
基础篇
第一章
基础篇
第一章 Python介绍、安装、使用
Python 简介
Python 安装
第一个Python程序
Python 解释器
字符编码与解码
动态语言与静态语言的区别
变量及简单数据类型
编码规范
第一章 Python介绍、安装、使用
Python语言介绍
说到Python语言,就不得不说一下它的创始人Guido van Rossum(1956 -- ?), 他在开发PYTHON语言之前曾使用过几年的ABC语言,ABC是一门主要用于教学目的语言(教计算机系的学生如何设计一门开发语言),Guido 在开发PYTHON时借鉴了很多ABC语言的特性,所以后来人们包括Guido自己也认为,PYTHON语言的前身就是ABC语言。关于创作PYTHON语言的初衷,Guido在1996年写到:
Over six years ago, in December 1989, I was looking for a "hobby" programming project that would keep me occupied during the week around Christmas. My office ... would be closed, but I had a home computer, and not much else on my hands. I decided to write an interpreter for the new scripting language I had been thinking about lately: a descendant of ABC that would appeal to Unix/C hackers. I chose Python as a working title for the project, being in a slightly irreverent mood (and a big fan of Monty Python's Flying Circus).
在六年前的1989.12月份,我为了在圣诞假期打发无聊时间找点事干(估计是写代码找不到对象),决定为我最近一直在构思的一门新的脚本语言写个解释器,这门语言的前身ABC(就Guido本人看来,ABC這種語言非常优美和强大,是专门为专业的程序设计师使用的。但是ABC語言并没有成功,究其原因,吉多认为是非開放造成的。吉多決心在Python中避免這一错误,并取得了非常好的效果,完美结合了C和其他一些語言)语言更多是被UNIX/C黑客使用,我选择PYTHONP这个名字做为这个开发项目的名字,起这个名字的一个原因是因为我是Month Python’s Flying Circus(英国的一个电视喜剧)的超级粉丝。
就这样,python在Guido手中诞生了,它的第一个版本实现是在MAC电脑上,一直在90年代,PYTHON的开放性、语法的简洁性大受很多程序员的喜欢,很多人拿它来快速的开发一些脚本和工具,并不断的向官方提交新的代码和第三方模块,因此PYTHON能做的事情也愈发多了起来,一些大公司像YAHOO、EBAY也开始在生产环境中使用PYTHON。到了2000年10月16号,PYTHON2.0发布了,相比之前的1.x版本,实现了完整的垃圾回收,并且支持UNICODE,同时整个开发过程更加透明,社区对PYTHON的开发进度的影响逐渐增大。从2000年第一个2.0版本发布到写本书的2015止,2.X版本最主流使用的工业版本,虽然PYTHON官方于2008年就发布了Python3.0,但由于此版本并不完全兼容之前的广泛使用的2.4版本,这导致很多基于2.4开发软件跟本无法在3.0的平台 上运行,因此3.0的推广也非常缓慢,为解决这个问题,python官方很快又推出兼容2.4和3.0两个版本的2.6,这个版本兼容了原来的2.4版本,又支持了很多3.0的特性,并且官方还开发了专门的帮助将2.x转为3.0版本的转换工具,因此,python3.0的使用才开始逐渐多了起来,不过,现在主流的工业版本依然是2.6和2.7过渡版本,因此本书主要还是围绕着2.7的版本来学习,不过同学们不用担心,因为2.7支持了非常多3.x版本的特性,等到几年后3.0版本广泛使用时,你由2.x转向3.x会像由 windows xp转向使用win 7一样简单。
再说回Guido, 这哥们现在还掌控着python的发展方向,他于2005年加入谷歌工作,因此也推动了python在谷歌内部实现了广泛使用,2012年,他加入世界上最大的云存储公司Dropbox,该公司产品几乎全部基于python开发,全世界的用户每天在上面分享和上传超过10亿个文件。
Python 是一门什么样的语言?
