函数
2.全局变量和局部变量
约定俗成:全局变量变量名大写,局部变量变量名小写
命名空间:
存放变量名字的内存地址,其中绑定着对应值的映射关系,字典的方式,因为有个命名空间,所以才有了变量的作用域,比如一个函数就有自己独立的命名空间。
总的可分为有3类:
- locals 函数内的名称空间,局部变量和形参
- globals 全局变量的命名空间 比如函数定义所在模块的名字空间
- builtins 内置模块的名字空间 比如len
作用域的查找顺序
LEGB
- L:locals 当前
- E:enclosing 相邻的上一级
- G:globls
- B:builtins
# 全局变量 ,顶头写,没有缩进,整个文件里面都生效,在最外面循环、条件等里面定义的也为全局
name='lhf'
li = '全局变量'
def change_name():
global name
# 声明name是全局变量,可读取和赋值。如果没有声明直接赋值,就默认为局部变量,
# 如果没有申明就对变量内容追加、修改或者删除操作,会反复向上级寻找,直到找到在操作,
# 全局变量global(上级变量nonlocal),申明必须写在对应赋值语句前面
name='帅了' # 全局变量
li = ‘哈哈’ #局部变量,里面调用的时候屏蔽了全局变量
print(name,li)
以下情况会报错
li = [1,2,3,4,5]
def printMyLi():
print(li)
li = ['a','b','c']
printMyLi()
# UnboundLocalError: local variable 'li' referenced before assignment
change_name()
print(name,li)
# 优先读取局部变量,能读取全局变量,
# 无法对全局变量重新赋值(除非之前声明为global),但是对于可变类型,可以对内部元素进行操作
name = "刚娘"
def weihou():
name = "陈卓"
def weiweihou():
nonlocal name # nonlocal,指定上一级变量,如果没有就继续往上直到找到为止
name = "冷静" #如果没有声明nonlocal,非定义的操作,往外层寻找变量
weiweihou()
print(name)
print(name)
weihou()
print(name)
# 刚娘
# 冷静
# 刚娘
3.函数及变量
egon老师的风湿理论
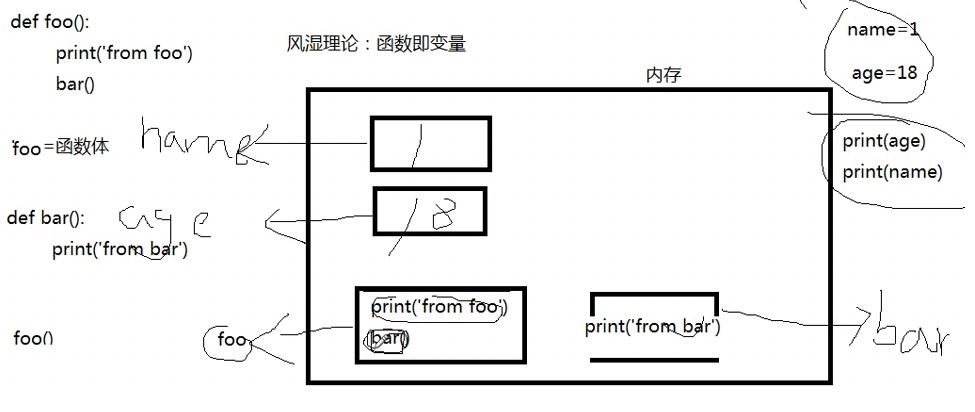
# 向前引用
def foo():
print('from foo')
bar()
foo() # 报错
def bar():
print('from bar')
-----------------------
def bar():
print('from bar')
def foo():
print('from foo')
bar()
foo() # 不报错
------------------------
def foo():
print('from foo')
bar()
def bar():
print('from bar')
foo() # 不报错
----------------------
4.递归函数
递归特性:
- 必须有一个明确的结束条件
- 每次进入更深一层的递归时,问题规模都应有所减小
- 递归效率不高,层次过多会导致栈溢出
示例:汉诺塔问题,将a上的盘子移动到c盘,可通过b盘,每次只移动一次,不管何时每个柱子上面小盘永远在上面
import time
count = 0
a = "A"
b = "B"
c = "C"
def towerOfHanoi(n,a,b,c):
global count
if n == 0:
return
else:
towerOfHanoi(n - 1,a,c,b) #之前的人想法将A上当前之上所有的盘子通过C转到B
print("Move %s to %s" % (a, c)) #当前人移动A盘到C
towerOfHanoi(n - 1,b,a,c) #之后的人想法将B上所有的盘子通过A转到C
count += 1
n = int(input("请输入需要移动的盘子个数\n>>>"))
towerOfHanoi(n,a,b,c)
print("总共移动步骤:",count)
res=time.sleep(10) #休眠功能,默认按照秒计算
print('----------->')
递归练习
一、深度查询
-
- 打印所有的节点
-
- 输入一个节点名字,沙河, 你要遍历找,找到了,就打印它,并返回true
def print_point(location):
if not location:
return
for i in location:
print(i["text"])
if i["children"]:
print_point(i["children"])
def find_point(location,flag,text):
if not location:
return flag
for i in location:
if i["text"] == text:
flag = True
return flag
if not flag and i["children"]:
return find_point(i["children"],flag,text)
if not i["children"]:
return flag
menus = [
{
'text': '北京',
'children': [
