如何为 mdbook pdf 生成书签目录
通过 mdbook 网站保存的 pdf 是没有目录的,本文以 Rust By Example.pdf 为例,分享如何为 mdbook 打入书签目录。
生成本地网页书籍,并保存为 pdf
-
git clone https://github.com/rust-lang/rust-by-example把书籍仓库克隆到本地。 -
根据
README.md安装 mdbook,并运行服务器。此时终端会输出书籍 url,比如Serving on: http://localhost:3000。

-
打开书籍 url,并点击右上角打印图标,把书籍保存为 pdf,这里是
Rust By Example.pdf。

从 pdf 提取所有标题及对应页码
请先参考后面的准备步骤,保存 py 文件并安装工具。
- 运行
pdfxmeta "Rust By Example.pdf" | grep "font.size" | sort | uniq -c | sort -gk 1提取书籍中所有的字体大小。
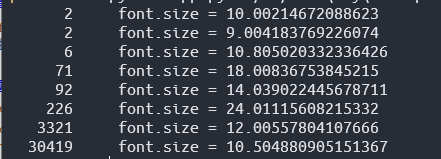
- 新建
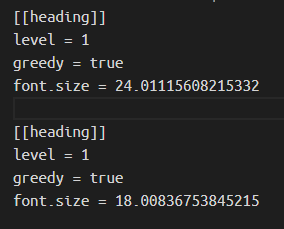
recipe.toml, 把可能为标题的字体大小填到下面代码中的 font.size 中。如果有多个 font.size 要填,每个 font.size 都要复制一组下面的代码。
[[heading]]
level = 1
greedy = true
font.size = 24.01115608215332
示例:
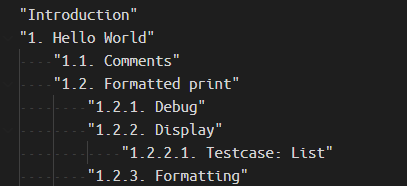
从网页提取所有章节名称
- 使用
python gen_chapter.py > chapter.txt根据网页生成目录。使用时请修改 genbookmark.py 中的 url 为mdbook serve生成的书籍 url。
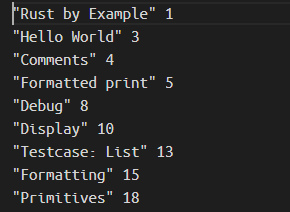
将章节名称与标题页码一一对应
- 运行
pdftocgen "Rust By Example.pdf" < recipe.toml > bookmark.txt提取书籍中所有的标题及对应页码
- 使用
python combine.py chapter.txt bookmark.txt > toc.txt,对应标题与章节。
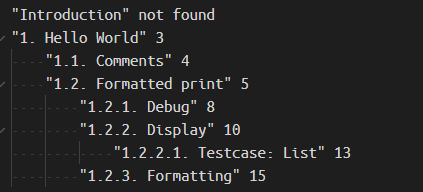
- 检查
toc.txt,如有标明 not_found 的章节,说明没有在bookmark.txt中找到对应标题。可能是因为章节名称和标题名称不一致,或者标题名称提取错误。解决方法:根据bookmark.txt中的标题与页码,手动填写章节页码,比如修复 Introduction:
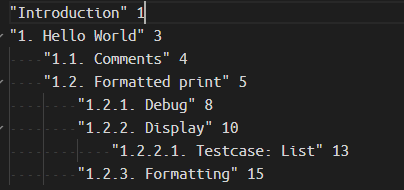
根据对应结果生成目录
- 运行
pdftocio -t toc.txt -o "out.pdf "Rust By Example.pdf",把toc.txt中的章节与页码填入 pdf 中。 - 重命名
out.pdf为你想要的名称。
| 网页版目录 | 生成的 PDF 目录 |
|---|---|
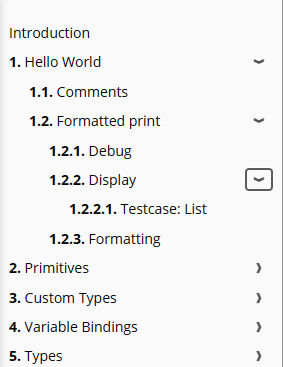 |
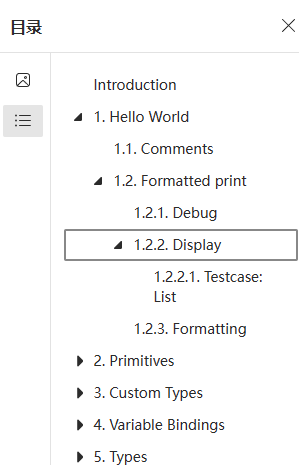 |
准备工作
准备环境
安装 python3,并使用 pip 安装 requests 和 lxml 库。
安装 pdf.tocgen
pip install -U pdf.tocgen,参考 Krasjet/pdf.tocgen: A CLI toolset to generate table of contents for PDF files automatically.
保存如下代码为 gen_chapter.py
import requests
from lxml import etree
url = "http://localhost:3000/"
get = requests.get(url).text
chapter = etree.HTML(get).xpath('//*[@id="sidebar"]/div[1]/ol')[0]
# 子元素中,class 包含 chapter-item 的所有 li
title = './child::li[contains(@class, "chapter-item")]'
# 后面的第一个 li 中,class 不包含 chapter-item 的
child = './following-sibling::li[1][not(contains(@class, "chapter-item"))]'
# a 下面的所有 text,用来提取 strong 和普通 text
text = "string(./a)"
def get_text(ol, level = 0):
chapter_items = ol.xpath(title)
for chapter_item in chapter_items:
print("{}\"{}\"".format(" " * level, chapter_item.xpath(text)))
child_li = chapter_item.xpath(child)
if (child_li):
child_ol = child_li[0].xpath("./ol[1]")
get_text(child_ol[0], level + 1)
get_text(chapter)
保存如下代码为 combine.py
import sys
import csv
chapter_list_file, bookmark_file = sys.argv[1], sys.argv[2]
with open(chapter_list_file, 'r') as c, open(bookmark_file, "r") as b:
chapters = list(c.readlines())
bookmarks = list(b.readlines())
for chapter in chapters:
for bookmark in bookmarks:
chapter_name = list(csv.reader([chapter.strip()], delimiter=' '))[0][0]
chapter_split = chapter_name.split(" ")[1:]
chapter_name = " ".join(chapter_split) if chapter_split else chapter_name
bookmark_name, bookmark_page = list(csv.reader([bookmark.strip()], delimiter=' '))[0]
if bookmark_name in chapter_name:
print(chapter[:-1], bookmark_page)
bookmarks.remove(bookmark)
break
elif chapter_name in bookmark_name:
print(chapter[:-1], bookmark_page)
bookmarks.remove(bookmark)
break
else:
print(chapter[:-1], "not_found")