编程语言主要从以下几个角度为进行分类,编译型和解释型、静态语言和动态语言、强类型定义语言和弱类型定义语言,每个分类代表什么意思呢,我们一起来看一下。
编译型和解释型
我们先看看编译型,其实它和汇编语言是一样的:也是有一个负责翻译的程序来对我们的源代码进行转换,生成相对应的可执行代码。这个过程说得专业一点,就称为编译(Compile),而负责编译的程序自然就称为编译器(Compiler)。如果我们写的程序代码都包含在一个源文件中,那么通常编译之后就会直接生成一个可执行文件,我们就可以直接运行了。但对于一个比较复杂的项目,为了方便管理,我们通常把代码分散在各个源文件中,作为不同的模块来组织。这时编译各个文件时就会生成目标文件(Object file)而不是前面说的可执行文件。一般一个源文件的编译都会对应一个目标文件。这些目标文件里的内容基本上已经是可执行代码了,但由于只是整个项目的一部分,所以我们还不能直接运行。待所有的源文件的编译都大功告成,我们就可以最后把这些半成品的目标文件“打包”成一个可执行文件了,这个工作由另一个程序负责完成,由于此过程好像是把包含可执行代码的目标文件连接装配起来,所以又称为链接(Link),而负责链接的程序就叫……就叫链接程序(Linker)。链接程序除了链接目标文件外,可能还有各种资源,像图标文件啊、声音文件啊什么的,还要负责去除目标文件之间的冗余重复代码,等等,所以……也是挺累的。链接完成之后,一般就可以得到我们想要的可执行文件了。
上面我们大概地介绍了编译型语言的特点,现在再看看解释型。噢,从字面上看,“编译”和“解释”的确都有“翻译”的意思,它们的区别则在于翻译的时机安排不大一样。打个比方:假如你打算阅读一本外文书,而你不知道这门外语,那么你可以找一名翻译,给他足够的时间让他从头到尾把整本书翻译好,然后把书的母语版交给你阅读;或者,你也立刻让这名翻译辅助你阅读,让他一句一句给你翻译,如果你想往回看某个章节,他也得重新给你翻译。
两种方式,前者就相当于我们刚才所说的编译型:一次把所有的代码转换成机器语言,然后写成可执行文件;而后者就相当于我们要说的解释型:在程序运行的前一刻,还只有源程序而没有可执行程序;而程序每执行到源程序的某一条指令,则会有一个称之为解释程序的外壳程序将源代码转换成二进制代码以供执行,总言之,就是不断地解释、执行、解释、执行……所以,解释型程序是离不开解释程序的。像早期的BASIC就是一门经典的解释型语言,要执行BASIC程序,就得进入BASIC环境,然后才能加载程序源文件、运行。解释型程序中,由于程序总是以源代码的形式出现,因此只要有相应的解释器,移植几乎不成问题。编译型程序虽然源代码也可以移植,但前提是必须针对不同的系统分别进行编译,对于复杂的工程来说,的确是一件不小的时间消耗,况且很可能一些细节的地方还是要修改源代码。而且,解释型程序省却了编译的步骤,修改调试也非常方便,编辑完毕之后即可立即运行,不必像编译型程序一样每次进行小小改动都要耐心等待漫长的Compiling…Linking…这样的编译链接过程。不过凡事有利有弊,由于解释型程序是将编译的过程放到执行过程中,这就决定了解释型程序注定要比编译型慢上一大截,像几百倍的速度差距也是不足为奇的。
编译型与解释型,两者各有利弊。前者由于程序执行速度快,同等条件下对系统要求较低,因此像开发操作系统、大型应用程序、数据库系统等时都采用它,像C/C++、Pascal/Object Pascal(Delphi)、VB等基本都可视为编译语言,而一些网页脚本、服务器脚本及辅助开发接口这样的对速度要求不高、对不同系统平台间的兼容性有一定要求的程序则通常使用解释性语言,如Java、JavaScript、VBScript、Perl、Python等等。
但既然编译型与解释型各有优缺点又相互对立,所以一批新兴的语言都有把两者折衷起来的趋势,例如Java语言虽然比较接近解释型语言的特征,但在执行之前已经预先进行一次预编译,生成的代码是介于机器码和Java源代码之间的中介代码,运行的时候则由JVM(Java的虚拟机平台,可视为解释器)解释执行。它既保留了源代码的高抽象、可移植的特点,又已经完成了对源代码的大部分预编译工作,所以执行起来比“纯解释型”程序要快许多。而像VB6(或者以前版本)、C#这样的语言,虽然表面上看生成的是.exe可执行程序文件,但VB6编译之后实际生成的也是一种中介码,只不过编译器在前面安插了一段自动调用某个外部解释器的代码(该解释程序独立于用户编写的程序,存放于系统的某个DLL文件中,所有以VB6编译生成的可执行程序都要用到它),以解释执行实际的程序体。C#(以及其它.net的语言编译器)则是生成.net目标代码,实际执行时则由.net解释系统(就像JVM一样,也是一个虚拟机平台)进行执行。当然.net目标代码已经相当“低级”,比较接近机器语言了,所以仍将其视为编译语言,而且其可移植程度也没有Java号称的这么强大,Java号称是“一次编译,到处执行”,而.net则是“一次编码,到处编译”。呵呵,当然这些都是题外话了。总之,随着设计技术与硬件的不断发展,编译型与解释型两种方式的界限正在不断变得模糊。
动态语言和静态语言
通常我们所说的动态语言、静态语言是指动态类型语言和静态类型语言。
(1)动态类型语言:动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言。
(2)静态类型语言:静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
对于动态语言与静态语言的区分,套用一句流行的话就是:Static typing when possible, dynamic typing when needed。
强类型定义语言和弱类型定义语言
(1)强类型定义语言:强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
(2)弱类型定义语言:数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。另外,“这门语言是不是动态语言”与“这门语言是否类型安全”之间是完全没有联系的!
