,可用于备份、故障恢复、读扩展等。
最基本的设置方式就是建立一个主节点和一个或者多个从节点,每个从节点要知道主节点的地址。
启动的时候加上--slave 和 --source来指定主节点的ip和端口
除了可以在启动从节点的时候,指定source外,也可以在从节点的local数据库的sources集合里面添加主节点的信息,如:
db.sources.insert({"host":"ip:port"});
# 不用时remove即可
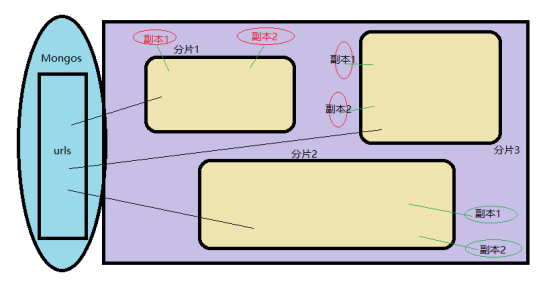
所谓分片,指的就是把数据拆分,将其分散到不同的机器上的过程。MongoDB支持自动分片,对应用而言,好像始终和一个单机的服务器交互一样。
复制是让多台服务器拥有相同的数据副本,而分片是每个分片都拥有整个副本集的一个子集,且相互是不同的数据,多个分片的数据合起来构成整个数据集。
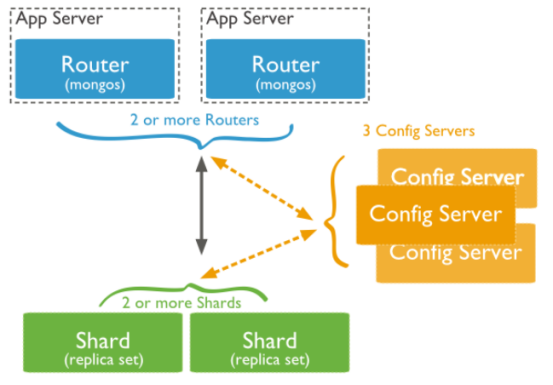
用来执行客户端访问集群数据的路由,它维护着一个内容列表,记录了每个分片包含的数据,应用程序只要连接上它,就跟操作单台服务器一样。
配置服务器就是普通的mongod服务器,保存整个集群和分片的元数据:集群中有哪些分片,分片的是哪些集合,以及数据块的分布。它极其重要,必须启用日志功能。
在大型的集群中,建议配置3台配置服务器,就足够用了。启动配置服务器的方式:
先创建几个存放数据的文件夹,比如在前面的dbs下面创建confdb文件夹,然后在confdb下面创建confdb1,confdb2,confdb3文件夹,同理在logs下面创建conflogs文件夹
然后分别启动这三个配置服务器,使用--configsvr指明配置服务器,如下:
[liuwei@localhost mongodb]$ mkdir -p ./confdata/db1 [liuwei@localhost mongodb]$ mkdir -p ./confdata/db2 [liuwei@localhost mongodb]$ mkdir -p ./confdata/db3 [liuwei@localhost mongodb]$ ./bin/mongod --configsvr --replSet rs0 --dbpath ./confdata/db1 --logpath ./conflogs/mg1.log --port 27000 --fork [liuwei@localhost mongodb]$ ./bin/mongod --configsvr --replSet rs0 --dbpath ./confdata/db2 --logpath ./conflogs/mg2.log --port 27001 --fork [liuwei@localhost mongodb]$ ./bin/mongod --configsvr --replSet rs0 --dbpath ./confdata/db3 --logpath ./conflogs/mg3.log --port 27002 --fork [liuwei@localhost mongodb]$ ./bin/mongo --port 27000 > rs.initiate({"_id":"rs0","configsvr":true,"members":[{"_id":0,"host":"localhost:27000"},{"_id":1,"host":"localhost:27001"},{"_id":2,"host":"localhost:27002"}]})
--configsvr默认的端口为27019,默认的数据目录为/data/configdb,可以使用--dbpath和--port自己定义。
注意不要使用--replSet选项,配置服务器不是副本集成员。Mongos会向所有的3台配置服务器发送写请求,并确保3台服务器拥有相同的数据。
[liuwei@localhost mongodb]$ mkdir sharddata [liuwei@localhost mongodb]$ mkdir sharddata/db1 [liuwei@localhost mongodb]$ mkdir sharddata/db2 [liuwei@localhost mongodb]$ mkdir sharddata/db3 [liuwei@localhost mongodb]$ mkdir shardlogs [liuwei@localhost mongodb]$ ./bin/mongod --shardsvr --replSet rs1 --dbpath ./sharddata/db1 --logpath ./shardlogs/smg1.log --port 37000 --fork [liuwei@localhost mongodb]$ ./bin/mongod --shardsvr --replSet rs1 --dbpath ./sharddata/db2 --logpath ./shardlogs/smg2.log --port 37001 --fork [liuwei@localhost mongodb]$ ./bin/mongod --shardsvr --replSet rs1 --dbpath ./sharddata/db3 --logpath ./shardlogs/smg3.log --port 37002 --fork [liuwei@localhost mongodb]$ ./bin/mongo --port 37000 > rs.initiate({"_id":"rs1","members":[{"_id":0,"host":"localhost:37000"},{"_id":1,"host":"localhost:37001"},{"_id":2,"host":"localhost:37002"}]}) # 同上,在加一个分片rs2