{'text': '朝阳', 'children': []},
{'text': '昌平', 'children': [
{'text': '沙河', 'children': []},
{'text': '回龙观', 'children': []},
]},
]
},
{
'text': '上海',
'children': [
{'text': '宝山', 'children': []},
{'text': '金山', 'children': []},
]
}
]
print_point(menus)
print(find_point(menus,False,"123"))
二、二分法算法查找实现
def find_number(data,object_data,first_flag,end_flag):
mind_flag = int((first_flag + end_flag) / 2)
if object_data == data[mind_flag]:
return mind_flag
if first_flag == end_flag or first_flag +1 == end_flag:
return None
if object_data < data[mind_flag]:
return find_number(data,object_data,first_flag,mind_flag - 1)
else:
return find_number(data,object_data,mind_flag,end_flag)
data = [1,3,5,7,8,9,12,13,14,15,23,24,25,36,39]
print(find_number(data,23,0,len(data) - 1))
5.函数的作用域
函数的作用域只跟函数声明时定义的作用域有关,跟函数的调用位置无任何关系,考虑作用域的时候,结合风湿理论,将函数看做变量(局部作用与全局作用,但不能申明globle nunlocal),function() 表示执行函数,name = function表示将函数的地址赋值给name,执行name()也可以调用函数
def test1():
print('in the test1')
def test():
print('in the test')
return test1 # 返回函数的内存地址(加括号是运行)
print(test)
res=test()
print(res()) # test1()
# ---------------------------
name = 'alex'
def foo():
name='linhaifeng'
def bar():
# name='wupeiqi'
print(name)
return bar
a=foo()
print(a)
a() # bar()
# -----------------------------
name = 'alex'
def t1():
name = t1
print(name)
def t2():
name = t2
print(name)
def t3():
name = t3
print(name)
return t1
return t3
return t2
s = t1
print(s()()())
6.匿名函数
lambda 形参:返回值
匿名函数语法(一般和其他函数一起使用,不会单独使用),只能返回一个值(def定义的函数会将多个返回值处理成一个元组)
t = lambda x:x + "_sb"
print(t("alex"))
name = "alex"
t = lambda :name + "_sb"
print(t())
7.函数式编程介绍
编程方法论
- 面向过程:
- 面向对象:
- 函数式:编程语言定义的函数+数学意义上的函数(特有的风格)
- 一、不可变数据
- 函数中不用变量保存状态,不修改变量
- 二、第一类对象
- 函数及变量
- 高阶函数 1:函数接收的参数是一个函数名 2:返回值中包含函数
def foo(n): # n=bar
print(n)
def bar(name):
print('my name is %s' %name)
foo(bar) # 把函数当作参数传给另外一个函数
foo(bar())
foo(bar('alex'))
-------------------------------------------
def bar():
print('from bar')
def foo():
print('from foo')
return bar #返回值中包含函数
n=foo()
n()
------------------------------------------
def hanle():
print('from handle')
return hanle #返回值中包含函数
h=hanle()
h()
三、尾调用优化(尾调用递归优化)
在函数的最后一步调用另外一个函数(不一定是最后一行)
def test():
print("from test")
def test1():
print('from test1')
test() #当调用这个函数的时候(最后一步),接下来也没有操作,所以当前函数状态不保存
def test2():
print('from handle')
return test1() #!!这种情况当前函数也会被释放
def test3():
print(“”)
return test1() + 1 # 不会释放
8.map函数
map函数是遍历操作,对每个元素进行操作!