例如:Python是动态语言,是强类型定义语言(类型安全的语言); VBScript是动态语言,是弱类型定义语言(类型不安全的语言); JAVA是静态语言,是强类型定义语言(类型安全的语言)。
通过上面这些介绍,我们可以得出,python是一门动态解释性的强类型定义语言。那这些基因使成就了Python的哪些优缺点呢?我们继续往下看。
Python能做什么?
Python是一门综合性的语言,你几乎能在计算机上通过Python做任何事情,以下是Python应该最广泛的几个方面:
- 网络应用:包括web网站 、服务器后台服务等,在这方面Python有优秀的web框架如Django\Tornado\Flask等,网络服务框架有著名的Twisted,异步通信有牛X的eventlet.
- 2. 科学运算:随着NumPy、SciPy、matplotlib、ETS等众多程序库的开发,Python越来越适合于做科学计算。与科学计算领域最流行的商业软件MATLAB相比,Python是一门真正的通用程序设计语言,比MATLAB所采用的脚本语言的应用范围更广泛,有更多程序库的支持,适用于Windows和Linux等多种平台,完全免费并且开放源码。虽然MATLAB中的某些高级功能目前还无法替代,但是对于基础性、前瞻性的科研工作和应用系统的开发,完全可以用Python来完成。
- GUI程序:python提供了多个图形开发界面的库,包括PyQt,WxPython,自带的有Tkinter,这些库允许Python程序员很方便的创建完整的、功能健全的GUI用户界面。
- 系统管理工具:Python可以是做运维人员最喜欢用的语言了,可以用它来轻松的开发自动化管理工具、监控程序等,事实上现在很多开源软件也都是用Python开发的,如用于IT配置管理的SaltStack\Ansible, 做虚拟化的OpenStack,做备份用的Bacula等。
- 其它程序:你知道吗?Python 用来写爬虫也是很拿手的,还有做游戏,之前看社区里有个哥们花了不到300行代码就实现了《愤怒的小鸟》的游戏,还可以用来做嵌入式开发、做驱动程序等,总之,Python能做的事情还是非常多的,好好学吧,很快你就会fall in love with this great language!
Python的优缺点
先看优点
- Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是简单易懂,初学者学Python,不但入门容易,而且将来深入下去,可以编写那些非常非常复杂的程序。
- 开发效率非常高,Python有非常强大的第三方库,基本上你想通过计算机实现任何功能,Python官方库里都有相应的模块进行支持,直接下载调用后,在基础库的基础上再进行开发,大大降低开发周期,避免重复造轮子。
- 高级语言————当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节
- 可移植性————由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工 作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就几乎可以在市场上所有的系统平台上运行
- 可扩展性————如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
- 可嵌入性————你可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能。
再看缺点:
- 速度慢,Python 的运行速度相比C语言确实慢很多,跟JAVA相比也要慢一些,因此这也是很多所谓的大牛不屑于使用Python的主要原因,但其实这里所指的运行速度慢在大多数情况下用户是无法直接感知到的,必须借助测试工具才能体现出来,比如你用C运一个程序花了0.1s,用Python是0.01s,这样C语言直接比Python快了10s,算是非常夸张了,但是你是无法直接通过肉眼感知的,因为一个正常人所能感知的时间最小单位是0.15-0.4s左右,哈哈。其实在大多数情况下Python已经完全可以满足你对程序速度的要求,除非你要写对速度要求极高的搜索引擎等,这种情况下,当然还是建议你用C去实现的。
- 代码不能加密,因为PYTHON是解释性语言,它的源码都是以名文形式存放的,不过我不认为这算是一个缺点,如果你的项目要求源代码必须是加密的,那你一开始就不应该用Python来去实现。
- 线程不能利用多CPU问题,这是Python被人诟病最多的一个缺点,GIL即全局解释器锁(Global Interpreter Lock),是计算机程序设计语言解释器用于同步线程的工具,使得任何时刻仅有一个线程在执行,Python的线程是操作系统的原生线程。在Linux上为pthread,在Windows上为Win thread,完全由操作系统调度线程的执行。一个python解释器进程内有一条主线程,以及多条用户程序的执行线程。即使在多核CPU平台上,由于GIL的存在,所以禁止多线程的并行执行。关于这个问题的折衷解决方法,我们在以后线程和进程章节里再进行详细探讨。