mkdir mongoslogs # mongodb 3.4版本之前 ./bin/mongos --configdb localhost:30001,localhost:30002,localhost:30003 --logpath ./mongoslogs/mongos.log --port 40000 --fork # mongodb 3.4版本之后,要求配置服务器必须为副本集 ./bin/mongos --configdb rs0/localhost:27000,localhost:27001 --logpath ./mongoslogs/mongos.log --port 40000 --fork
可以启动任意多个mongos,通常是一个应用服务器使用一个mongos,也就是说mongos通常与应用服务器运行在一个机器上。
mongos的默认端口是27017,可以用chunkSize来指定块的大小,默认是200M
如果没有副本集,安装前面讲的创建并初始化一个;如果有一个副本集,就打开相应的服务器,并把副本集运行起来。
# 将分片rs1加入 mongos> sh.addShard("rs1/localhost:37000,localhost:37001") # 将分片rs2也加入 mongos> sh.addShard("rs2/localhost:37004")
使用sh.status();查看状态,会发现整个副本集里面的服务都加入进来了。
注意:添加分片过后,客户端应该连接mongos进行操作,而不是连接副本集了。
也可以创建但mongod服务器的分片,但不建议在生产环境中使用。
至此一个分片就创建好了,然后可以重复步骤,创建一个新的副本集,加入到分片中来。
[liuwei@localhost mongodb]$ ./bin/mongo --port 40000 mongos> sh.status() --- Sharding Status --- sharding version: { "_id" : 1, "minCompatibleVersion" : 5, "currentVersion" : 6, "clusterId" : ObjectId("5f0fe9f9b8d9b947bceabcf7") } shards: active mongoses: autosplit: Currently enabled: yes balancer: Currently enabled: yes Currently running: no Failed balancer rounds in last 5 attempts: 0 Migration Results for the last 24 hours: No recent migrations databases: { "_id" : "config", "primary" : "config", "partitioned" : true } # 连接到分片服务器 mongos> sh.addShard("rs1/localhost:37000") { "shardAdded" : "rs1", "ok" : 1, ... } mongos> sh.addShard("rs2/localhost:37004") mongos> sh.status() ... shards: { "_id" : "rs1", "host" : "rs1/localhost:37000,localhost:37001,localhost:37002", "state" : 1 } { "_id" : "rs2", "host" : "rs2/localhost:37004,localhost:37005,localhost:37006", "state" : 1 } ... databases: { "_id" : "config", "primary" : "config", "partitioned" : true }
需要明确指定分片的数据库和集合,MongoDB才会对数据进行自动分片。
sh.enableSharding("数据库名")
# mongos> sh.enableSharding("zndz")
# mongos> sh.enableSharding("xinhua")
然后指定分片的集合,还要分片的键,如果对已经存在的集合进行分片,那么值得这个分片键上必须有索引;如果集合不存在,mongos会自动在分片键上创建索引。例如:
sh.shardCollection("数据库名.集合名",{"分片的键":1})
# mongos> sh.shardCollection("zndz.user",{"userId":1})
# mongos> sh.shardCollection("xinhua.user",{"userId":1})
mongos> sh.status()
...
shards:
{ "_id" : "rs1", "host" : "rs1/localhost:37000,localhost:37001,localhost:37002", "state" : 1 }
{ "_id" : "rs2", "host" : "rs2/localhost:37004,localhost:37005,localhost:37006", "state" : 1 }
...
databases:
{ "_id" : "config", "primary" : "config", "partitioned" : true }
...