格式:new_variable = map(函数名,可迭代对象) 函数名可以用匿名函数或者其他定义的函数名(py2中返回的是列表)
num_l=[1,2,10,5,3,7] # 实现里面的元素的平方
ret=[] # for循环实现
for i in num_l:
ret.append(i**2)
print(ret)
# --------------------------------------------
def map_test(array): # 用函数实现
ret=[]
for i in num_l:
ret.append(i**2)
return ret
ret=map_test(num_l)
print(ret)
# ----------------------------------------
#终极版本(相当于map函数的原理)
def map_test(func,array): # func=lambda x:x+1 arrary=[1,2,10,5,3,7]
ret=[]
for i in array:
res=func(i) # add_one(i)
ret.append(res)
return ret
num_l=[1,2,10,5,3,7]
print(map_test(lambda x:x+1,num_l))
# -----------------------------------
# 最终用法!
res=map(lambda x:x+1,num_l)
print('内置函数map,处理结果',res)
num_l = [1,2,3,4,5,6]
def reduce_one(item):
return item - 1
print('传的是有名函数',list(map(reduce_one,num_l)))
msg='linhaifeng'
print(list(map(lambda x:x.upper(),msg)))
l=[1,2,3,4,5]
print(list(map(str,l))) #将列表里面的每个元素转换为字符串
8.filter函数
filter函数是过滤函数
#终极版本
movie_people=['alex_sb','wupeiqi_sb','linhaifeng','yuanhao_sb']
#def sb_show(n):
# return n.endswith('sb')
#--->lambda n:n.endswith('sb')
def filter_test(func,array):
ret=[]
for p in array:
if func(p):
ret.append(p)
return ret
res=filter_test(lambda n:n.endswith('sb'),movie_people)
print(res)
# ------------------------------------------------------
#filter函数使用方法
movie_people=['alex_sb','wupeiqi_sb','linhaifeng','yuanhao_sb']
res=filter(lambda n:n.endswith('sb'),movie_people)
print(list(res))
print(list(filter(lambda n: n.endswith('sb'),movie_people)))
8.reduce函数
原理:
num_l=[1,2,3,100]
def reduce_test(array):
res=array.pop(0)
for num in array:
res+=num
return res
print(reduce_test(num_l))
# num_l=[1,2,3,100]
# def reduce_test(func,array):
# res=array.pop(0)
# for num in array:
# res=func(res,num)
# return res
#
# print(reduce_test(lambda x,y:x*y,num_l))
#最终版本
num_l=[1,2,3,100]
def reduce_test(func,array,init=None):
if init is None:
res=array.pop(0)
else:
res=init
for num in array:
res=func(res,num)
return res
print(reduce_test(lambda x,y:x*y,num_l,100))
reduce函数使用方法
from functools import reduce # 需要导入模块
num_l=[1,2,3,100]
print(reduce(lambda x,y:x+y,num_l,1))
print(reduce(lambda x,y:x+y,num_l))
9.map reduce filter函数总结
处理序列中的每个元素,得到的结果是一个‘列表’,该‘列表’元素个数及位置与原来一样
map(lambda n:n ** 2,(1,2,3,4,5))
filter遍历序列中的每个元素,判断每个元素得到布尔值,如果是True则留下来
people=[
{'name':'alex','age':1000},
{'name':'wupei','age':10000},
{'name':'yuanhao','age':9000},
{'name':'linhaifeng','age':18},
]
print(list(filter(lambda p:p['age']<=18,people)))