当然,Python还有一些其它的小缺点,在这就不一一列举了,我想说的是,任何一门语言都不是完美的,都有擅长和不擅长做的事情,建议各位不要拿一个语言的劣势去跟另一个语言的优势来去比较,语言只是一个工具,是实现程序设计师思想的工具,就像我们之前中学学几何时,有的时候需要要圆规,有的时候需要用三角尺一样,拿相应的工具去做它最擅长的事才是正确的选择。之前很多人问我Shell和Python到底哪个好?我回答说Shell是个脚本语言,但Python不只是个脚本语言,能做的事情更多,然后又有钻牛角尖的人说完全没必要学Python, Python能做的事情Shell都可以做,只要你足够牛B,然后又举了用Shell可以写俄罗斯方块这样的游戏,对此我能说表达只能是,不要跟SB理论,SB会把你拉到跟他一样的高度,然后用充分的经验把你打倒。
Python安装
我觉得这一节是最没什么好讲的了,Python现在已经默认安装在了所有的*nix发行版本上,对于Windows平台,也只需要到Python官网(http://www.python.org)直接下载Windows版本就可以了,但对于版本的选择,可能好多新手会有点困惑,不知道选择2.x or 3.x好,如果你现在还有这个困惑的话,代表你没好好看上面的简介,请回去自己复习,我这里的建议是下载最新的2.x版本使用即可,
除了官方提供的标准Python版本,还有一些其它的用于特定方向的发行版本,比如PyQt主要是用来做GUI图形界面的,可以用来代替Python的Tkinter,其它替代者还有wxPython、PyGTK等,还有PortablePython,是一个免安装的Windows 发行版本,如果你想在不安装任何python环境的情况下就在windows上运行python程序,只需要把PortablePython 拷贝到你的Windows机器上即可。
Python解释器
当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。
由于整个Python语言从规范到解释器都是开源的,所以理论上,只要水平够高,任何人都可以编写Python解释器来执行Python代码(当然难度很大)。事实上,确实存在多种Python解释器。
CPython
当我们从Python官方网站下载并安装好Python 2.7后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
PyPy
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
小结
Python的解释器很多,但使用最广泛的还是CPython。如果要和Java或.Net平台交互,最好的办法不是用Jython或IronPython,而是通过网络调用来交互,确保各程序之间的独立性。
本教程的所有代码只确保在CPython 2.7版本下运行。请务必在本地安装CPython(也就是从Python官方网站下载的安装程序)。
第一个Python程序
好了,前面说了这么多,是时候该进入正题啦,下面我就来写一下第一个Python程序 !
首先找一个版本比较新的Linux系统, 执行Python –V 查看一下你的Python版本,请确保你的Python版本在2.6以下,如果你还能发现2.4的版本的话,那只能说你的系统实在太老了,快换了丫的。
$ python -V
Python 2.7.5
接下来,创建一个文件名为,myFirstPyProgram.py
vi myFirstPyProgram.py
#!/usr/bin/env python
print “Hello,World!”
print “Goodbye,World!”
保存后执行:
$ python myFirstPyProgram.py
Hello,World!
Goodbye, World!
哈哈,第一个程序就这样写完了,让我们一起来看看它每句话的意思:
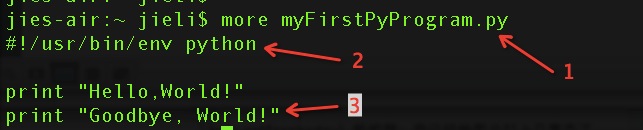
- 所有的Python程序的命名规范都应该以.py结尾,只有这样,别人才能一看你的文件后缀名就知道这是个Python程序。
- 在程序的第一行声明要使用的解释器类型,这句话等于是告诉操作系统要用什么解释器来解释这个程序。写代码的时候一般都建议加上这句,但有的同学说,我不加这句的话,这个程序也是可以运行的唉,没错,如果你不加这句声明,你直接执行python myFirstPyProgram.py 也是可以执行的,这是因为你调用该程序时就已经明确的告诉操作系统要用python来解释这个代码,所以不会出错,但是如果你把myFirstPyProgram.py加上可执行权限,并且把代码的第一行声明去掉,再来执行的话,就会报错了,看下面:

所以,如果确定你的程序会变成可执行文件被调用的话,那么务必要加上解释器声明
3.用print 语法将后面的字符串打印到屏幕上,和shell脚本的echo、java和c的printf是一个意思噢。
写个猜年龄的小程序
刚才我们写了学习任何一门语言都要先写的仪式感很强的HelloWorld程序,感觉是不是有点太简单了?哈,那我们做一个稍微深入点的,需求如下:
我们在程序中先给一个人定义好年龄,然后让用户去猜测,用户输入他猜测的数字后,我们再来判断他猜测的是否正确。
好的,我先来直接上代码:

- 先定义一个正确答案的变量,那什么是变量呢?变量就可变的量啊,就是我们先在内存里开辟一块空间,并给这块空间赋一个名称就是变量名,后面的29呢就是我们往这个空间里存的数据啦,以后我们想再调用这个数据的话,直接通过这个变量名就可以找到了哈。
- 首先看3所指向的raw_input(“Please input your guess num:”),这句代码在执行的时候会在屏幕上弹出“Please input your guess num:”并等待着用户输入,你不输入它可就一直在那等着呀,等你到天荒地老,但我们的需求是要求用户输入一个数字,并拿这个数字跟我前面定义的right_age_num变量进行对比,所以,在这里你输入了个数字后,计算机得把它先存到内存,然后才能再跟之前定义的right_age_num变量做对比,因此,我在这里把用户输入的值赋值给了变量usre_guess_num. 好,这里明白了之后,我们再来看2所指向的int(),这是个啥意思呢?这是python的内置函数(函数是什么现在你不需要了解),它做的事情就是把用户输入的值转成int类型,int就是指整数类型,这样我们才能进行2个数字之前的对比呀?那你可能要问了,我刚才明明是已经输入了数字了呀,为什么还要多此一举再转换一次呢?呵呵,这里要注意的是,raw_input()这个函数默认都会把接收到的用户输入变成字符串,无论你输入的是不是数字,都统统当成字符串来处理啦,所以我们这里需要转换一下。好的,如果这里还不明白,就先假装懂了,我们稍后再讲数据类型的时候你就彻底明白了。
- 擦,上边的老二把我的台词都说了,我没啥好补充的了,过。
- 这个if else 是啥意思呢,其实就是最简单的条件判断,如果if 后面的 条件成立,就执行它下面作用域中的代码,如果不成立呢,就执行else后面的代码。也就是,要么就执行if 作用域下的代码,要么就执行else作用域下的代码,反正绝对不会出现这两个作用域同时执行的情况。那么哪些才算是if 的作用域呢?瞪大眼睛看到4指向的:号没有,再往下一行就直接换行了,并且缩进了2格又开始了print代码,那这一行的print 就算是if 的作用域喽。这里要引出的概念你要消化下,就是python是强制缩进的,啥意思?就是指你每开始一个新的作用域,都要进行一次强制缩进,并且同一级别的作用域的代码缩进还必须要保持一致,不能这一行缩进2空格,下一行还是跟我同一级别的代码却缩进了4个空格,这样会报错。如果你写过其它的语言就会发现大多数语言都不要求强制缩进,只有python这么干,这么干其实也是Guido的一片苦心,通过强制缩进,你能很清晰的看轻整个程序的逻辑层次,保证了语言的简洁和明确性,也就是说,Python 是通过缩进来区分作用域的。没关系,写的多了你就习惯了,这里有聪明的同学要问了,其它的语言不用缩进的话,那是如何区分作用域的呢?Good question, 其它语言是通过起始和关闭符来确定一个作用域的开始和结束的,比如下的面JavaScript代码:
if (var1 == var2 ){
console.log(‘yes,var1 equals to var2’);
}else{
alert(‘no ,they are not equal.’);
}
看到上面的那么多大括号了么,没错,就是通过大括号来确定作用域的,所以他们不强制缩进。
- 再来看5指向的是一个逗号,代表要同时打印多个值,输出时会用空格将2个值分开显示。
- 6指向的也是:号,代表开始一个新的作用域,噢,刚才忘记说了,你发现没有,python 是只有作用域的起始标志冒号,但却没有关闭符对不对?没错,Python只能通过缩进来确定作用域是否关闭了,So,写代码的时候一定不要犯缩进错误噢。
Python的变量及数据类型
上面猜测用户年龄的程序中已经涉及到了变量、数据类型的概念,有些小伙伴可能还晕圈呢,我们下面再来详细介绍下
数据类型
一个程序要运行,就要先描述其算法。描述一个算法应先说明算法中要用的数据,数据以变量或常量的形式来描述。每个变量或常量都有数据类型。Python的基本数据类型有5种: 整型(int), 浮点型(float), 字符型(string), 布尔型(bool),空值(None).