{ "_id" : "xinhua", "primary" : "rs2", "partitioned" : true, "version" : { "uuid" : UUID("f72de793-3a66-499e-a02d-82f1b665e5de"), "lastMod" : 1 } }
xinhua.user
shard key: { "userId" : 1 }
unique: false
balancing: true
chunks:
rs2 1
{ "userId" : { "$minKey" : 1 } } -->> { "userId" : { "$maxKey" : 1 } } on : rs2 Timestamp(1, 0) # 只分了一块,从最小到最大,都放在rs2
{ "_id" : "zndz", "primary" : "rs1", "partitioned" : true, "version" : { "uuid" : UUID("ffec4e10-6c7a-475f-86e0-1aa49657fc82"), "lastMod" : 1 } }
zndz.user
shard key: { "userId" : 1 }
unique: false
balancing: true
chunks:
rs1 1
{ "userId" : { "$minKey" : 1 } } -->> { "userId" : { "$maxKey" : 1 } } on : rs1 Timestamp(1, 0) # 只分了一块,从最小到最大,都放在rs2
# 打印状态发现zndz被放在分片1中,而xinhua被放在分片2中
# 分别进入两个进入分片服务器副本集查看
[liuwei@localhost mongodb]$ ./bin/mongo --port 37000
rs1:PRIMARY> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
zndz 0.000GB
rs2:PRIMARY> show dbs;
admin 0.000GB
config 0.000GB
local 0.000GB
xinhua 0.000GB
# 在mongos里使用添加操作,实际上数据会存在分片中
mongos> use xinhua
switched to db xinhua
mongos> db.xinhua.insert({"userId":"u1"})
WriteResult({ "nInserted" : 1 })
rs2:PRIMARY> db.xinhua.find()
{ "_id" : ObjectId("5f0ffcfd09875819ce3575af"), "userId" : "u1" }
rs2:PRIMARY>
MongoDB将文档分组成为块,每个块由给定片键特定范围内的文档组成,一个块只存于一个分片上,所有MongoDB用一个较小的表就能维护块和分片的映射关系。
块与块间的数据不能重复,因此不能使用数组来作为片键,因为MongoDB会为数组创建多个索引条目,从而导诊同一数据在多个块中出现。
块信息保存在config.chunks集合中,sh.status()里面也带有分块的信息。
如果单个分片键可能重复的话,可以创建复合分片键,方式跟创建复合索引一样。
mongos会记录每个块中插入了多少数据,如果一个块的数据大小超出了块的大小,或者达到某个阈值(拆分点),MongoDB会自动的拆分这个块。
拆分的时候,配置服务器会创建新的块文档,同时修改旧的块范围。进行拆分的时候,所有的配置服务器都必须可以到达,否则不会进行拆分,此时就会造成“拆分风暴”,也就是mongos不断发起拆分请求,却无法拆分的情况。唯一的解决办法就是保证配置服务器的健康和稳定。
均衡器会周期性的检查分片间是否存在不均衡,如果存在,则开始块的迁移。不均衡的表现是:一个分片明显比其他分片拥有更多的块。
每隔几秒钟,mongos就会尝试成为均衡器,如果没有其他可用的均衡器,mongos就会对整个集群加锁,以防止配置服务器对集群进行修改,然后做一个均衡操作。
均衡不会影响mongos的正常路由操作,因此对客户端没有任何影响。
可以查看config.locks集合,看看哪一个mongos是均衡器,语句如下:
db.locks.findOne({"_id":"balancer"})
# _id为balancer的文档就是均衡器
# 字段who表示当前或者曾经作为均衡器的mongos
# 字段state表示均衡器是否在运行,0非活动,2正常均衡,1正在尝试得到索,一般不会看到状态1
默认情况下,MongoDB会在分片间均匀的分配数据,但是,如果服务器配置严重失衡,比如某些机器配置非常高,而其他机器只是普通机器,那么应该使用maxSize选项,来指定分片能增长到的最大存储容量,单位是MB。