reduce:处理一个序列,然后把序列进行合并操作
from functools import reduce
print(reduce(lambda x,y:x+y,range(100),100))
print(reduce(lambda x,y:x+y,range(1,101)))
10. 常用的内置函数
a = [1,2,3,4,5]
b = 998
print(all(a)) # 判断可迭代对象,全为True结果为True
print(any((1,[]))) # 判断可迭代对象,只要一个True,结果都为True
print(dir()) # 打印当前程序所有变量
print(dir(dict)) # 打印一个对象中的所有属性名
print(hex(b)) # 10进制转换成16进制
print(oct(b)) # 十进制变八进制
print(bin(b)) # 二进制
print(chr(3)) # 找出数字相关的ascii符号
print(ord('a')) # 显示ascii对应的数字
print(ascii("adfawefa三大")) # Return an ASCII-only representation of an object.
print(divmod(2,3)) # Return the tuple (x//y, x%y)求除数的整数部分和小数部分
d = {}
for i in range(5):
d[i] = -i
print(d.items()) # items将字典里面的键值对弄成一个元组
print(sorted(d.items())) # sorted() #排序
print(sorted(d.items(),key=lambda x:x[1])) # sorted() # 指定key进行排序
print(sorted(d.items(),key=lambda x:x[1],reverse=True)) # 指定key进行排序并反转
# enumerate(iterable,parm) 将可迭代对象进行编序,默认从0开始,
for i,k in enumerate(d.values(),1):
print(i,k)
# eval
msg = '4 ** 5'
print(eval(msg)) # 将字符串转换 单行代码 计算式 元组 字典 列表 有返回值
a = '1.1'
print(eval(a)) #将字符串提取内容转换为int
b= '[1,2,3]'
print(eval(b)) #将字符串提取内容转换为list
c = '(1,2,3)'
print(eval(c)) #将字符串提取内容转换为tupe
d = '{1:1,2:2,3:3}'
print(eval(d)) #将字符串提取内容转换为dict
e = '{1,2,3}'
print(eval(e)) #将字符串提取内容转换为set
f = '1,2,3,4'
print(eval(f)) #将字符串提取内容自动转换为tupe
g = '1+2 * 3 -2 / (-1 -1)'
print(eval(g)) #将字符串提取内容转换为四则运算
"""交互器写多行代码的方法
code = '''
pass
'''
"""
# exec() # 能将多行字符串转换成代码,没有返回值
code = """
for i in range(5):
print(i)
"""
exec(code)
# isinstance() 判断是否为相关的对象
print(isinstance(1,int)) #判断对象是否为类的实例
print(isinstance('abc',str))
print(isinstance([],list))
print(isinstance({},dict))
print(isinstance({1,2},set))
# sum() # 求和
d = [1,2,3,4,5]
print(sum(d))
# bytearray() 高级玩儿法,可以原内存修改地址,
s = "ABC哈哈大圣"
s = s.encode("utf8")
s = bytearray(s)
s[0] = 97
print(s[5])
s[5] = 137
s = s.decode("utf8")
print(s)
# map filter reduce函数
map_ = list(map(lambda x:x**2,[1,2,3,4,5,6,7,8]))
filter_ = list(filter(lambda x:x % 2 == 0,[1,2,3,4,5,6,7,8]))
import functools
reduce_ = functools.reduce(lambda x,y:x + y,[1,2,3,4,5,6,7,8],2) # 最后一个参数2为初始值
print(map_)
print(filter_)
print(reduce_)
print("海峰","杠娘",sep="->") # sep指定分割的符号
print("海峰","杠娘",end="->") # end指定以什么结束
with open("print.txt","w",encoding="utf8") as f:
print("海峰", "杠娘", sep="->",end="|",file=f) # 边打印边写入文件
# callable(a) 判断是否可调用,是否是函数
def a():
pass
print(callable(a))
f = frozenset(s) # 不可变集合
locals() # 函数的局部变量
globals() # 全局变量
repr(a) # 返回规范化的字符串表示该对象的方法 ??