整数
Python可处理任意大小的整数,在程序中的表示方法和数学上的写法完全一样。
浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x109和12.3x108是相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差。
字符串
字符串是以''或""括起来的任意文本,比如'abc',"xyz"等等。请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这3个字符。如果'本身也是一个字符,那就可以用""括起来,比如"I'm OK"包含的字符是I,',m,空格,O,K这6个字符。
如果字符串内部既包含'又包含"怎么办?可以用转义字符\来标识,比如:
'I\'m \"OK\"!' 表示的字符串内容是:
I'm "OK"! 转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\,可以在Python的交互式命令行用print打印字符串看看:
>>> print 'I\'m ok.' I'm ok. >>> print 'I\'m learning\nPython.' I'm learning Python. >>> print '\\\n\\' \ \ 如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r''表示''内部的字符串默认不转义,可以自己试试:
>>> print '\\\t\\' \ \ >>> print r'\\\t\\' \\\t\\ 如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容,可以自己试试:
>>> print '''line1 ... line2 ... line3''' line1 line2 line3 上面是在交互式命令行内输入,如果写成程序,就是:
print '''line1 line2 line3''' 多行字符串'''...'''还可以在前面加上r使用,请自行测试。
布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来:
>>> True True >>> False False >>> 3 > 2 True >>> 3 > 5 False 布尔值可以用and、or和not运算。
and运算是与运算,只有所有都为True,and运算结果才是True:
>>> True and True True >>> True and False False >>> False and False False or运算是或运算,只要其中有一个为True,or运算结果就是True:
>>> True or True True >>> True or False True >>> False or False False not运算是非运算,它是一个单目运算符,把True变成False,False变成True:
>>> not True False >>> not False True 布尔值经常用在条件判断中,比如:
if age >= 18: print 'adult' else: print 'teenager' 空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
此外,Python还提供了列表、字典等多种数据类型,还允许创建自定义数据类型,我们后面会继续讲到。<引用2>
变量和常量
在计算机中,变量就是用来在程序运行期间存储各种需要临时保存可以不断改变的数据的标识符,一个变量应该有一个名字,并且在内存中占据一定的存储单元,在该存储单元中存放变量的值。请注意区分变量名和变量值这两个不同的概念,看下图:
变量命名规则
先介绍标识符的概念。和其他高级语言一样,用来标识变量、符号常量、函数、数组、类型等实体名字的有效字符序列称为标识符(identifier)。简单地说,标识符就是一个名字。变量名是标识符的一种,变量的名字必须遵循标识符的命名规则。
Python语言和java,c++等很多语言一样,规定标识符只能由字母、数字和下划线3种字符组成,且第一个字符必须为字母或下划线。下面列出的是合法的标识符,也是合法的变量名:
sum, average, total, day, month, Student_name, tan, BASIC, li_ling
下面是不合法的标识符和变量名:
M.D.John, $442, #4, 3G64, Alex Li, C++, Zhang-ling,姓名, U.S.A.
注意:在Python中,大写字母和小写字母被认为是两个不同的字符。因此,sum和SUM是两个不同的变量名。一般地,变量名用小写字母表示,与人们日常习惯一致,以增加可读性。应注意变量名不能与Python的关键字、系统函数名和类名相同。
变量名命名习惯
当你的代码越写越多的时候,你会发现你定义的变量也会越来越多,为了增加代码的易读性和方便调试,给变量起名时一定要遵循一定的命名习惯,你起的变量名称最好能让人一眼就大概知道这个变量是干什么用的,比如,getUserName一看就知道,这个变量应该是要获取用户的姓名,check_current_conn_count代表是要检查现在的连接数,只有这样,别人才能在看你的代码时知道你的这些变量的作用,而如果你把变量名全起成了var1,var2,var3…..varN,那别人再看你的代码时会骂死你的。
变量名的定义在能表达清楚它的作用的前提下最越简洁越好,能用一个单词表述清楚的尽量就不要用两个。变量起名时一般有这么几种写法,你觉得哪种最简洁,你就选哪种吧。
CheckCurrentConnCount
check_current_conn_count
checkCurrentConnCount
不好的起名:
CHECKCURRENTCONNCOUNT
Var1 var2 var3 varN
Checkcurrentconncount
定义变量
了解了变量的概念和用途后,我们一起来定义几个简单的变量看一下
name = ‘Alex Li’ #name 是字符串,字符串要加上引号噢
age = 29 #age 是整数,整数不要加引号,加了引号后就变成字符串了
has_girlfriend = False #是布尔值,一般用这个做逻辑判断,如if has_girlfriend:print ‘good for you !’
age = age + 1 #这个结果应该是30,运算流程是先将=号后面的age +1结果算出,然后再把这个结果重赋值给age, 由于age之前的值是29,重新赋值后,age值变为30.