db.runCommand({"addShard":"myrepl/ip:port","maxSize":1000})
注意maxSize更像是一个建议而非规定,MongoDB不会从maxSize处截断一个分片,也不会阻止分片增加数据,而是会停止数据移动到该分片,当然也可能会移走一部分数据。因此可以理解这个maxSize是一个建议或者提示。
使用集群时,不能把整个集合看成一个“即时快照”了,这个问题很严重,比如:
在一个分片集合上,对数据进行计数,很有可能得到的式比实际文档多的数据,因为有可能数据正在移动复制
更新操作也面临问题,无法确保在多个分片间只发生一次,因此要更新单个文档,一点要在条件钟使用片键,否则会出现问题。
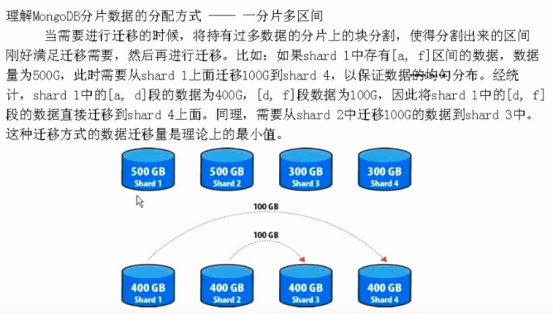
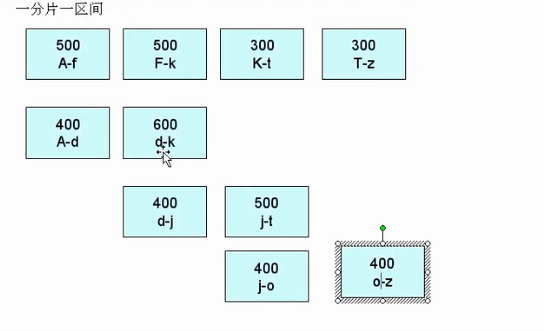
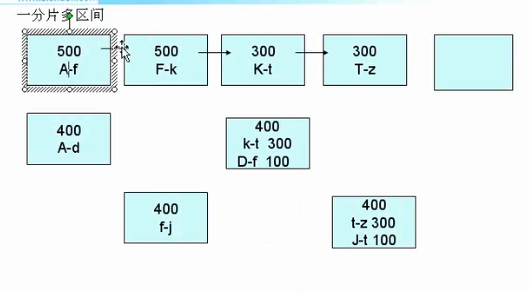
所谓片键,就是用来拆分数据的字段,通常1-2个字段,由于片键一旦确定,并已经分片过后,基本上就不可能再修改片键了,因此初期设计和选择就非常重要了
一旦插入了文档片键不可修改,要修改就必须先删除文档,然后才能修改片键
就是片键可取的值非常少,所以叫做小基数。通常这不是个好方式,因为:片键有N个值,也就最多只能有N个块,也就是最多只能N个分片。
这也意味着当某个块越来越大的时候,MongoDB无法拆分块,因此你什么也干不了,除了购买更大的硬盘。
就是片键值是不断增加的,类似于自增字段,通常这不是个好方式,因为:
新加入的数据始终会加入最后一个块,即所有数据都被添加到一个块上,从而导致了热点必然存在,且是单一,不可分割的热点。
由于数据始终会先加入到最大块,会导致最大块需要不断的拆分出新的小块
会导致数据均衡处理很困难,因为所有的新块都是由同一个分片创建的。
就是片键值是随机散列的数据,这种方式对数据的均衡是有好处的,数据加载速度也很快,缺点是:如果需要按照片键值进行范围查找的话,就必须到所有分片上执行了。这种方式比前两种较好,但并不是较理想的。
# 创建一个散列片键,需要先创建散列索引,示例如下: db.user.ensureIndex({"userId":"hashed"}); # 然后对集合分片,示例如下 sh.shardCollection("mydb.users",{"userId":"hashed"})
这个就要具体问题具体分析和选择了,比如:选择用户IP,电话号码段,或者是自定义的编码段等。如果要指定特定范围的块出现在特定的分片中,可以为分片添加tag,然后为块指定tag。例如:
sh.addShardTag("myrep2","gtu")
sh.addTagRange("mydb.users",{"userId":"v0"},{"userId":"v9"},"gtu")
# 设定v0-v9的数据存放到myrep2这个分片里面去
# 在设置范围的时候,可以使用:ObjectId()、MinKey、MaxKey等来作为值
# 不用某个tag了可以删除;sh.removeShardTag("myrep2","gtu")
其中升序键的每个值最好能对应集时到几百个数据块,而查询键则是应用程序通常都回一句其进行查询的字段。
例如:某应用,用户会定期访问过去一个月的数据,就可以在{month:1,user:1}上进行分片,month是一个粗粒度的升序字段,每个月都会增大;而user是经常会查询某个特定用户数据的查询字段。
注意:查询键不可以是升序字段,否则该片键退化成为一个升序片键,照样会面临热点问题
通常通过 准升序键 来控制数据局部化,而查询键则是应用上常用的查询字段
# 列出所有的Shard db.runCommand({"listshards":1}) # 查看分片信息 db.printShardingStatus() # 判断是否分片 db.runCommand({"isdbgrid":1}) # 返回ok为1的就是分片 # 查看集群信息摘要 sh.status() # 查看连接统计 db.adminCommand({"connPoolStats":1})
config.shards 记录着所有分片的信息
config.databases 记录集群中所有数据库信息
config.collections 记录所有分片集合的信息
config.chunks 记录集合中所有块信息
config.changelog 记录集群操作
config.tags 记录分片标签
use config
db.shards.find()
一个mongos或者mongod最多允许20000个连接,可在mongos的命令行配置中使用maxConns选项来控制mongos能创建的连接数量。
sh.addShard()


