
实验19-使用keras完成语音识别

wavs_to_model.py

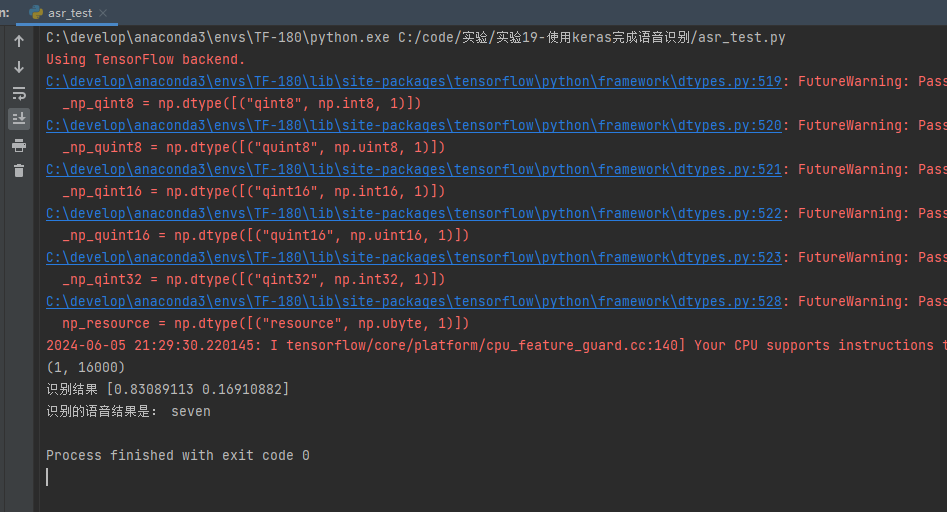
import wave import numpy as np import os import keras from keras.models import Sequential from keras.layers import Dense num_class = 0 # 加载的语音文件有几种类别 labsIndName=[] ## 训练集标签的名字 ["seven","stop"] # 加载数据集 和 标签[并返回标签集的处理结果] def create_datasets(): global num_class # 声明全局变量 wavs=[] # 训练wav文件集 labels=[] # labels 和 testlabels 这里面存的值都是对应标签的下标,下标对应的名字在labsInd中 testwavs=[] # 测试wav文件集 testlabels=[] # 测试集标签 path="./speech_commands" dirs = os.listdir(path) # 获取的是目录列表 for i in dirs: print("开始加载:",i) labsIndName.append(i) # 当前分类进入到标签的名字集 wavs_path=path+"\\"+i testNum=0 # 当前分类进入了测试集的有几个 ,这里暂定每个分类进100个到测试集 files = os.listdir(wavs_path) # 某个目录下文件的列表 for j in files: try: waveData = get_wav_mfcc(wavs_path+"\\"+j) if testNum < 100 : testwavs.append(waveData) testlabels.append(labsIndName.index(i)) testNum+=1 else: wavs.append(waveData) labels.append(labsIndName.index(i)) except: pass num_class = len(labsIndName) # 更新全局变量 wavs=np.array(wavs) labels=np.array(labels) testwavs=np.array(testwavs) testlabels=np.array(testlabels) return (wavs,labels),(testwavs,testlabels) def get_wav_mfcc(wav_path): f = wave.open(wav_path,'rb') params = f.getparams() # print("params:",params) nchannels, sampwidth, framerate, nframes = params[:4] strData = f.readframes(nframes)#读取音频,字符串格式 waveData = np.fromstring(strData,dtype=np.int16)#将字符串转化为int waveData = waveData*1.0/(max(abs(waveData)))#wave幅值归一化 waveData = np.reshape(waveData,[nframes,nchannels]).T f.close() ### 对音频数据进行长度大小的切割,保证每一个的长度都是一样的【因为训练文件全部是1秒钟长度,16000帧的,所以这里需要把每个语音文件的长度处理成一样的】 data = list(np.array(waveData[0])) # print(len(data)) while len(data)>16000: del data[len(waveData[0])-1] del data[0] # print(len(data)) while len(data)<16000: data.append(0) # print(len(data)) data=np.array(data) # 平方之后,开平方,取正数,值的范围在 0-1 之间 data = data ** 2 data = data ** 0.5 return data if __name__ == '__main__': (wavs,labels),(testwavs,testlabels) = create_datasets() print(wavs.shape," ",labels.shape) print(testwavs.shape," ",testlabels.shape) # 标签转换为独热码 labels = keras.utils.to_categorical(labels, num_class) testlabels = keras.utils.to_categorical(testlabels, num_class) print(labels[0]) ## 类似 [1. 0] print(testlabels[0]) ## 类似 [0. 0] print(wavs.shape," ",labels.shape) print(testwavs.shape," ",testlabels.shape) # 构建模型 model = Sequential() model.add(Dense(1024, activation='relu',input_shape=(16000,))) model.add(Dense(512, activation='relu')) model.add(Dense(256, activation='relu')) model.add(Dense(128, activation='relu')) model.add(Dense(num_class, activation='softmax')) # [编译模型] 配置模型,损失函数采用交叉熵,优化采用Adadelta,将识别准确率作为模型评估 model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) # validation_data为验证集 model.fit(wavs, labels, batch_size=124, epochs=10, verbose=1, validation_data=(testwavs, testlabels)) # 开始评估模型效果 # verbose=0为不输出日志信息 score = model.evaluate(testwavs, testlabels, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) # 准确度 model.save('asr_all_model_weights.h5') # 保存训练模型



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人