最后,理解变量在计算机内存中的表示也非常重要。当我们写:
name = 'Alex'
时,Python解释器干了两件事情:
- 在内存中创建一个”Alex”的字符串;
- 在内存中创建了一个名为name的变量,并把它指向”Alex”的内存地址。
也可以变量name赋值给另一个变量name2,这个操作实际上是把变量name2指向的数据,例如:
唉?不是已经把name2 等于name变量了吗?name 值改了以后,name2不跟着改吗?没错,当name 的值由”Alex”改成”Jack”后,name2还是指向原来的”Alex”,我们来一步步分析一下:
1. 定义name=”Alex”,解释器创建了字符串”Alex”和变量name,并把name指向了”Alex”
2. 执行name2=name,解释器创建了name2变量,并把name2指向了name变量所指向的字符串
3. 这时通过id内置函数来查看一下这两个变量分别指向的内存地址,结果都是指向了同一地址。
4. 执行name=”Jack”,解释器创建一个新的变量”Jack”,并把name的指向改成了”Jack”
5. 此时再查看两个变量的内存地址指向就会发现,name的指向已经变成了一个新的地址,也就是”Jack”所在内存地址,但是name2依然还是指向原来的”Alex”。
Now, 你明白了吗? 再总结一下,当你把一个变量name赋值给另一个变量name2时,解释器只是把name变量所指向的内存地址赋值给了name2,因此name 和 name2并未发生直接的关联,只不过是他们都同时指向了同一个内存地址而已,这也就是为什么你把name再指向一个新地址后,而name2的值还保持不变的原因。
常量
刚才说到了变量,还有一概念就是常量,所谓常量就是不能变的变量,比如常用的数学常数π就是一个常量。在Python中,通常用全部大写的变量名表示常量:
PI = 3.14159265359
但事实上PI仍然是一个变量,Python根本没有任何机制保证PI不会被改变,所以,用全部大写的变量名表示常量只是一个习惯上的用法,如果你一定要改变变量PI的值,也没人能拦住你。
数据运算符
和其它语言一样,python也支持进行各种各样的数学和逻辑运算,我们一起来看一些。
python语言支持以下几种运算
算术运算
比较运算
Assignment Operators
二进制运算
关系运算
验证运算
算术运算
以下例子a = 10 , b= 20
|
运算符 |
描述 |
示例 |
|
+ |
加法运算 |
a + b 得 30 |
|
- |
减法运算 |
a - b 得 -10 |
|
* |
乘法运算 |
a * b 得 200 |
|
/ |
除法运算 |
b / a 得 2 |
|
% |
取模 - 将%号左边的值除以%号右边的值并且将得到的结果的余数返回 |
10%5得0 ,10%3 得1, 20%7 得6 |
|
** |
幂 - 返回x的y次幂,就是返回多少次方 |
2**8 得256 |
|
// |
取整除 - 返回x除以y的商的整数部分 |
9//2得4 , 9.0//2.0得4.0 |
比较运算
以下例子a = 10 , b= 20
|
运算符 |
描述 |
示例 |
|
== |
判断两个对象是否相等 |
(a == b) is not true. |
|
!= |
判断两个对象是否不相等 |
(a != b) is true. |
|
<> |
判断两个对象是否不相等 |
(a <> b) is true. 与 != 运算符一样. |
|
> |
大于 - 返回a是否大于b |
(a > b) is not true. |
|
< |
小于 - 返回a是否小于b |
(a < b) is true. |
|
>= |
大于等于 - 返回a 是否大于等于b |
(a >= b) is not true. |
|
<= |
小于等于 - 返回a 是否小于等于b |
(a <= b) is true. |
赋值运算
|
运算符 |
描述 |
示例 |
|
= |
赋值 - 将右边的值赋值给左边的变量名 |
c = a + b 将会把a+b的结果赋值给c |
|
+= |
自加赋值 - 将+=号左边的值与+=号右边的值相加,然后再把结果赋值给+=号左右的值 |
c += a相当于 c = c + a |
|
-= |
自减赋值 |
c -= a相当于 c = c - a |
|
*= |
自乘赋值 |
c *= a 相当于 c = c * a |
|
/= |
自除赋值 |
c /= a 相当于 c = c / a |
|
%= |
自取模赋值 |
c %= a 相当于 c = c % a |
|
**= |
自求幂赋值 |
c **= a 相当于 c = c ** a |
|
//= |
自取整赋值 |
c //= a 相当于 c = c // a |
按位运算(二进制运算)
我们都知道,计算机处理数据的时候都会把数据最终变成0和1的二进制来进行运算,也就是说,计算机其实只认识0和1, 那按位运算其实就是把数字转换成二进制的形式后再进行位运算的,唉呀,说的好迷糊,直接看例子,我们设定a=60; b=13; 要进行位运算,就得把他们先转成2进制格式,那0和1是如何表示60和13的呢?学过计算机基础的人都知道,计算机最小的存储单位是字节,也就是说一个数字、一个字母最少需要用一个字节来存储,然后呢,一个字节又由8个2进制位来表示,也就是8bit,所以呢,一个计算机中最小的数据也需要用一个字节来存储噢。那为是什么8位而不是9位、10位、20位呢?这个问题上学的时候应该都讲过,不明白的自己网上查下吧再。8个二进制如何表示60这个数字呢?聪明的计算机先人们想到了用占位的方式来轻松的实现了,怎么占位呢?如下表所示,我们把8个二进制位依次排列,每个二进制位代表一个固定的数字,这个数字是由2的8次方得来的,即每个二进制位代表的值就是2的第几次方的值,8个二进制位能表示的最大数是2**8=256, 那把60分解成二进制其实就是以此在这8位上做个比对,只要把其中的几位相加,如果结果正好等于60,那这个位就找对了,首先看60 肯定占不了128和64那两位,不占位就设为0,后面的32+16+8+4=60,所以这几位要设置为1,其它的全设置为0,13的二进制算法也是一样的。
|
二进制位数 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
|
每位所代表的数字 |
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
|
60 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
|
13 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
好,知道了10进制如何转2进制了之后,我们接着来看,如果进行2个10进制数字的位运算
|
运算符 |
描述 |
示例 |
|
& |
与运算,这个二进制位必须在2组数中都为真,结果才返回真 |
(a & b)得12,二进制位: 0000 1100 |
|
| |
或运算,这个二进制位只需在其中一组数据中为真即返回真 |
(a | b)得 61,二进制位: 0011 1101 |
|
^ |
异或运算,只要这个二进制位在两组数据中不相同就返回真 |
(a ^ b)得 49 ,二进制位: 0011 0001 |
|
<< |
左移运算,将a整体向左移2位 |
a << 2得240,二进制位: 1111 0000 |
|
>> |
