

ELK学习笔记(五)简单搜索和DSL查询
检索文档
现在我们有一些数据存储在Elasticsearch中,我们可以开始处理这个应用程序的业务需求。
这在Elasticsearch中很容易。我们只需执行HTTP GET请求并指定文档的地址——索引,类型和ID。使用这三个信息,我们可以返回原始的JSON文档,并且响应包含有关文档的一些元数据。
现在我们可以直接通过Kibana->Dev Tools来发送请求,GET很简单,根据你的参数返回对应的结果。
搜索所有User信息,请求:

您可以看到我们使用索引springboot-elk和类型springboot-elk,但是我们现在使用_search端点,而不是指定文档ID。默认情况下,搜索将返回前10个结果。

解释一下返回的结果集:
hits:
- total 总数
- hits 前10条数据
- hits 数组中的每个结果都包含_index、_type和文档的_id字段,被加入到_source字段中这意味着在搜索结果中我们将可以直接使用全部文档。
- 每个节点都有一个_score字段,这是相关性得分(relevance score),它衡量了文档与查询的匹配程度。默认的,返回的结果中关联性最大的文档排在首位;这意味着,它是按照_score降序排列的。没有指定任何查询,所以所有文档的相关性是一样的,因此所有结果的_score都是取得一个中间值1。
took:整个搜索请求花费的毫秒数。
_shards:节点告诉我们参与查询的分片数(total字段),有多少是成功的(successful字段),有多少的是失败的(failed字段)。
time_out:告诉我们查询超时与否。一般的,搜索请求不会超时。如果响应速度比完整的结果更重要,你可以定义timeout参数为10或者10ms(10毫秒),或者1s(1秒)
GET /_search?timeout=10ms
Elasticsearch将返回在请求超时前收集到的结果。
注意:timeout不会停止执行查询,它仅仅告诉你目前顺利返回结果的节点然后关闭连接。在后台,其他分片可能依旧执行查询,尽管结果已经被发送。
使用超时是因为对于你的业务需求来说非常重要,而不是因为你想中断执行长时间运行的查询。
多索引和多类别
在所有索引的所有类型中搜索:/_search
在索引gb的所有类型中搜索:/gb/_search
在索引gb和us的所有类型中搜索:/gb,us/_search
在以g或u开头的索引的所有类型中搜索:/g*,u*/_search
在索引gb的类型user中搜索:/gb/user/_search
在索引gb和us的类型为user和tweet中搜索:/gb,us/user,tweet/_search
在所有索引的user和tweet中搜索:/_all/user,tweet/_search
当你搜索包含单一索引时,Elasticsearch转发搜索请求到这个索引的主分片或每个分片的复制分片上,然后聚集每个分片的结果。搜索包含多个索引也是同样的方式——只不过会有更多的分片被关联。
分页
如果你想每页显示5个结果,页码从1到3,那请求如下:
GET /_search?size=5 GET /_search?size=5&from=5 GET /_search?size=5&from=10
应该当心分页太深或者一次请求太多的结果。结果在返回前会被排序。但是记住一个搜索请求常常涉及多个分片。每个分片生成自己排好序的结果,它们接着需要集中起来排序以确保整体排序正确。
现在假设我们请求第1000页——结果10001到10010。工作方式都相同,不同的是每个分片都必须产生顶端的10010个结果。然后请求节点排序这50050个结果并丢弃50040个!
简易搜索
search API有两种表单:一种是“简易版”的查询字符串(query string)将所有参数通过查询字符串定义,另一种版本使用JSON完整的表示请求体(request body),这种富搜索语言叫做结构化查询语句(DSL)。
查询字符串搜索对于在命令行下运行特定情况下查询特别有用。例如这个语句查询所有类型为springboot-elk并在message字段中包含Rock字符的文档:
GET /springboot-elk/springboot-elk/_search?q=message:Rock
下一个语句查找message字段中包含"Rock"和host字段包含"Ubuntu"的结果。实际的查询只需要:
+message:Rock +host:ubuntu
但是url编码需要将查询字符串参数变得更加神秘:
GET /_search?q=%2Bmessage%3ARock+%2Bhost%3Aubuntu"+"前缀表示语句匹配条件必须被满足。类似的"-"前缀表示条件必须不被满足。所有条件如果没有+或-表示是可选的——匹配越多,相关的文档就越多。
更复杂的语句
下一个搜索的语句:
- message字段包含"mary"或"john"
- date晚于2017-09-10
+message:(mary john) +date:>2017-09-10编码后的查询字符串变得不太容易阅读
?q=%2Bname%3A(mary+john)+%2Bdate%3A%3E2017-09-10就像你上面看到的例子,简单查询字符串搜索惊人的强大。允许我们简洁明快的表示复杂的查询。这对于命令行下一次性查询或者开发模式下非常有用。
然而,你可以看到简洁带来了隐晦和调试困难。而且它很脆弱——查询字符串中一个细小的语法错误,像-、:、/或"错位就会导致返回错误而不是结果。
最后,查询字符串搜索允许任意用户在索引中任何一个字段上运行潜在的慢查询语句,可能暴露私有信息甚至使你的集群瘫痪。
取而代之的,生产环境我们一般依赖全功能的请求体搜索API,它能完成前面所有的事情,甚至更多。
DSL查询
查询字符串搜索对于从命令行进行搜索非常方便,但它有其局限性。Elasticsearch提供了一种丰富,灵活的查询语言,称为查询DSL,它允许我们构建更复杂,更健壮的查询。
使用JSON请求正文指定域特定语言(DSL)。我们可以代表所有以前的搜索,像这样:
GET springboot-elk/springboot-elk/_search { "query" : { "match" : { "message" : "rock" } } }
这将返回message中包含rock的所有记录。可以看到一些事情已经改变。例如,我们不再使用查询字符串参数,而是使用请求正文。此请求体是使用JSON构建的,并使用匹配查询。
为了更好的演示,下面添加一些数据
PUT /megacorp/employee/1 { "first_name" : "John", "last_name" : "Smith", "age" : 25, "about" : "I love to go rock climbing", "interests": [ "sports", "music" ] } PUT /megacorp/employee/2 { "first_name" : "Jane", "last_name" : "Smith", "age" : 32, "about" : "I like to collect rock albums", "interests": [ "music" ] } PUT /megacorp/employee/3 { "first_name" : "Douglas", "last_name" : "Fir", "age" : 35, "about": "I like to build cabinets", "interests": [ "forestry" ] }
注意/megacorp/employee/1包含的信息。
megacorp:索引的名称
emplogee:类型的名称
1:员工的id
成功执行返回的是一个JSON文本,包含所有关于该员工的信息。
注意:
- 如果执行过程中失败了,可能存在的原因是elasticsearch默认配置中不允许自动创建索引,所以我们可以先简单在elasticsearch.yml配置文件添加
action.auto_create_index:true,允许自动创建索引。 - 没有必要首先执行任何管理任务,如创建一个索引或指定每个字段所包含的数据类型。我们可以直接索引一个文档。Elasticsearch附带默认的一切,因此所有必要的管理任务都会使用默认值在后台处理。
全文搜索(Full-Text Search)
让我们尝试更高级的全文搜索,传统数据库真正难以胜任的任务。
GET /megacorp/employee/_search { "query" : { "match" : { "about" : "rock climbing" } } }
您可以看到我们使用与之前相同的匹配查询来搜索关于“攀岩”字段。我们得到两个匹配的文档:

默认情况下,Elasticsearch按匹配结果的相关性分值(即每个文档与查询匹配程度)对匹配结果进行排序。第一个和最高分的结果是显而易见的:John·Smith关于字段清楚地说“攀岩”。
但为什么Jane·Smith也返回了?她的文档被返回的原因是因为在她的字段中提到了“rock”这个词。因为只有“岩石”被提及,而不是“攀登”,她的分数低于John的。
这是Elasticsearch如何在全文字段中进行搜索并返回最相关的结果的一个很好的例子。这种相关性的概念对于Elasticsearch很重要,并且是一个完全与传统关系数据库无关的概念,其中记录匹配或不匹配。
精确字段搜索
在字段中查找单个字词是很好的,但有时你想要匹配字词或短语的确切序列。
为此,我们使用改为match_phrase查询:
GET /megacorp/employee/_search { "query" : { "match_phrase" : { "about" : "rock climbing" } } }
仅返回John Smith的文档

高亮搜索结果
许多应用程序喜欢从每个搜索结果突出显示文本片段,以便用户可以看到文档与查询匹配的原因。在Elasticsearch中检索突出显示的片段很容易。
让我们重新运行我们以前的查询,但添加一个新的highlight参数:
GET /megacorp/employee/_search { "query" : { "match_phrase" : { "about" : "rock climbing" } }, "highlight": { "fields" : { "about" : {} } } }
当我们运行此查询时,将返回与之前相同的返回,但现在我们在响应中得到一个新的部分,称为突出显示。
这包含来自about字段的文字片段,其中包含在 HTML标记中包含的匹配单词:

分析
最后,我们来到我们的最后一个业务需求:允许管理员在员工目录上运行分析。Elasticsearch具有称为聚合的功能,允许您对数据生成复杂的分析。它类似于GROUP BY中的SQL,但功能更强大。
例如,让我们找到我们的员工最喜欢的兴趣:
GET /megacorp/employee/_search
{
"aggs": {
"all_interests": {
"terms": { "field": "interests" }
}
}
}如果Elasticsearch 5版本以前,将会返回:
{
...
"hits": { ... },
"aggregations": {
"all_interests": {
"buckets": [
{
"key": "music",
"doc_count": 2
},
{
"key": "forestry",
"doc_count": 1
},
{
"key": "sports",
"doc_count": 1
}
]
}
}
}我们可以看到,两个员工对音乐感兴趣,一个在林业,一个在体育。这些聚合不是预先计算的,它们是从与当前查询匹配的文档即时生成的。
然而如果我们使用的是Elasticsearch 5版本以上的话,将会出现如下异常:
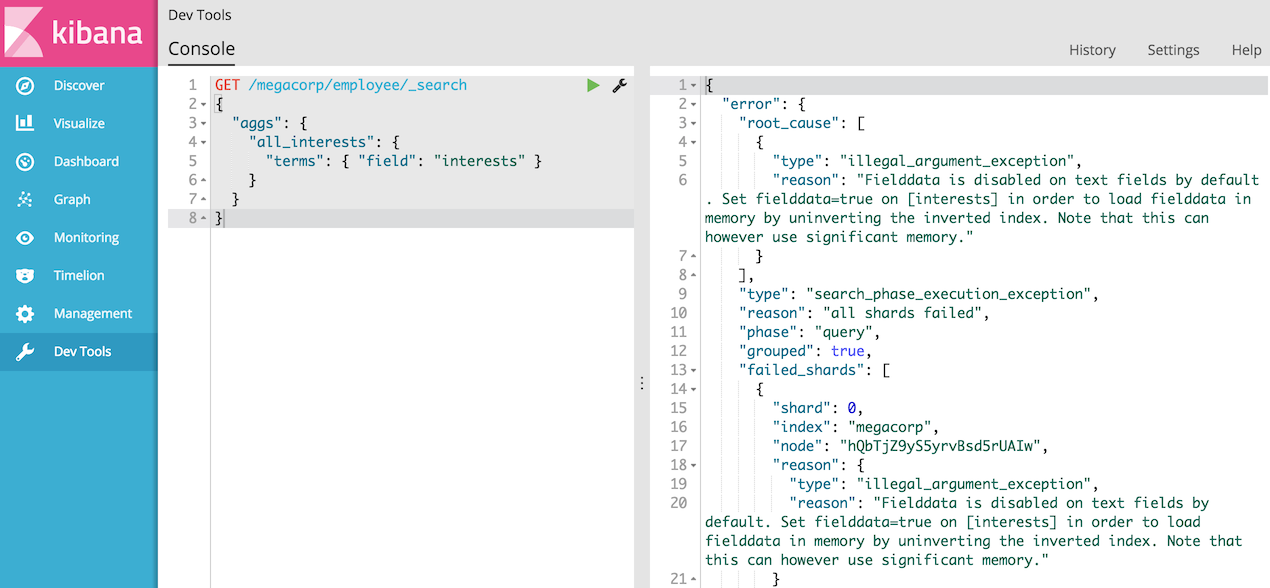
大概的意思是:Fielddata可以消耗大量的堆空间,特别是在加载高基数文本字段时。一旦fielddata已经加载到堆中,它在该段的生存期内保持。此外,加载fielddata是一个昂贵的过程,可以导致用户体验延迟命中。
所以fielddata默认禁用。如果尝试对文本字段上的脚本进行排序,聚合或访问值,就会看到这个异常,具体使用可以参考手册。