# zip将两个可迭代对象打包成一个对应元素的元组列表
print(list(zip([0,1,2,3],["a","b","c","d"])))
# compile('print.txt') # Compile source into a code object that can be executed by exec() or eval()
complex(3,5) # 复数
round(2.35434,3) # 保留几位小数
print(abs(-1)) # 取绝对值
name='你好'
print(bytes(name,encoding='utf-8')) # 转换为字节,py3把除非Unique编码的汉字全部以16进制表示
print(bytes(name,encoding='utf-8').decode('utf-8')) # 先编码,再解码
# hash() 哈希
# 可hash的数据类型即不可变数据类型,不可hash的数据类型即可变数据类型哈希运算(预防篡改)
print(hash('12sdfdsaf31231asdfasdfsadfsadfasdfasdf23'))
name='alex'
print(hash(name))
print(help(dict)) # 查看帮助信息
# 打印字典的key,value
p = {'name':'alex','age':16}
print(list(p.keys()),list(p.values()))
print(p.items())
print(pow(3,3)) # 3**3
print(pow(3,3,2)) # 3**3%2 #3的3次方然后取余
l=[1,2,3,4]
h = reversed(l) # 返回一个反转的列表迭代器
print(next(h))
print(l)
# slice() # 自定义切片功能
l='hello'
s1=slice(3,5) # 定义切片(不收尾)
s2=slice(1,4,2) # 定义切片(不收尾)指定步长为2
print(l[3:5]) # 直接切片
print(l[s1]) # 使用定义的切片取值
print(l[s2]) # 使用定义的切片取值,步长为2
print(s2.start) # 查看定义的参数 开始位置
print(s2.stop) # 查看定义的参数 结束位置(不收尾)
print(s2.step) # 查看定义的参数 步长
# max min方法 注意!比较的值必须是同一个类型,否则报错
l=[1,3,100,-1,2]
print(max(l)) # 取最大值,从前到后一个一个比较(类型必须一样)(print(min(l))
# 取最小值min,用法一样)
age_dic={'alex_age':18,'wupei_age':20,'zsc_age':100,'lhf_age':30}
print(max(age_dic)) # #默认比较的是字典的key
print(max(age_dic.values()))
print('=======>',list(max(zip(age_dic.values(),age_dic.keys())))) # 默认比较第一个参数
people=[
{'name':'alex','age':1000},
{'name':'wupei','age':10000},
{'name':'yuanhao','age':9000},
{'name':'linhaifeng','age':18},
]
# 终极玩儿法,指定每个元素中比较的内容,从而返回整个满足要求的元素
print(max(people,key=lambda dic:dic['age']))
print(set('hello')) #变成一个集合的方式 鸭子类型转换
print(type("ss")) # 查看数据类型
print(vars()) # 打印当前作用域所有的变量值或者类型,是一个字典。
11.函数闭包
def bibao():
name = "go"
def baobao():
print(name)
return baobao #闭包的效果,这种情况当return了,当前函数bibao没有被释放.
func = bigao()
func()
闭包面试题

补充:import导入方式 :import---调--->sys---调-->import()
import test #test.py 这个写的模块,import不能导入字符串
test.say_hi()
import 'test' #报错
module_name='test'
m=__import__(module_name) #这种方式为导入字符串方式导入模块
m.say_hi()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号