右移运算,将a整体向左移3位 |
a >> 3得 7 ,二进制位: 0000 0111 |
看下面的运算过程:
|
二进制位 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
结果 |
|
每位所代表的数字 |
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
|
|
60 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
|
|
13 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
|
|
&与运算 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
12 |
|
|或运算 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
1 |
61 |
|
^异或运算 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
49 |
|
a<<2 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
240 |
|
a>>3 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
7 |
后面还有
逻辑运算符 and 、or 、not
关系运算符 in 、not in
验证运算符 is 、 is not
因为我们现在还没有学流程控制相关的,现在说这些反而会让你迷惑,先忘掉这几个吧,以后我们用到的时候你自然就会明白了哈。
字符编码 <引用3>
我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
|
字符 |
ASCII |
Unicode |
UTF-8 |
|
A |
01000001 |
00000000 01000001 |
01000001 |
|
中 |
x |
01001110 00101101 |
11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
Python的字符串
搞清楚了令人头疼的字符编码问题后,我们再来研究Python对Unicode的支持。
因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串'ABC'在Python内部都是ASCII编码的。Python提供了ord()和chr()函数,可以把字母和对应的数字相互转换:
>>> ord('A') 65 >>> chr(65) 'A' Python在后来添加了对Unicode的支持,以Unicode表示的字符串用u'...'表示,比如:
>>> print u'中文'中文>>> u'中' u'\u4e2d'
写u'中'和u'\u4e2d'是一样的,\u后面是十六进制的Unicode码。因此,u'A'和u'\u0041'也是一样的。
两种字符串如何相互转换?字符串'xxx'虽然是ASCII编码,但也可以看成是UTF-8编码,而u'xxx'则只能是Unicode编码。
把u'xxx'转换为UTF-8编码的'xxx'用encode('utf-8')方法:
>>> u'ABC'.encode('utf-8') 'ABC' >>> u'中文'.encode('utf-8') '\xe4\xb8\xad\xe6\x96\x87'
英文字符转换后表示的UTF-8的值和Unicode值相等(但占用的存储空间不同),而中文字符转换后1个Unicode字符将变为3个UTF-8字符,你看到的\xe4就是其中一个字节,因为它的值是228,没有对应的字母可以显示,所以以十六进制显示字节的数值。len()函数可以返回字符串的长度:
>>> len(u'ABC') 3 >>> len('ABC') 3 >>> len(u'中文') 2 >>> len('\xe4\xb8\xad\xe6\x96\x87') 6
反过来,把UTF-8编码表示的字符串'xxx'转换为Unicode字符串u'xxx'用decode('utf-8')方法:
>>> 'abc'.decode('utf-8') u'abc' >>> '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') u'\u4e2d\u6587' >>> print '\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')中文
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python # -*- coding: utf-8 -*- 第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
格式化
最后一个常见的问题是如何输出格式化的字符串。我们经常会输出类似'亲爱的xxx你好!你xx月的话费是xx,余额是xx'之类的字符串,而xxx的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
>>> 'Hello, %s' % 'world' 'Hello, world' >>> 'Hi, %s, you have $%d.' % ('Michael', 1000000) 'Hi, Michael, you have $1000000.' 你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
|
%d |
整数 |
|
%f |
浮点数 |
|
%s |
字符串 |
|
%x |
十六进制整数 |
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
>>> '%2d-%02d' % (3, 1) ' 3-01' >>> '%.2f' % 3.1415926 '3.14' 如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True) 'Age: 25. Gender: True' 对于Unicode字符串,用法完全一样,但最好确保替换的字符串也是Unicode字符串:
>>> u'Hi, %s' % u'Michael' u'Hi, Michael' 有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7 'growth rate: 7 %' 小结
由于历史遗留问题,Python 2.x版本虽然支持Unicode,但在语法上需要'xxx'和u'xxx'两种字符串表示方式。
Python当然也支持其他编码方式,比如把Unicode编码成GB2312:
>>> u'中文'.encode('gb2312') '\xd6\xd0\xce\xc4'
Try
但这种方式纯属自找麻烦,如果没有特殊业务要求,请牢记仅使用Unicode和UTF-8这两种编码方式。
在Python 3.x版本中,把'xxx'和u'xxx'统一成Unicode编码,即写不写前缀u都是一样的,而以字节形式表示的字符串则必须加上b前缀:b'xxx'。
格式化字符串的时候,可以用Python的交互式命令行测试,方便快捷。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号